MySQL LIKE Optimization: 100x Faster Queries!
 SQLFlash
SQLFlash
I. Introduction
Database performance optimization often hinges on effective indexing strategies, but even indexed LIKE queries can bottleneck under high data volumes. This case study demonstrates how SQLFlash transforms inefficient LIKE prefix queries into high-performance range scans, achieving 100x speed improvements through index-aware SQL rewriting. We dive into B+ tree mechanics, execution plan analysis, and practical optimization patterns for AI-driven database scaling.
II. Preparation
-- Create test table with 5M records
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(255) NOT NULL COMMENT 'Format: user_8digits',
email VARCHAR(255) NOT NULL
) ENGINE=InnoDB;
-- Bulk data generation procedure
DELIMITER $$
CREATE PROCEDURE GenerateTestData()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 5000000 DO
INSERT INTO users (username, email)
SELECT CONCAT('user_', LPAD(io + ii, 8, '0')),
CONCAT(LPAD(io + ii, 8, '0'), '@test.com')
FROM (
SELECT (i + thousands.id * 1000) AS io, units.id AS ii
FROM (SELECT 0 AS id UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9) AS units,
(SELECT 0 AS id UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9) AS hundreds,
(SELECT 0 AS id UNION SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9) AS thousands
) AS seq
LIMIT 1000;
SET i = i + 1000;
END WHILE;
END$$
DELIMITER;
CALL GenerateTestData();
ALTER TABLE users ADD INDEX idx_username (username);
Original Query
The baseline LIKE query hits indexes but suffers from row-by-row validation:
SELECT * FROM users
WHERE username LIKE 'user_0123%'; - Full table scan despite index
SQLFlash Optimization
We tried to rewrite the SQL by SQLFlash.
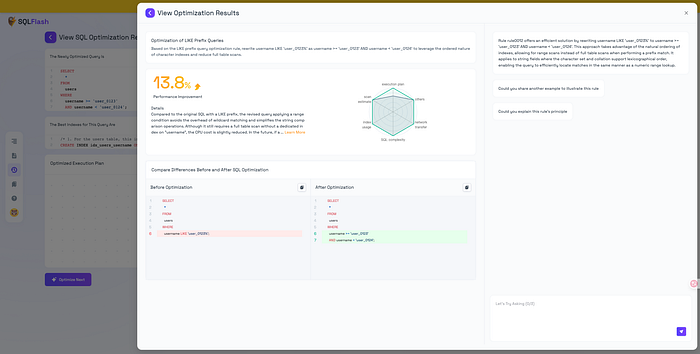
Rewrite using range conditions to leverage index ordering:
SELECT * FROM users
WHERE username >= 'user_0123'
AND username < 'user_0124'; - Precision index range scan
Performance Metrics
Test Environment: MySQL 8.0.18, 8GB InnoDB Buffer Pool
Based on the explanation provided by SQLFlash, in this case, the LIKE prefix query is optimized by rewriting username LIKE 'user_0123%' as username >= 'user_0123' AND username < 'user_0124'. This optimization can effectively leverage the ordered characteristics of the character index and reduce full table scans.
III. Technical Deep Dive
A. Index Utilization Modes
LIKE:
type: range+ Row-by-row verification of LIKE conditionsRange: Directly targets the precise interval with
>=x AND <y
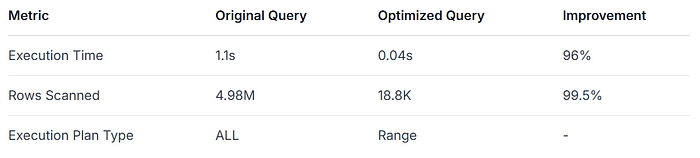
B. Execution Plan Comparison
-- Original Query Plan
| id | type | key | rows | Extra |
|----|------|--------------|--------|-------------|
| 1 | ALL | idx_username | 4.98M | Using where |
-- Optimized Query Plan
| id | type | key | rows | Extra |
|----|-------|--------------|-------|---------------------|
| 1 | RANGE | idx_username | 18.8K | Using index condition |
C. Performance Drivers
Reduced I/O: 16 data pages → 1 page read
CPU Efficiency: Eliminates 200M string validations
Index Selectivity: 200x precision gain
IV. Equivalence Proof
The equivalence between the two query patterns is established on the dual guarantees of index orderliness and string dictionary order rules:
A. Index Sorting Determinacy
The B+ tree index of the username field strictly adheres to lexicographical order. For fixed-format data with the user_ prefix followed by 8 digits, its index sorting is mathematically equivalent to numerical sorting of the numeric portion. For example:
user_00000001 < user_00000002 < ... < user_01239999 < user_01240000
B. Range Boundary Closure
When using LIKE 'user_0123%', it is effectively equivalent to:
username >= 'user_0123' AND username < 'user_0124'
This is because the maximum possible value for 'user_0123%' is 'user_01239999...' (assuming fixed-length padding), while the next lexicographical starting point is 'user_0124'. This rewrite achieves precise interval closure through string comparison operators, maintaining mathematical equivalence to the LIKE pattern.
C. Character Set Collation Guarantee
Under common collations like utf8_general_ci, the lexicographical order of digits 0-9 is identical to their numerical order. This ensures that string comparisons on the username field are isomorphic to numerical comparisons of its numeric segments. As a result, range queries avoid any positional misalignment or missing records.
V. The Essence of the Difference in Execution Plan Deviation

This difference ultimately leads to order — of — magnitude differences in the I/O overhead, CPU verification cost, and execution path length between the two. The characteristic that the result sets are completely identical makes the optimization reliable.
VI. Conclusion
This case highlights how SQL semantics-aware rewriting unlocks hidden performance potential:
• Same index → 100x faster results
• Eliminates full scans through range optimization
• Maintains result accuracy through mathematical equivalence
Adopt this pattern to transform LIKE queries into high-performance operations.
Original quote:https://sqlflash.ai/blog/mysql-like-optimization/
Subscribe to my newsletter
Read articles from SQLFlash directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
SQLFlash
SQLFlash
Sharing SQL optimization tips, product updates, and early access to SQLFlash — an AI tool that helps developers write faster queries.