System design - 2
 Abheeshta P
Abheeshta P
📊 Case Studies: Traffic Pattern Analysis & Infrastructure Scaling
Netflix
Predictive spike handling: Netflix predicts spikes based on scheduled releases (e.g., new season drops).
Pre-scaling: Scales up infrastructure before traffic hits.
Traffic simulation: They imitate traffic using tools to stress-test and validate system capacity.
Architecture: Uses microservices deployed across globally distributed AWS regions with auto-scaling groups and Chaos Engineering to build resilience.
Hotstar
Predictive & reactive scaling for two types of workloads:
Live Streaming Server: Scales aggressively during matches.
Movie Server: Scales down during match time.
Smart shift mechanism:
When users leave the match (drop in live streaming), traffic shifts back to movies.
Requires auto-balancing between live and movie servers to avoid crashes.
Architecture: Typically uses Kubernetes + CDN + auto-scaling clusters to ensure real-time responsiveness.
YouTube
Most complex of all: Handles multiple traffic types (live, VOD, shorts, music) with billions of users.
Forecasting: Uses ML-based traffic forecasting models.
Edge + Core Architecture:
Uses Content Delivery Networks (CDNs) like Google Global Cache.
Load balancing via YouTube Front-End (YFE) and Backend for Frontend (BFF) design.
Combines predictive analytics with real-time monitoring.
Serverless (e.g., AWS Lambda)
"Serverless" means you don’t manage the server — the provider does it for you.
Auto-scales per request: Spins up a function for every incoming call.
Stateless by nature.
Great for micro tasks / event-driven apps.
Challenges:
Cold start delays.
Limited execution duration (e.g., 15 mins on AWS).
Hard to maintain persistent DB connections.
Prone to vendor lock-in due to tightly coupled services.
- Cannot change from AWS since additionally we have to use some other features of the AWS like SQS, API gateway, route 53, S3, cloud watch.
Best for: Lightweight, infrequent, parallelizable tasks.
Serverful (Traditional Approach)
You manage your full server setup (OS, runtime, config).
Scaling is manual or semi-automated.
Issues:
Time-consuming setup.
“Works on my machine” problem common.
"Works on my machine" refers to the common software development issue where code functions correctly on the developer's local computer but fails in other environments, such as testing or production.
Solution: Use VMs or Containers.
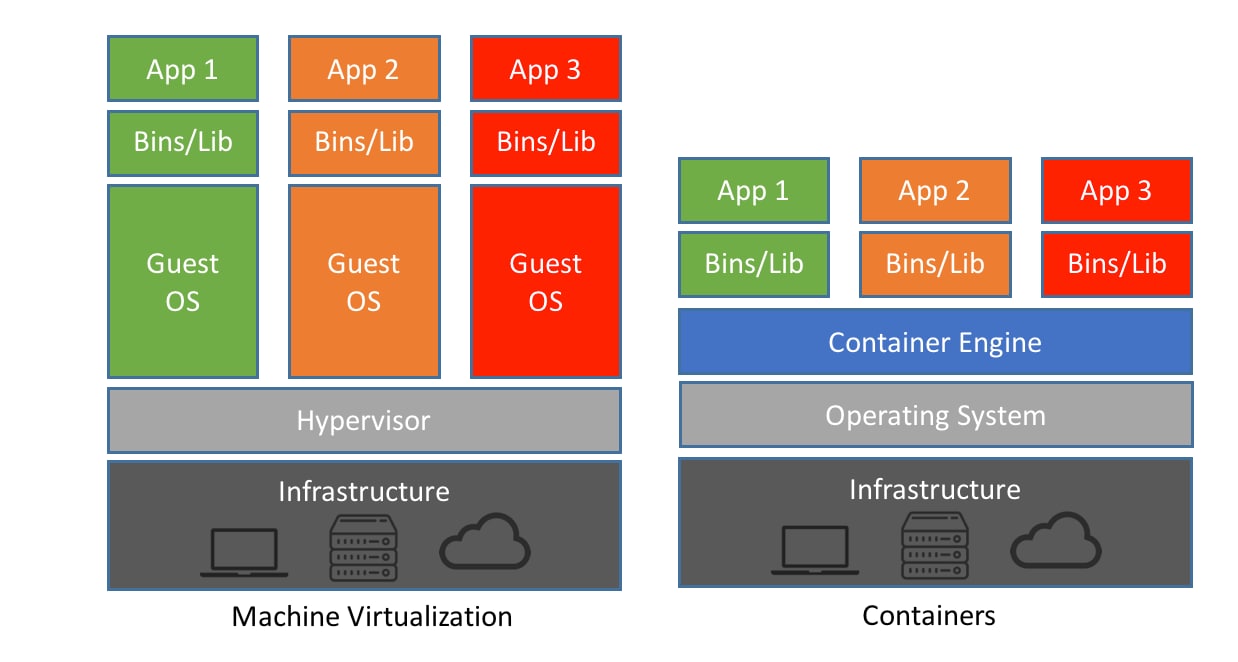
Virtual Machines (VMs)
Full OS virtualization — includes guest OS, libraries, code, dependencies.
Solves environment issues, but comes with:
High resource overhead.
Slower boot times.
Difficult scaling.
Containers (e.g., Docker)
Lightweight alternative to VMs.
Shares the host OS kernel, runs isolated environments.
Can pack multiple containers in one machine efficiently.
Problem: Managing containers at scale is hard (orchestration needed).
Short overview on docker: understanding-docker
Container Orchestration
Automating deployment, scaling, networking & lifecycle of containers.
Needed when you manage thousands of containers.
Google’s solution: Developed Borg internally.
Open-source counterpart: Kubernetes (K8s), developed by same engineers and maintained by CNCF.
Kubernetes Overview
Production-grade container orchestration platform.
Handles:
Auto-scaling
Load balancing
Self-healing
Rolling updates
Built-in reverse proxy (Kube-proxy).
Highly extensible and integrates well with monitoring, logging, CI/CD tools.
Thanks to video by Piyush Garg.
Subscribe to my newsletter
Read articles from Abheeshta P directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Abheeshta P
Abheeshta P
I am a Full-stack dev turning ideas into sleek, functional experiences 🚀. I am passionate about AI, intuitive UI/UX, and crafting user-friendly platforms . I am always curious – from building websites to diving into machine learning and under the hood workings ✨. Next.js, Node.js, MongoDB, and Tailwind are my daily tools. I am here to share dev experiments, lessons learned, and the occasional late-night code breakthroughs. Always evolving, always building.