✍️ “A Beginner’s Guide to PySpark DataFrames with Real Examples”
 Krishna kumar P
Krishna kumar PWhen I first started working with big data, I kept hearing about PySpark DataFrames — fast, distributed, and super powerful. But I also found the learning curve a bit steep.
In this guide, I’ll break down PySpark DataFrames in the simplest way possible using real-world examples I encountered in my role as a data engineer. I am going use Microsoft fabric notebooks for data transformation.
🧠 What Is a DataFrame in PySpark?
A DataFrame is a distributed collection of data organized into named columns, like a table in a database or a spreadsheet.
In PySpark, it’s optimized for parallel processing and can handle huge datasets that won’t fit in memory.
⚙️ Setting Up PySpark in Microsoft Fabric
If you’re using Microsoft Fabric, you’re already inside a notebook environment that supports Spark natively.
You don’t need to set up SparkSession manually. It's already available for you as spark.
Just start writing your code in a notebook inside your Lakehouse workspace.
But in local environments, you can create a session like this:

Creating session
📁 Loading Data into a DataFrame (from Lakehouse)
Use the default Files or Tables folder inside your Lakehouse:
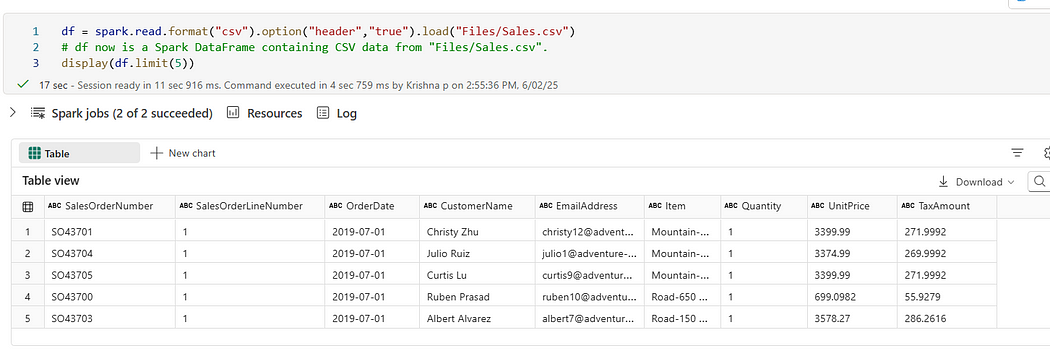
df = spark.read.format(“csv”).option(“header”,”true”).load(“Files/Sales.csv”)
display(df.limit(5))
🔍 Inspecting the DataFrame
df.show(5)
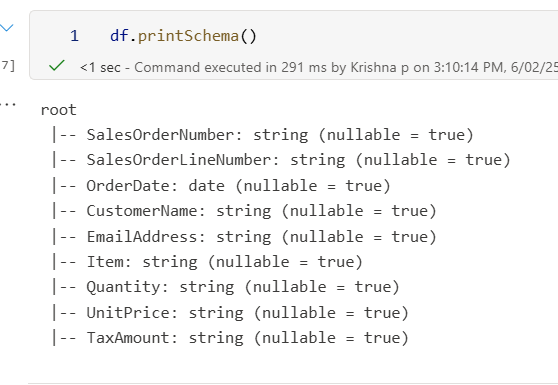
df.printSchema()
df.describe().show()

df.show(5)

df.printSchema()

df.describe().show()
🛠 Common PySpark Transformations
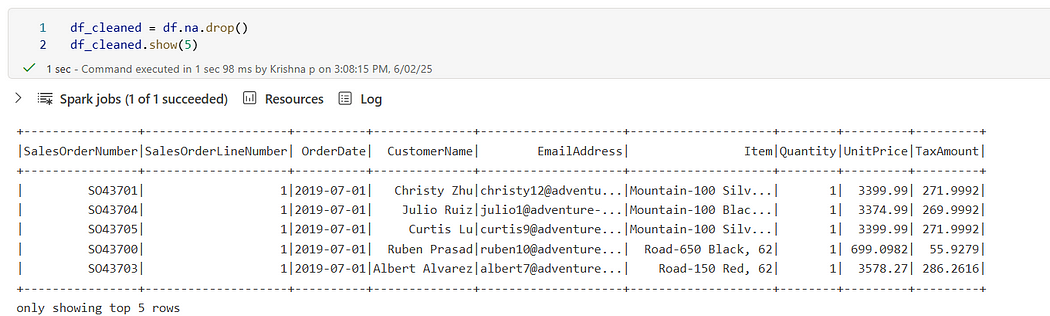
✂️ Drop Nulls
df_cleaned = df.na.drop()
🔤 Trim Strings
from pyspark.sql.functions import trim
df_trimmed = df.select([trim(col).alias(col) for col in df.columns])
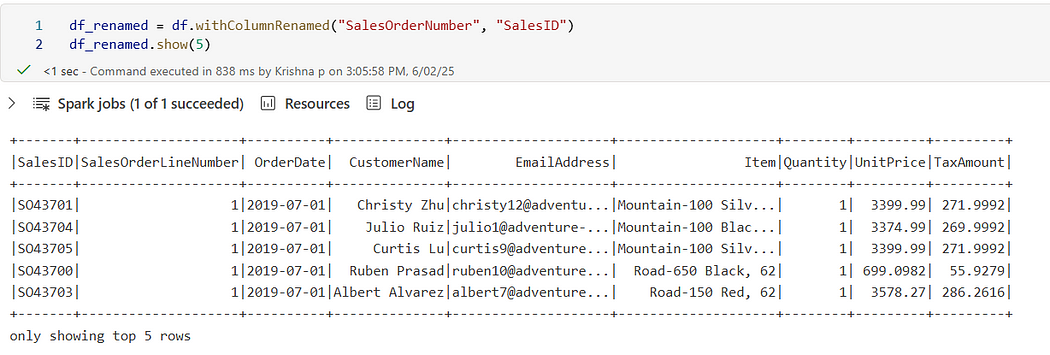
🔁 Rename Columns
📅 Convert to Date
from pyspark.sql.functions import to_date
df = df.withColumn(“OrderDate”, to_date(“OrderDate”, “yyyy-MM-dd”))
df.show(5)
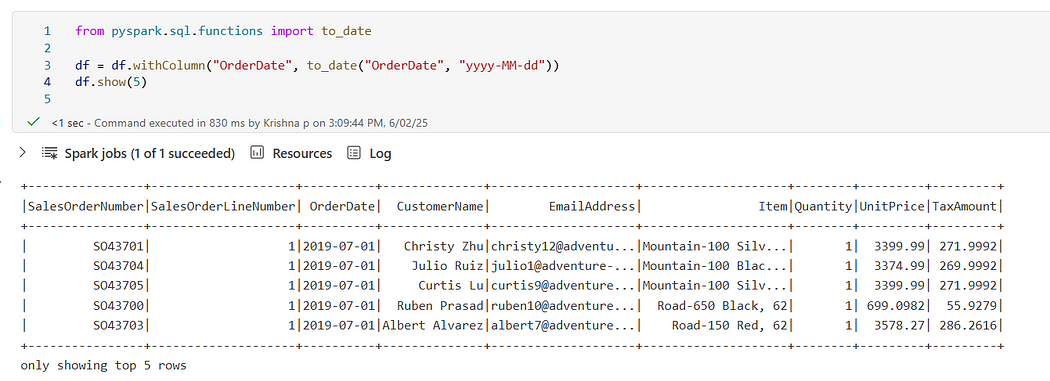
OrderDate converted to date
🔄 Filtering Data
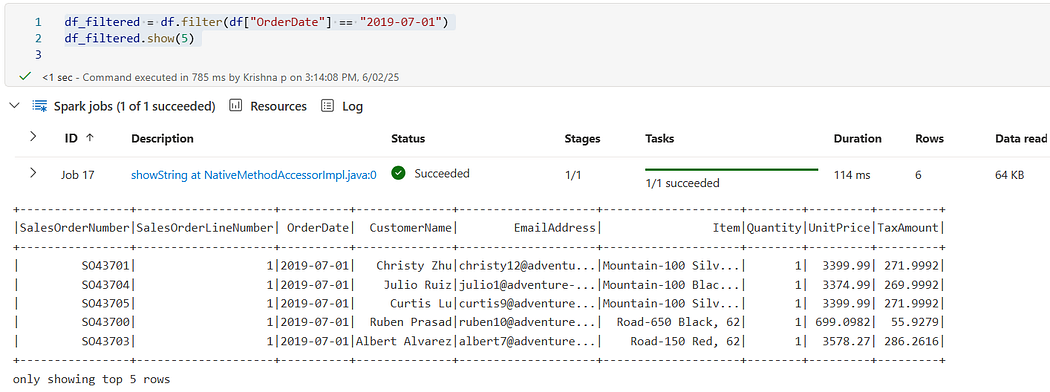
df_filtered = df.filter(df[“OrderDate”] == “2019–07–01”)
df_filtered.show(5)
🔧 Writing Data Back to Lakehouse
To save your cleaned data into the Files area:
df_cleaned.write.mode(“overwrite”).option(“header”, “true”).csv(“Files/cleaned_Sales_data.csv”)
Or you can use .parquet() or .format("delta") if you're using Delta Lake.
🧪 Real Example from My Work
In my work, I had to clean messy CSV files, filter Order date records, and standardize join dates. PySpark helped me:
Trim whitespaces
Convert date formats
Drop Null values on specific columns
Write results to a curated zone
It felt amazing to run that logic on thousands of records in seconds!
✅ Key Takeaways
PySpark is perfect for working with big, messy, distributed datasets
DataFrames are SQL-like and easy to learn
You can chain transformations for a clean pipeline
🙌 Thanks for Reading!
If you’re just starting out, you’re not alone. I’m documenting everything I learn — the wins and the struggles.
👉 Follow me for beginner-friendly PySpark tutorials based on real experience in data engineering.
Feel free leave a comment if you want help setting up your own PySpark notebook!
Subscribe to my newsletter
Read articles from Krishna kumar P directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by