Deep Learning for NLP
 Fatima Jannet
Fatima Jannet
The Basic Perception Model
Neural Network resembles a lot like our neurons in brain, this is called perceptions. Just like our neuron gets inputs and passes out to another neuron in order to make a decision or analyze something, neural network follows the same pattern. It was build to think of it’s own, that's why it was build inspired of human brain structure which is capable to do wonders.
For an in-depth study, visit my blog: Neural Networks
Recurrent Neural Network Overview
Examples of sequences:
Time series data (sales)
Sentences
Audio - sequence of sounds
Car Trajectories - bunch of instruction left right up down
Music - sequence of sounds.
When you will understand Recurrent neural network, you are going to be focused on applying them on sequence-based data.
let’s say, I have a sequence [1,2,3,4,5,6]. Now if i ask you or you ask anybody “Can you predict a similar sequence like this series but shifted one time step into the future?” You’ve prolly notice that it’s an increasing sequence, so one step shifted on ahead would be [2,3,4,5,6,7].
I’ve just described you how RNN works on sequence based data and predicts the upcoming values.
Recall the normal neuron in Feed Forward Network:
input → [Activation function (aggregation of inputs] → output. A RNN neural network works a little bit different. It sends back the output to itself. Output goes back to the input of same neuron.
We can actually unroll this over time, with time represented on the X-axis. We have a specific recurrent neuron where the input at time T minus one gives an output at time T minus one. This output is then passed into the neuron as input at time T, which produces an output at time T. We can take this output and use it as input for the same neuron at time T plus one, and so on. This process is called unrolling the recurrent neuron.
It's important to note that the neuron receives inputs from both a previous time step and the current time step. Each neuron has two sets of inputs. These cells, which function based on input from previous time steps, are also known as memory cells. Recurrent neural networks are flexible with their inputs and outputs, handling both sequences and single vector values.

Cells that use inputs from previous time steps are called memory cells.
RNNs are flexible with inputs and outputs, handling both sequences and single vector values.

We can unroll this whole layer throughout time so that we get input and output at T=0, and pass along with the input and output time plus one.

Since the output of these recurrent neurons at a time step T is based on all the inputs from earlier time steps, you might think it has some kind of memory. This is because we're passing in past information into that recurrent neuron or layer of neurons. The part of this neural network that keeps some state across these time steps is called a memory cell.
LSTMs, GRU, Text Generation
RNN has an issue - it forgets the first input, cause information is lost at each step moving forward through the RNN. So we need some sort of long term memory for our neural network.
The LSTM (Long short term memory) was created to fix this issue. There’s going to be a lot of math here.
This is a LSTM cell.
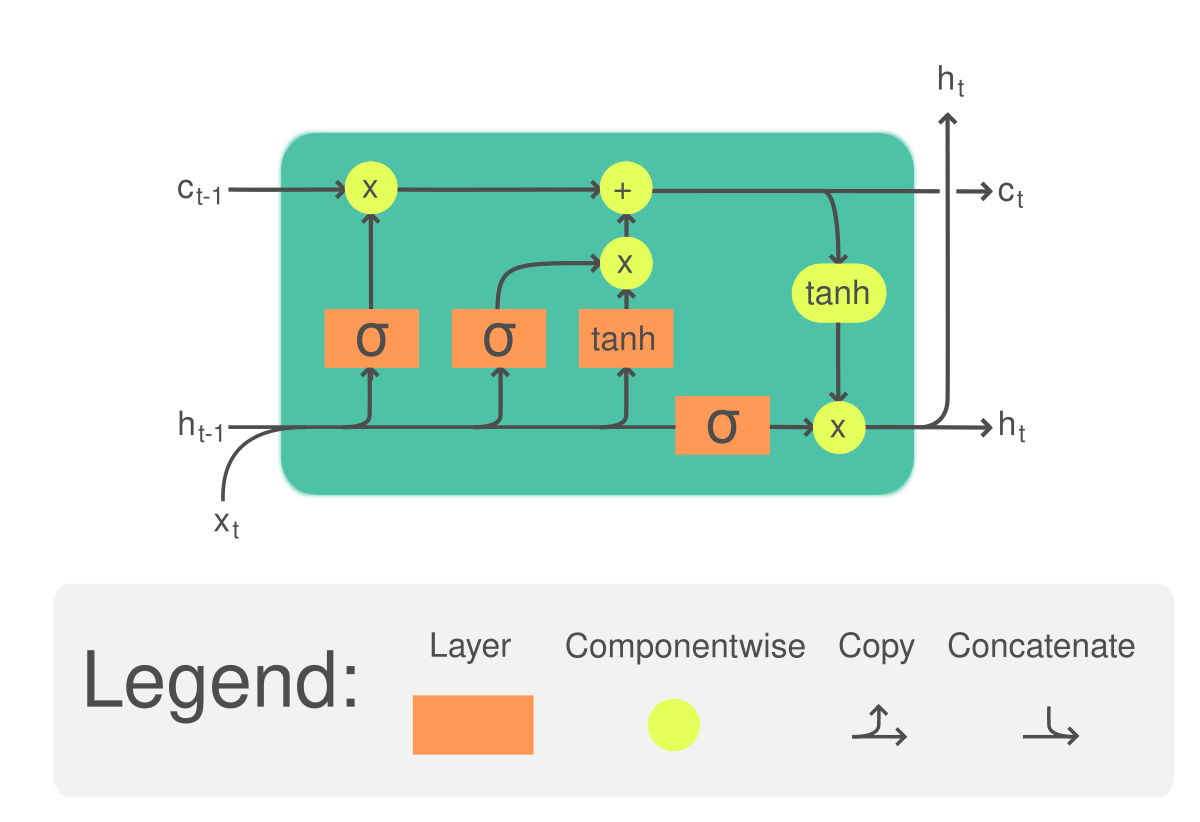
Main idea:
Original normal recurrent input → h(t-1) and x(t). We have another input, called cell state → c(t-1)
Then well get: Output → h(t) and also c(t).
We’ll do this step my step:

Step 1 - Forget gate layers: here we decide what info we gonna forget. We pass h(t-1) and x(t) and they get linear transformed. And as this is a sigmoid layer, the range is going to be 0→1. 1→ Keep it, 0 → get rid of it.
- Use cases: In a language model predicting the next word, a cell state might include the subject's gender to select the correct pronoun. When a new subject appears, you need to forget the old subject's gender. This is a use for a forget gate layer in natural language sequences.
Step 2- Deciding what information to store in the cell state: Here the first layer is a sigmoid layer and the second one is a hyperbolic tangent layer. Sigmoid layer i(t) → is called → input gate layer. Again we pass h(t-1) and x(t) into the sigmoid layer → gets linear transformed → then it goes to the 2nd part (hyperbolic tangent layer). Here we’ll pass h(t-1) into the tangent → ends up creating a vector of what we call ‘new candidate value’ which is the C(t)
Step 3- Combine these two to create an update to the cell state: We want to add the new subject's gender to the cell state and replace the old one we're forgetting. Now, it's time to update the old cell state.
Change the old state, C(t-1), to the new state, C(t), so we can use it for the next cell state, (t+1). We know what to forget and what to keep (candidates); now we just need to do it. Multiply the old state, C(t-1), by f(t). This helps us forget what we want to forget based on the first sigmoid layer. Then, add the input gate, i(t), times the candidate values, C(t). These are the new candidate values, and now they're adjusted by how much we decided to update each state value.
Now, our final decision is what to output with h(t). This output is based on your cell state, but it's just a filtered version. It's quite simple now.
We use h(t-1) and x(t), pass them through a linear transformation into the sigmoid layer, which decides which parts of the cell state to output. Then, we pass the cell state through a hyperbolic tangent, which pushes the values to be between negative one and one. We then multiply it by the output of the sigmoid gate so that we only output the parts we chose. This is shown by the red line.
Again, we take h(t-1) and x(t), do a linear transformation, pass it through the sigmoid, and once we have that output, which we call O(t), the output of T, we multiply it by the hyperbolic tangent of C(t), the current cell state.This gives us h(t).
So that's how an LSTM cell works.

There are honestly a lot of versions of LSTMs. Lots of changes, lots of slight variation.
Another variation of the LSTM cell is called the gated recurrent unit, or GRU. It was introduced in 2014. The GRU simplifies things by combining the forget and input gates into a single update gate. It also merges the cell state and hidden state, along with a few other changes. This makes the model simpler than standard LSTM models. Because of this simplicity, it has become increasingly popular in recent years.

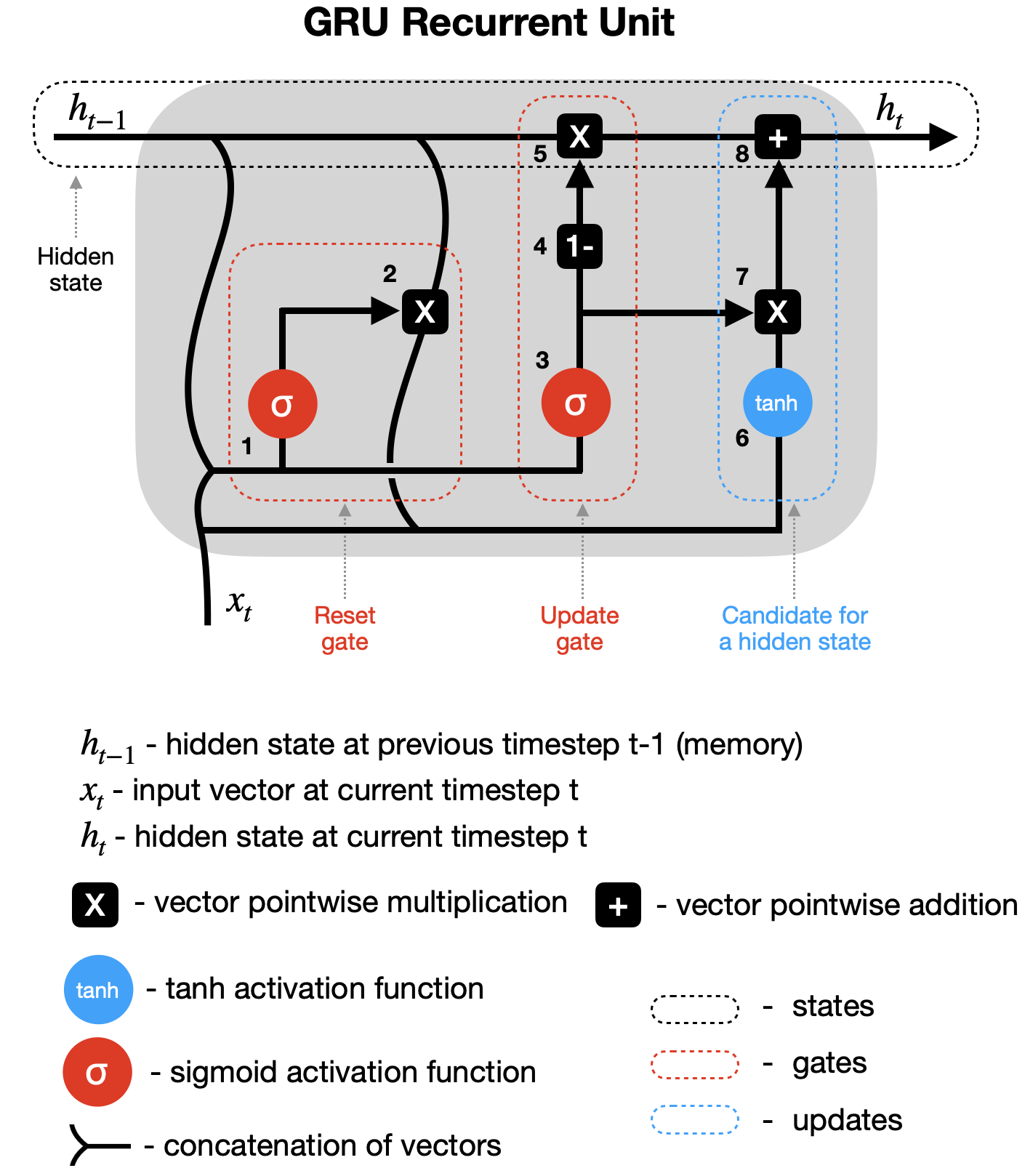
Maybe in few years you’ll see another version. But the main idea is to understand how LSTM works.
Next, we'll learn how to format text data for recurrent neural networks using Keras's built-in tools. Then, we'll explore using LSTM for text generation.
Text Generation with LSTMs with Keras and Python
I won't explain it in this blog post. I have a well-organized notebook that should be sufficient for you. Please access the code resources, files, and datasets from here: https://github.com/fatimajannet/NLP-with-Fatima
Subscribe to my newsletter
Read articles from Fatima Jannet directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by