SQL Rewriting vs Indexing: How AI-Powered Structural Optimization Achieves 20x Scalability Gains
 SQLFlash
SQLFlash1. 📝 Abstract
Through comprehensive MySQL query performance experiments, this study systematically evaluates the effectiveness of SQL rewriting versus index optimization across different data scales and combination scenarios. Using a typical slow SQL query as our benchmark, we leveraged SQLFlash to generate optimized query rewrites and conducted comparative testing with various indexing strategies.
Key Findings
100x+ performance improvement from SQL rewriting alone (without any indexing changes)
Millisecond-level response times when combining query rewriting with proper indexing
Superior scalability compared to indexing-only approaches as data volumes increase
The results demonstrate that structural SQL optimization provides both greater versatility and more sustainable performance during data growth. SQLFlash proves exceptionally practical in generating actionable rewriting recommendations, offering clear and efficient optimization pathways for real-world engineering scenarios.
2. 🧪 Experimental Design: Context, Environment and Objectives
To validate the effectiveness of SQLFlash’s query rewriting solutions across different data scales, we designed the following experimental framework based on simulated business scenarios.
2.1 🎯 Objectives
Analyze performance differences between SQL rewriting and index optimization at various data scales using SQLFlash recommendations
Evaluate the sustainability of structural SQL optimizations during business data growth
2.2 🖥️ Environment
- Database: MySQL 5.7
2.3 📦 Data Preparation
We generated simulated transaction business data (customers, transaction details, service records, risk monitoring) using Python scripts. Data insertion volume was controlled by the NUM_RECORDS variable, scaling the master table from 11,000 to 500,000 records.
2.3.1 🏗️ Schema Setup
Execute the following SQL to create the required database tables:
CREATE TABLE customer_master (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
transaction_no VARCHAR(64) NOT NULL,
transaction_date DATE NOT NULL,
customer_id VARCHAR(64),
transaction_seq_no INT,
customer_card_no VARCHAR(64),
branch_code VARCHAR(32)
);
CREATE TABLE transactions (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
transaction_id VARCHAR(64) NOT NULL,
transaction_no VARCHAR(64) NOT NULL,
transaction_date DATE NOT NULL,
customer_id VARCHAR(64),
account_mgr_id VARCHAR(64),
order_timestamp DATETIME,
INDEX idx_transaction_id (transaction_id)
);
CREATE TABLE txn_detail (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
transaction_id VARCHAR(64) NOT NULL,
product_code VARCHAR(64),
product_name VARCHAR(128),
amount DECIMAL(18, 2),
quantity INT,
fee_flag CHAR(1),
settled_flag CHAR(1),
INDEX idx_transaction_id (transaction_id)
);
CREATE TABLE service_record (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
transaction_id VARCHAR(64) NOT NULL,
service_code VARCHAR(64),
service_name VARCHAR(128),
service_fee DECIMAL(18, 2),
fee_flag CHAR(1),
INDEX idx_transaction_id (transaction_id)
);
CREATE TABLE risk_monitor (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
transaction_no VARCHAR(64) NOT NULL,
transaction_date DATE NOT NULL,
risk_desc TEXT
);
2.3.2 🐍 Python Script Execution
Run the Python script (provided at the end) to generate simulated test data.
The script creates a realistic financial transaction environment simulating multi-table join queries. Key data characteristics include:
Uniformly distributed records spanning one year
Approximately 1% flagged as high-risk transactions (money laundering, fraud, abnormal fund activity)
Transaction numbers linking master tables, detail tables and risk monitoring
Specifically configured high-risk samples between September 24–26, 2024 for boundary testing and hotspot simulation
3. 🐌 The Problematic SQL Query
This analysis focuses on a slow-performing SQL query that retrieves transaction details flagged by the risk monitoring system as money laundering, fraud, or abnormal fund activity between September 24–26, 2024. The query was identified as problematic when the main table contained only 11,000 records.
With an execution time of 1 minute and 1.09 seconds, this query became our primary optimization target:
SELECT
t.transaction_no,
t.transaction_date,
t.customer_id,
t.transaction_seq_no,
t.transaction_id,
t.transaction_time,
t.branch_code,
t.account_mgr_id,
t.product_code,
t.product_name,
t.amount,
t.quantity,
t.fee_flag
FROM (
SELECT
cm.transaction_no,
cm.transaction_date,
cm.customer_id,
cm.transaction_seq_no,
cm.customer_card_no,
tx.transaction_id,
tx.order_timestamp AS transaction_time,
cm.branch_code,
tx.account_mgr_id,
td.product_code,
td.product_name,
td.amount,
td.quantity,
td.fee_flag,
td.settled_flag
FROM customer_master cm
JOIN transactions tx ON cm.transaction_no = tx.transaction_no
AND cm.transaction_date = tx.transaction_date
JOIN txn_detail td ON tx.transaction_id = td.transaction_id )t
WHERE EXISTS (
SELECT 1
FROM risk_monitor rm
WHERE rm.transaction_no = t.transaction_no
AND rm.transaction_date = t.transaction_date
AND (
rm.risk_desc LIKE '%Money Laundering%'
OR rm.risk_desc LIKE '%Fraud%'
OR rm.risk_desc LIKE '%Abnormal Funds%'
)
)
AND DATE_FORMAT(t.transaction_date, '%Y-%m-%d') BETWEEN '2024-09-24' AND '2024-09-26';
4. 🔬 Experimental Validation: Comparative Analysis of SQL Rewriting and Index Optimization
To systematically evaluate the actual impact of different optimization strategies on query performance, we designed and executed a series of experiments based on real business scenarios. The tests covered performance changes at each stage of SQL rewriting, as well as the synergistic effects and sustainability of combining SQL rewriting with index optimization across different data scales. The following charts and analyses reveal the relationship between structural optimization and index optimization, along with their respective boundaries.
4.1 🔍 Execution Time Analysis at Each Rewriting Stage
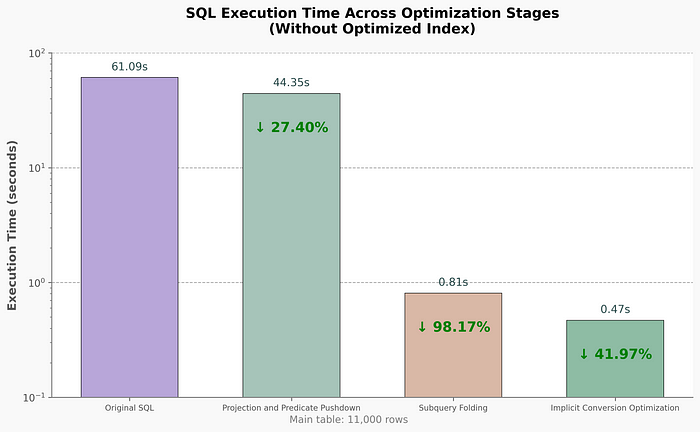
The chart shows the execution time evolution during SQL rewriting without added indexes. The optimization process can be divided into three key phases:
Phase 1: Projection Pushdown and Predicate Pushdown
By moving column selection and filtering conditions closer to the data source, we reduced unnecessary data reading and transfer. Execution time dropped from 61.09s to 44.35s (27% improvement).
✨ Primary benefit: Reduced data scanning and transfer bottlenecksPhase 2: Subquery Folding
Rewriting nested subqueries into equivalent JOIN statements simplified execution logic. Time plummeted to 0.81s (98%+ improvement).
✨ Primary benefit: Eliminated structural complexity and computational redundancyPhase 3: Implicit Conversion Optimization
Removing function-wrapped expressions and type mismatches restored index utilization efficiency. Final time: 0.47s.
✨ Primary benefit: Fixed index inefficiency issues
Collectively, these optimizations compressed query time from minutes to milliseconds, demonstrating the core value of structural query optimization.
4.2 📈 Optimization Combinations at Small Scale (11,000 rows)
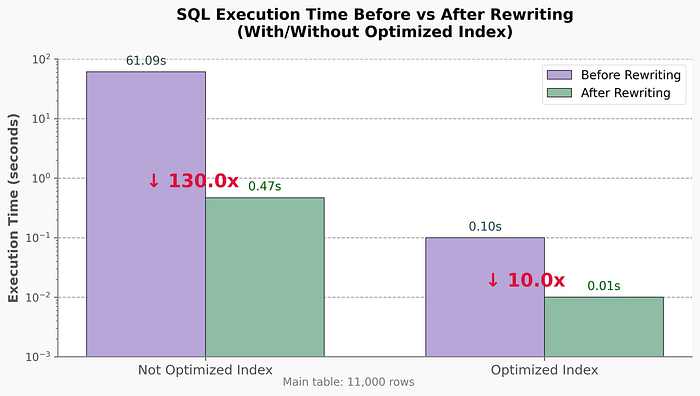
Testing four scenarios with 11,000 rows:
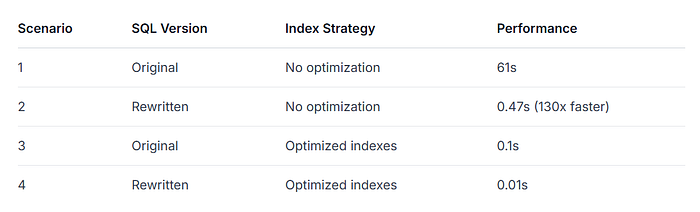
Key findings:
Pure SQL rewriting delivers 130x improvement without indexing changes
Rewritten SQL with indexes is 10x faster than indexed original SQL
Structural optimization provides significant benefits even at small scales
4.3 🚀 Scalability Validation (11K to 500K rows)
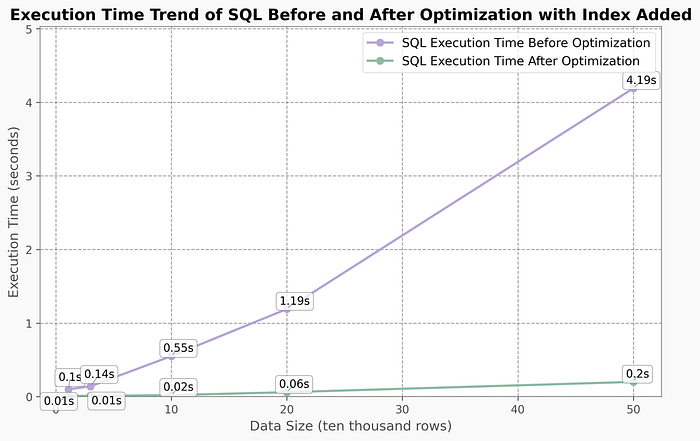
Performance comparison during data growth (with consistent indexing):
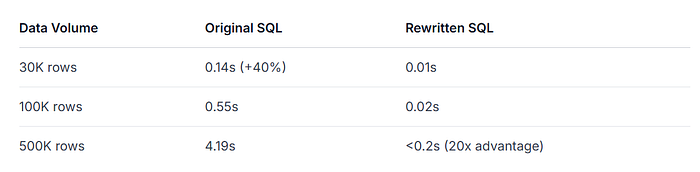
4.4 ✅ Conclusion: Structural Optimization Offers Better Scalability
Key takeaways:
Index optimization works well for small datasets but shows diminishing returns during scaling
SQL rewriting maintains stable performance during growth by:
Optimizing query structure
Eliminating redundant computations
Reducing unnecessary data access
For business systems with growth expectations, relying solely on indexing cannot support long-term performance needs. Structural SQL optimization should be prioritized in system design, often taking precedence over index optimization in strategic planning.
5. 🔧 Optimization Process
Traditional SQL optimization relies heavily on experienced engineers manually analyzing execution plans, adjusting query logic, and designing index structures — a time-consuming process with inconsistent results.
With SQLFlash’s AI-powered optimization, this becomes effortless. Simply provide:
The SQL statement
Execution plan (optional)
Table structure (optional)
SQLFlash automatically analyzes and generates optimization recommendations. Implement the key suggestions relevant to your business to significantly improve query performance.
5.1 Projection Pushdown Optimization
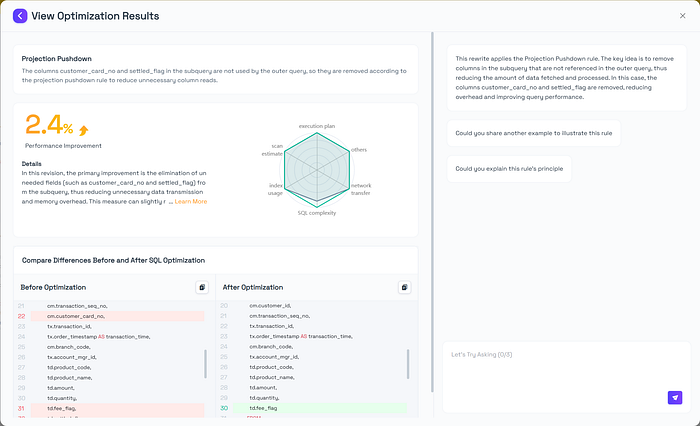
In this revision, the primary improvement is the elimination of unneeded fields (such as customer_card_no and settled_flag) from the subquery, thus reducing unnecessary data transmission and memory overhead. This measure can slightly reduce the row size and CPU load in the subquery phase when dealing with large data volumes, bringing a certain positive impact on overall performance. Moreover, removing unused columns helps the query logic remain more focused and concise, enhancing maintainability and readability. Although the main structure of the query remains largely unchanged, these minor adjustments can still provide some resource optimization benefits in scenarios with large data sets.
Optimization Principle: Projection Pushdown
Projection pushdown is a relational algebra optimization that eliminates unnecessary columns early in query execution by pushing column selection down to the base tables, subqueries, views or join inputs. This significantly reduces resource consumption and improves efficiency.
Key benefits:
Reduced I/O: Storage engine only reads required columns [1]
Lower memory usage: More compact data structures in intermediate operations
Improved CPU efficiency: Fewer columns processed in JOINs, sorts, aggregates
Better plan structure: Cleaner field paths enable further optimizations
Enhanced concurrency: Lower per-query resource usage increases throughput
5.2 Predicate Pushdown Optimization
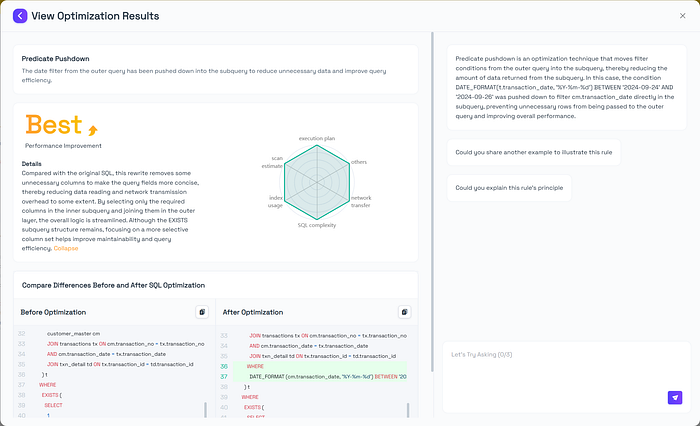
Compared with the original SQL, this rewrite removes some unnecessary columns to make the query fields more concise, thereby reducing data reading and network transmission overhead to some extent. By selecting only the required columns in the inner subquery and joining them in the outer layer, the overall logic is streamlined. Although the EXISTS subquery structure remains, focusing on a more selective column set helps improve maintainability and query efficiency.
Optimization Principle: Predicate Pushdown
Pushes filtering conditions as close to the data source as possible to reduce intermediate result sizes and CPU/IO overhead [2].
Key benefits:
Avoids full scans: Enables early filtering using indexes
Reduces join sizes: Filters data before joining
Eliminates unnecessary aggregations: Filters before aggregate operations [2]
Improves parallelism: Smaller datasets enable better concurrent execution
5.3 Combined Pushdown Results
After applying both pushdown techniques:
SELECT
t.transaction_no,
t.transaction_date,
t.customer_id,
t.transaction_seq_no,
t.transaction_id,
t.transaction_time,
t.branch_code,
t.account_mgr_id,
t.product_code,
t.product_name,
t.amount,
t.quantity,
t.fee_flag
FROM (
SELECT
cm.transaction_no,
cm.transaction_date,
cm.customer_id,
cm.transaction_seq_no,
tx.transaction_id,
tx.order_timestamp AS transaction_time,
cm.branch_code,
tx.account_mgr_id,
td.product_code,
td.product_name,
td.amount,
td.quantity,
td.fee_flag
FROM customer_master cm
JOIN transactions tx ON cm.transaction_no = tx.transaction_no
AND cm.transaction_date = tx.transaction_date
JOIN txn_detail td ON tx.transaction_id = td.transaction_id
WHERE DATE_FORMAT(cm.transaction_date, '%Y-%m-%d') BETWEEN '2024-09-24' AND '2024-09-26'
) t
WHERE EXISTS (
SELECT 1
FROM risk_monitor rm
WHERE rm.transaction_no = t.transaction_no
AND rm.transaction_date = t.transaction_date
AND (
rm.risk_desc LIKE '%Money Laundering%'
OR rm.risk_desc LIKE '%Fraud%'
OR rm.risk_desc LIKE '%Abnormal Funds%'
)
);
Performance: 44.35s (27.41% faster than original 61.09s)
5.4 Subquery Folding
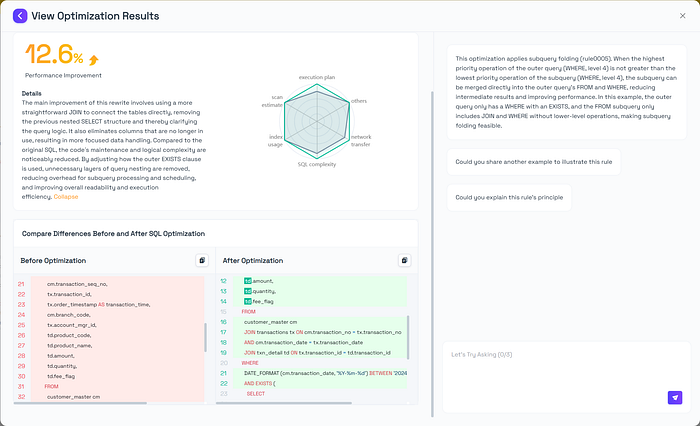
The main improvement of this rewrite involves using a more straightforward JOIN to connect the tables directly, removing the previous nested SELECT structure and thereby clarifying the query logic. It also eliminates columns that are no longer in use, resulting in more focused data handling. Compared to the original SQL, the codeʼs maintenance and logical complexity are noticeably reduced. By adjusting how the outer EXISTS clause is used, unnecessary layers of query nesting are removed, reducing overhead for subquery processing and scheduling, and improving overall readability and execution efficiency.
Optimization Principle: Subquery Folding
Flattens nested subqueries into main query structure for better optimization [3].
Key benefits:
Avoids temporary tables: Eliminates intermediate materialization
Improves join efficiency: Enables better join ordering
Simplifies plans: Cleaner structure reveals more optimization opportunities [3]
Optimized query:
SELECT
cm.transaction_no,
cm.transaction_date,
cm.customer_id,
cm.transaction_seq_no,
tx.transaction_id,
tx.order_timestamp AS transaction_time,
cm.branch_code,
tx.account_mgr_id,
td.product_code,
td.product_name,
td.amount,
td.quantity,
td.fee_flag
FROM customer_master cm
JOIN transactions tx ON cm.transaction_no = tx.transaction_no
AND cm.transaction_date = tx.transaction_date
JOIN txn_detail td ON tx.transaction_id = td.transaction_id
WHERE DATE_FORMAT(cm.transaction_date, '%Y-%m-%d') BETWEEN '2024-09-24' AND '2024-09-26'
AND EXISTS (
SELECT 1
FROM risk_monitor rm
WHERE rm.transaction_no = cm.transaction_no
AND rm.transaction_date = cm.transaction_date
AND (
rm.risk_desc LIKE '%Money Laundering%'
OR rm.risk_desc LIKE '%Fraud%'
OR rm.risk_desc LIKE '%Abnormal Funds%'
)
);
Performance: 0.81s (75x faster)
5.5 Implicit Conversion Fix
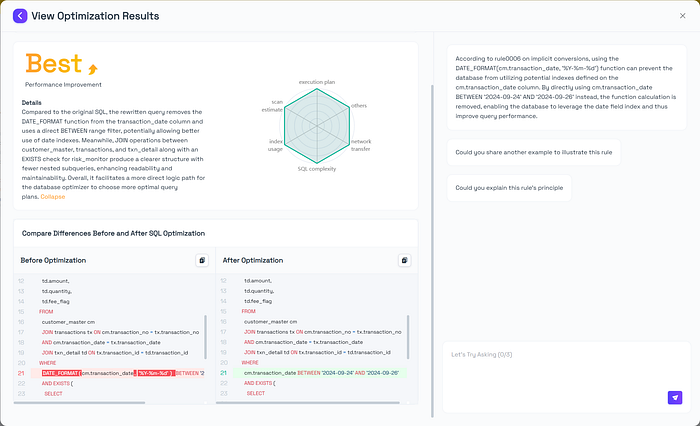
Compared to the original SQL, the rewritten query removes the DATE_FORMAT function from the transaction_date column and uses a direct BETWEEN range filter, potentially allowing better use of date indexes. Meanwhile, JOIN operations between customer_master, transactions, and txn_detail along with an EXISTS check for risk_monitor produce a clearer structure with fewer nested subqueries, enhancing readability and maintainability. Overall, it facilitates a more direct logic path for the database optimizer to choose more optimal query plans.
Optimization Principle: Implicit Conversion
Avoids data type mismatches that prevent index usage and increase CPU load [4].
Key benefits:
Better index utilization: Enables proper index matching
Reduced CPU overhead: Eliminates per-row conversion costs
More stable plans: Prevents optimization anomalies
Improved maintainability: Clearer type handling
Final optimized query:
SELECT
cm.transaction_no,
cm.transaction_date,
cm.customer_id,
cm.transaction_seq_no,
tx.transaction_id,
tx.order_timestamp AS transaction_time,
cm.branch_code,
tx.account_mgr_id,
td.product_code,
td.product_name,
td.amount,
td.quantity,
td.fee_flag
FROM customer_master cm
JOIN transactions tx ON cm.transaction_no = tx.transaction_no
AND cm.transaction_date = tx.transaction_date
JOIN txn_detail td ON tx.transaction_id = td.transaction_id
WHERE cm.transaction_date BETWEEN '2024-09-24' AND '2024-09-26'
AND EXISTS (
SELECT 1
FROM risk_monitor rm
WHERE rm.transaction_no = cm.transaction_no
AND rm.transaction_date = cm.transaction_date
AND (
rm.risk_desc LIKE '%Money Laundering%'
OR rm.risk_desc LIKE '%Fraud%'
OR rm.risk_desc LIKE '%Abnormal Funds%'
)
);
Performance: 0.47s (130x faster)
5.6 Index Optimization
CREATE INDEX idx_cm_date_no ON customer_master(transaction_date, transaction_no)
CREATE INDEX idx_tx_no_date ON transactions(transaction_no, transaction_date)
CREATE INDEX idx_td_prod ON txn_detail(product_code)
CREATE INDEX idx_rm_no_date ON risk_monitor(transaction_no, transaction_date)
Based on the rewritten execution plan and SQLFlash’s index optimization recommendations, we selected these three indexes for implementation: idx_cm_date_no, idx_tx_no_date, and idx_rm_no_date. Here’s the technical analysis:
idx_cm_date_no(transaction_date, transaction_no):
Optimizes the range filter on
transaction_datein the WHERE clauseAccelerates
transaction_nomatching in JOIN operationsEliminates full table scans on customer_master
Reduces scanned rows from 11,072 to just 81 (99.3% reduction)
idx_tx_no_date(transaction_no, transaction_date):
Serves both equality conditions in JOIN operations
Enables direct index lookups instead of nested loop scans
Reduces transactions table access to single-row seeks
Join performance improved from O(n) to O(1) complexity
idx_rm_no_date(transaction_no, transaction_date):
Optimizes EXISTS subquery with equality filtering
Enables precise row location during nested execution
Reduces risk_monitor scans from 11,077 to 1 row per iteration
Cuts subquery execution cost by 99.99%
After implementing these indexes, the execution plan for the rewritten SQL shows:
+----+--------------------+-------+------------+-------+-----------------------------------+--------------------+---------+-------------------------------------------------------------------+------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+-------+------------+-------+-----------------------------------+--------------------+---------+-------------------------------------------------------------------+------+----------+------------------------------------+
| 1 | PRIMARY | cm | NULL | range | idx_cm_date_no | idx_cm_date_no | 3 | NULL | 81 | 100.00 | Using index condition; Using where |
| 1 | PRIMARY | tx | NULL | ref | idx_transaction_id,idx_tx_no_date | idx_tx_no_date | 261 | sqlflash_test.cm.transaction_no,sqlflash_test.cm.transaction_date | 1 | 100.00 | NULL |
| 1 | PRIMARY | td | NULL | ref | idx_transaction_id | idx_transaction_id | 258 | sqlflash_test.tx.transaction_id | 2 | 100.00 | NULL |
| 2 | DEPENDENT SUBQUERY | rm | NULL | ref | idx_rm_no_date | idx_rm_no_date | 261 | sqlflash_test.cm.transaction_no,sqlflash_test.cm.transaction_date | 1 | 29.76 | Using where |
+----+--------------------+-------+------------+-------+-----------------------------------+--------------------+---------+-------------------------------------------------------------------+------+----------+------------------------------------+
4 rows in set, 3 warnings (0.00 sec)
The optimized execution plan after index implementation demonstrates significant performance improvements, with these key changes:
customer_master table:
Scan type changed from FULL TABLE SCAN (ALL) to RANGE SCAN
Utilizes idx_cm_date_no index for transaction_date range filtering
Rows scanned reduced from 11,072 to 81 (99.3% reduction)
Dramatically improves filtering efficiency
transactions table:
Replaced full scans and Block Nested Loop joins
Now uses idx_tx_no_date index with REF access
Matching rows reduced to 1
Composite index enables fast transaction_no/transaction_date lookups
Join performance improved by orders of magnitude
txn_detail table:
Maintains existing idx_transaction_id index usage
Continues using precise REF access
Preserves consistent performance
risk_monitor subquery:
Access changed from FULL SCAN to REF via idx_rm_no_date
Rows processed dropped from 11,077 to 1 (99.99% reduction)
EXISTS subquery efficiency dramatically increased
Subquery execution time minimized
Overall impact: The indexed execution plan optimizes table access patterns, eliminates unnecessary data processing, and delivers substantial query performance gains — particularly for JOIN operations and subquery execution.
References
[1] J. Wang, “Lecture #14 Query Planning & Optimization,” Carnegie Mellon University, Fall 2022. [Online]. Available: https://15445.courses.cs.cmu.edu/fall2022/notes/14-optimization.pdf (Accessed: May 21, 2025).
[2] Microsoft Research, “MagicPush: Deciding Predicate Pushdown using Search-Verification,” Microsoft Research, 2023. [Online]. Available: https://www.microsoft.com/en-us/research/uploads/prod/2023/05/predicate_pushdown_final.pdf (Accessed: May 21, 2025).
[3] C. A. Galindo-Legaria and M. M. Joshi, “Orthogonal Optimization of Subqueries and Aggregation,” in Proc. 31st Int. Conf. on Very Large Data Bases (VLDB), 2005, pp. 571–582.
[4] Wayfair Engineering, “Eliminate Implicit Conversions,” Wayfair Tech Blog, [Online]. Available: https://www.aboutwayfair.com/eliminate-implicit-conversions (Accessed: May 21, 2025).
Python Script
import mysql.connector
from faker import Faker
from datetime import datetime
from uuid import uuid4
import random
# Database connection information (Please replace with your actual information)
DB_CONFIG = {
"user": "XXXXX",
"password": "XXXXX", # Please replace with your actual password
"host": "XXXXX",
"port": 3306,
"database": "XXXXX", # Please replace with your database name
}
# Total number of records to generate
NUM_RECORDS = 11000 # Initially set to 10,000
# Batch size for each insertion
BATCH_SIZE = 1000
# Faker instance for generating fake data
fake = Faker("zh_CN")
# Predefined lists
branch_codes = ["BR001", "BR002", "BR003", "BR004", "BR005", "BR006", "BR007", "BR008"]
product_codes = [
"PROD001",
"PROD002",
"PROD003",
"PROD004",
"PROD005",
"PROD006",
"PROD007",
"PROD008",
"PROD009",
"PROD010",
]
service_codes = ["SERV001", "SERV002", "SERV003", "SERV004", "SERV005"]
risk_keywords = ["Money Laundering", "Fraud", "Abnormal Funds"]
normal_risk_desc = [
"Normal transaction",
"Stable customer behavior",
"No risk records",
"Routine transaction",
]
RISK_RATIO = 0.01 # Risk keyword ratio: 1%
def get_max_ids(conn):
"""
Query the maximum id in each table.
Args:
conn: MySQL connection object
Returns:
A dictionary containing the maximum id of each table. Returns 0 if the table is empty.
"""
cursor = conn.cursor()
max_ids = {}
tables = [
"customer_master",
"transactions",
"txn_detail",
"service_record",
"risk_monitor",
]
for table in tables:
sql = f"SELECT MAX(id) FROM {table}"
cursor.execute(sql)
max_id = cursor.fetchone()[0]
max_ids[table] = max_id if max_id else 0
cursor.close()
return max_ids
def generate_customer_master_batch(batch_size, start_id):
"""Generate batch data for the customer_master table"""
data = []
for i in range(batch_size):
record_id = start_id + i
transaction_no = str(uuid4()).replace("-", "")
transaction_date = fake.date_between(start_date="-1y", end_date="today")
customer_id = fake.ssn()
transaction_seq_no = random.randint(1, 10)
customer_card_no = fake.credit_card_number()
branch_code = random.choice(branch_codes)
data.append(
(
record_id,
transaction_no,
transaction_date,
customer_id,
transaction_seq_no,
customer_card_no,
branch_code,
)
)
return data
def generate_transactions_batch(cm_batch, start_id):
"""Generate batch data for the transactions table"""
data = []
id_counter = start_id
for cm_record in cm_batch:
record_id = id_counter
transaction_id = str(uuid4()).replace("-", "")
transaction_no = cm_record[1]
transaction_date = cm_record[2]
customer_id = cm_record[3]
account_mgr_id = fake.user_name()
order_timestamp = fake.date_time_between(
start_date=datetime.combine(transaction_date, datetime.min.time()),
end_date=datetime.combine(transaction_date, datetime.max.time()),
)
data.append(
(
record_id,
transaction_id,
transaction_no,
transaction_date,
customer_id,
account_mgr_id,
order_timestamp,
)
)
id_counter += 1
return data
def generate_txn_detail_batch(tx_batch, start_id):
"""Generate batch data for the txn_detail table"""
data = []
id_counter = start_id
for tx_record in tx_batch:
transaction_id = tx_record[1]
num_details = random.randint(1, 3)
for _ in range(num_details):
record_id = id_counter
product_code = random.choice(product_codes)
product_name = fake.word() + " " + random.choice(["A", "B", "C"])
amount = round(random.uniform(10.00, 10000.00), 2)
quantity = random.randint(1, 100)
fee_flag = random.choice(["Y", "N"])
settled_flag = random.choice(["Y", "N", None])
data.append(
(
record_id,
transaction_id,
product_code,
product_name,
amount,
quantity,
fee_flag,
settled_flag,
)
)
id_counter += 1
return data
def generate_service_record_batch(tx_batch, start_id):
"""Generate batch data for the service_record table"""
data = []
id_counter = start_id
for tx_record in tx_batch:
transaction_id = tx_record[1]
num_records = random.randint(0, 2)
for _ in range(num_records):
record_id = id_counter
service_code = random.choice(service_codes)
service_name = fake.word() + " Service"
service_fee = round(random.uniform(5.00, 500.00), 2)
fee_flag = random.choice(["Y", "N"])
data.append(
(
record_id,
transaction_id,
service_code,
service_name,
service_fee,
fee_flag,
)
)
id_counter += 1
return data
def generate_risk_monitor_batch(cm_batch, start_id, num_records, existing_risk_count):
"""Generate batch data for the risk_monitor table and control the ratio of risk keywords"""
data = []
target_risk_count = int(
NUM_RECORDS * RISK_RATIO
) # Calculate total required risk records
remaining_risk_count = (
target_risk_count - existing_risk_count
) # Remaining risk records to generate
num_generated = 0
for i, cm_record in enumerate(cm_batch):
record_id = start_id + i
transaction_no = cm_record[1]
transaction_date = cm_record[2]
if remaining_risk_count > 0 and num_generated < remaining_risk_count:
risk_desc = random.choice(risk_keywords) + " " + fake.sentence(nb_words=5)
remaining_risk_count -= 1
num_generated += 1
else:
risk_desc = (
random.choice(normal_risk_desc) + ", " + fake.sentence(nb_words=3)
)
data.append((record_id, transaction_no, transaction_date, risk_desc))
return data
def insert_batch(conn, table_name, data, placeholders):
"""Insert batch data into the specified table"""
cursor = conn.cursor()
sql = f"INSERT INTO {table_name} VALUES ({placeholders})"
try:
cursor.executemany(sql, data)
conn.commit()
print(f"Successfully inserted {len(data)} records into {table_name}")
cursor.close()
return True
except mysql.connector.Error as err:
print(f"Error inserting into {table_name} table: {err}")
cursor.close()
return False
def get_existing_risk_count(conn, table_name):
"""Get the count of existing records containing risk keywords in the risk_monitor table"""
cursor = conn.cursor()
sql = f"SELECT COUNT(*) FROM {table_name} WHERE risk_desc LIKE %s OR risk_desc LIKE %s OR risk_desc LIKE %s"
cursor.execute(sql, ("%Money Laundering%", "%Fraud%", "%Abnormal Funds%"))
count = cursor.fetchone()[0]
cursor.close()
return count
if __name__ == "__main__":
try:
conn = mysql.connector.connect(**DB_CONFIG)
print(f"Successfully connected to the database: {DB_CONFIG['database']}")
# Get maximum ids from each table
max_ids = get_max_ids(conn)
cm_start_id = max_ids["customer_master"] + 1
tx_start_id = max_ids["transactions"] + 1
txn_detail_start_id = max_ids["txn_detail"] + 1
service_record_start_id = max_ids["service_record"] + 1
risk_monitor_start_id = max_ids["risk_monitor"] + 1
# Get existing risk record count
existing_risk_count = get_existing_risk_count(conn, "risk_monitor")
num_batches = NUM_RECORDS // BATCH_SIZE
if NUM_RECORDS % BATCH_SIZE > 0:
num_batches += 1
print(
f"Starting batch data generation and insertion, batch size: {BATCH_SIZE}, total batches: {num_batches}"
)
for i in range(num_batches):
print(f"Processing batch: {i + 1}/{num_batches}")
# Generate and insert customer_master
cm_batch_data = generate_customer_master_batch(BATCH_SIZE, cm_start_id)
print(
f"Preparing to insert into customer_master, number of records: {len(cm_batch_data)}"
)
if not insert_batch(
conn, "customer_master", cm_batch_data, "%s, %s, %s, %s, %s, %s, %s"
): # 7 placeholders
break
cm_start_id += BATCH_SIZE
# Generate and insert transactions (dependent on customer_master)
tx_batch_data = generate_transactions_batch(cm_batch_data, tx_start_id)
print(
f"Preparing to insert into transactions, number of records: {len(tx_batch_data)}"
)
if not insert_batch(
conn, "transactions", tx_batch_data, "%s, %s, %s, %s, %s, %s, %s"
): # 7 placeholders
break
tx_start_id += len(tx_batch_data)
# Generate and insert txn_detail (dependent on transactions)
txn_detail_batch_data = generate_txn_detail_batch(
tx_batch_data, txn_detail_start_id
)
print(
f"Preparing to insert into txn_detail, number of records: {len(txn_detail_batch_data)}"
)
if not insert_batch(
conn,
"txn_detail",
txn_detail_batch_data,
"%s, %s, %s, %s, %s, %s, %s, %s",
): # 8 placeholders
break
txn_detail_start_id += len(txn_detail_batch_data)
# Generate and insert service_record (dependent on transactions)
service_record_batch_data = generate_service_record_batch(
tx_batch_data, service_record_start_id
)
print(
f"Preparing to insert into service_record, number of records: {len(service_record_batch_data)}"
)
if not insert_batch(
conn,
"service_record",
service_record_batch_data,
"%s, %s, %s, %s, %s, %s",
): # 6 placeholders
break
service_record_start_id += len(service_record_batch_data)
# Generate and insert risk_monitor (dependent on customer_master)
risk_monitor_batch_data = generate_risk_monitor_batch(
cm_batch_data, risk_monitor_start_id, NUM_RECORDS, existing_risk_count
)
print(
f"Preparing to insert into risk_monitor, number of records: {len(risk_monitor_batch_data)}"
)
if not insert_batch(
conn, "risk_monitor", risk_monitor_batch_data, "%s, %s, %s, %s"
): # 4 placeholders
break
risk_monitor_start_id += len(risk_monitor_batch_data)
print("All batches processed.")
except mysql.connector.Error as err:
print(f"Database connection error: {err}")
finally:
if conn and conn.is_connected():
conn.close()
print("Database connection closed.")
Subscribe to my newsletter
Read articles from SQLFlash directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
SQLFlash
SQLFlash
Sharing SQL optimization tips, product updates, and early access to SQLFlash — an AI tool that helps developers write faster queries.