What the Heck is Data Build Tool (dbt)
 Ahmad Muhammad
Ahmad Muhammad
When I first started with dbt, I couldn't understand the idea behind running SQL on top of {Jinja} templates or why they would reinvent the wheel when we already have Python, Jinja, and other tools to orchestrate SQL files.
In reality, dbt is designed to offload many low-level complexities, allowing us to focus solely on modeling and understanding business transformations. It also encapsulates best practices, such as: testing, documentation, and version control without worrying about the intricacies of SQL execution across different platforms.
According to dbt documentations, it claims that dbt optimize the engineering workflows by:
Avoid writing boilerplate DML and DDL by managing transactions, dropping tables, and managing schema changes. Write business logic with just a SQL
selectstatement, or a Python DataFrame, that returns the dataset you need, and dbt takes care of materialization.Build up reusable, or modular, data models that can be referenced in subsequent work instead of starting at the raw data with every analysis.
Dramatically reduce the time your queries take to run: Leverage metadata to find long-running models that you want to optimize and use incremental models which dbt makes easy to configure and use.
Write DRYer code by leveraging macros, hooks, and package management.
What is dbt
Data Build Tool (dbt) allows teams to develop and manage code-based transformations in SQL and Python. It centralizes business logic, provides modular analytics components, and offers open-source flexibility.
dbt was developed to encapsulate and partially automate best practices such as testing, documentation, and version control.
├── macros
└── cent_to_dollars.sql
├── models
│ ├── intermediate
│ │ └── finance
│ │ ├── _int_finance__models.yml
│ │ └── int_payments_pivoted_to_orders.sql
│ ├── marts
│ │ ├── finance
│ │ │ ├── _finance__models.yml
│ │ │ ├── orders.sql
│ │ │ └── payments.sql
│ │ └── marketing
│ │ ├── _marketing__models.yml
│ │ └── customers.sql
│ ├── staging
│ │ ├── jaffle_shop
│ │ │ ├── _jaffle_shop__docs.md
│ │ │ ├── _jaffle_shop__models.yml
│ │ │ ├── _jaffle_shop__sources.yml
│ │ │ ├── base
│ │ │ │ ├── base_jaffle_shop__customers.sql
│ │ │ │ └── base_jaffle_shop__deleted_customers.sql
│ │ │ ├── stg_jaffle_shop__customers.sql
│ │ │ └── stg_jaffle_shop__orders.sql
│ │ └── stripe
│ │ ├── _stripe__models.yml
│ │ ├── _stripe__sources.yml
│ │ └── stg_stripe__payments.sql
│ └── utilities
│ └── all_dates.sql
├── packages.yml
├── snapshots
└── tests
└── assert_positive_value_for_total_amount.sql
dbt Models
A dbt model is a Jinja augmented SQL files inside models directory that defines desired transformations -typically a SELECT statement. which will automatically built into a complete regular SQL files that materialize it as:
Table.
View.
Incremental, where each select output will be inserted into the model.
Ephemeral, where your query will be used as a Common Table Expression (CTE), enhancing modularity across your project while keeping your warehouse clean.
Materialized view.
In other words, a dbt model can be:
A table (either standard or incremental)
A view
A materialized view
A Common Table Expression (CTE)
In this example from dbt docs, the customers model depends on stg_customers and stg_orders models to be existed.
-- ./models/customers.sql
{{ config(
materialized="view",
schema="marketing"
) }}
with customers as (
select * from {{ ref('stg_customers') }}
),
orders as (
select * from {{ ref('stg_orders') }}
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
)
select
customers.customer_id,
customers.first_name,
customers.last_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
This code is compiled into a CREATE statement (if the table or view does not exist). In the case of an incremental model, it is compiled into an INSERT statement.
create view analytics.customers as (
with customers as (
select * from analytics.stg_customers
),
orders as (
select * from analytics.stg_orders
),
...
)
...
dbt configuration can be defined either within the SQL file or externally in a .yml file:
name: jaffle_shop
config-version: 2
...
models:
jaffle_shop: # this matches the `name:`` config
+materialized: view # this applies to all models in the current project
marts:
+materialized: table # this applies to all models in the `marts/` directory
marketing:
+schema: marketing # this applies to all models in the `marts/marketing/`` directory
+materialized: view
dbt Modularity
Don't Repeat Yourself (DRY) is a software engineering principle that ensures complexity reduction, maintainability, and systems' scalability.
"every piece of knowledge must have a single, unambiguous, authoritative representation within a system" - Andy Hunt and Dave Thomas, The Pragmatic Programmer
dbt integrates Jinja with SQL code, addressing standard SQL’s limitations.
Jinja
Jinja is a templating language for python developers that is very close to python syntax, it is often used to dynamically generate SQL queries using known string manipulation techniques. in this example, we will use Jinja to generate this query:
-- /models/order_payment_method_amounts.sql
select
order_id,
sum(case when payment_method = 'bank_transfer' then amount end) as bank_transfer_amount,
sum(case when payment_method = 'credit_card' then amount end) as credit_card_amount,
sum(case when payment_method = 'gift_card' then amount end) as gift_card_amount,
sum(amount) as total_amount
from app_data.payments
group by 1
Notice how Jinja have reduced redundancy and maintainability, it's easy to add, remove, and modify your select statement only by modifying payment_methods variable
-- /models/order_payment_method_amounts.sql
{% set payment_methods = ["bank_transfer", "credit_card", "gift_card"] %}
select
order_id,
{% for payment_method in payment_methods %}
sum(case when payment_method = '{{payment_method}}' then amount end) as {{payment_method}}_amount,
{% endfor %}
sum(amount) as total_amount
from app_data.payments
group by 1
Macros
Macros are reusable blocks of code that analogous to functions in other programming languages, they are defined in .sql files.
-- macros/cents_to_dollars.sql
{% macro cents_to_dollars(column_name, scale=2) %}
({{ column_name }} / 100)::numeric(16, {{ scale }})
{% endmacro %}
-- models/stg_payments.sql
select
id as payment_id,
{{ cents_to_dollars('amount') }} as amount_usd,
...
from app_data.payments
-- compiled query
select
id as payment_id,
(amount / 100)::numeric(16, 2) as amount_usd,
...
from app_data.payments
Contracts
For some models, a change in the upstream system's schema is a big deal, as it might break downstream models and systems. In such a case, it's better to define a set of rules that establish the model's shape, including column names, column types, and constraints. This ensures that the model transformations produce the expected model shape.
models:
- name: dim_customers
config:
materialized: table
contract:
enforced: true
columns:
- name: customer_id
data_type: int
constraints:
- type: not_null
- name: customer_name
data_type: string
- name: non_integer
data_type: numeric(38,3)
In incremental models, on_schema_change parameter can be used to determine the action of schema change, available options are: ignore, fail, append_new_columns, sync_all_columns.
{{
config(
materialized='incremental',
unique_key='date_day',
on_schema_change='fail'
)
}}
Model Dependency Management
Model dependencies are defined using the ref and source functions inside the model file, allowing dbt to create a Directed Acyclic Graph (DAG) to determine:
The execution order of models.
The lineage diagram in dbt's auto-generated documentation.
source Function
The source function is used to extract data from source databases. It looks similar to ref, but it is specifically for sources.
Sources are defined in YAML (.yml) files because dbt connects to these sources and ingests data from them.
# ./models/<file name>.yml
version: 2
sources:
- name: jaffle_shop # this is the source name
database: raw
tables:
- name: customers # this is the table name
- name: orders
customers source can be ingested into stg_customers model with this query.
-- ./models/stg_customers.sql
select * from {{ source("jaffle_shop", "customers") }}
ref Function
The ref function is used to reference a model in another model. Models are stacked on each other in all data engineering projects.
-- ./models/customers.sql
with customers as (
select * from {{ ref('stg_customers') }}
),
orders as (
select * from {{ ref('stg_orders') }}
),
...
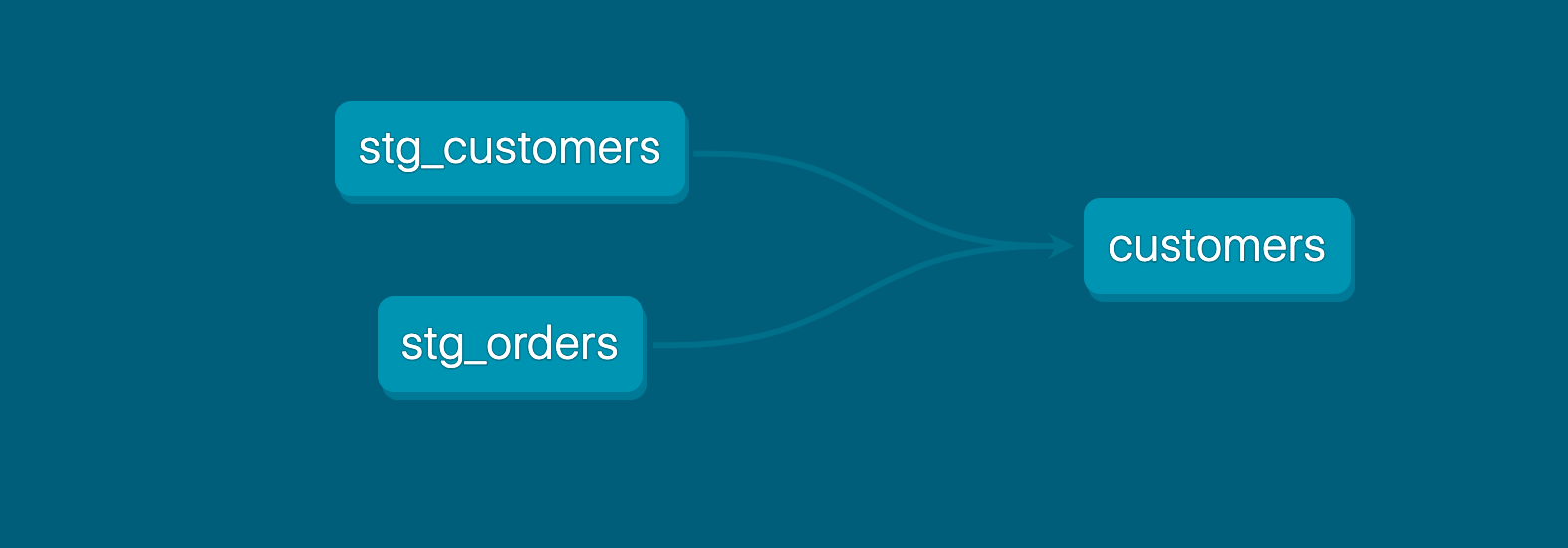
The expected DAG (or lineage diagram) from this model looks like this. This makes it easy to define the execution order of models without any doubts.
source: https://docs.getdbt.com/docs/build/sql-models
Note that dbt quickly identifies circular dependencies in models, thanks
reffunction!
Model Versioning
Data contracts change over time—this could be renaming a column, adding or removing a column, or even changing data types. The idea is to force every downstream consumer to handle these breaking changes as soon as they’re deployed to production. By default, dbt uses the latest version in downstream models, making migration to the new upstream model easier. It’s also possible to reference a specific model version using the ref function, for example:
with dim_customers AS (
SELECT col1, col2, col3 FROM {{ ref('dim_customers', v=1) }} -- choses a specific version. file name: dim_customers_v1.sql
)
,
with dim_orders AS (
SELECT col1, col2, col3 FROM {{ ref('dim_orders') }} -- choses the latest version, file name: dim_orders_v<X>.sql .. X is an integer represents version number
)
...
Some changes like adding a column, or fixing calculation bugs don't require creating a new model, other breaking changes like column removal, column renaming, or changing datatypes do require model versioning.
Creating Model Version
inside a YML file inside models directory, write down your models specifications, note how contract enforcing option is marked as true . Note that file names must be versioned, like: dim_customers_v1.sql, and dim_customers_v2.sql
models:
- name: dim_customers
latest_version: 1
# declare the versions, and fully specify them
versions:
- v: 2
config:
materialized: table
contract: {enforced: true}
columns:
- name: customer_id
description: This is the primary key
data_type: int
# no country_name column
- v: 1
config:
materialized: table
contract: {enforced: true}
columns:
- name: customer_id
description: This is the primary key
data_type: int
- name: country_name
description: Where this customer lives
data_type: varchar
Tests
dbt makes it damn simple to ensure your data models are doing what they're supposed to by letting you integrate tests right into your workflow. Whether you lean on built-in schema tests or craft your own custom ones, these tests enforce data quality and catch anomalies early in the transformation process.
Singular Data Test
The easiest way to write a data test is to simply create a SQL query that returns records breaking your rules. We call these "singular" tests—one-off assertions aimed at a single purpose. For example:
-- tests/assert_total_payment_amount_is_positive.sql
-- Refunds have a negative amount, so total amount should always be >= 0.
-- Return records where total_amount < 0 to fail the test.
select
order_id,
sum(amount) as total_amount
from {{ ref('fct_payments') }}
group by 1
having total_amount < 0
Generic Data Test
A generic data test is defined in a special test block (just like a macro). Once set up, you can reference it by name in your .yml files for models, columns, sources, snapshots, and seeds. dbt comes with four built-in generic tests—and you should definitely take advantage of them!
{% test only_letters(model, column_name) %}
select *
from {{ model }}
where {{ column_name }} !~ '^[A-Za-z]+$'
{% endtest %}
Applying previous custom tests to the schema
# models/schema.yml
version: 2
models:
- name: fct_payments
columns:
- name: customer_name
tests:
- only_letters
- name: email
tests:
- not_null
.
.
.
Built-in Tests
Out of the box, dbt includes four generic data tests: unique, not_null, accepted_values, and relationships. Here’s how you can integrate them into your project:
version: 2
models:
- name: orders
columns:
- name: order_id
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'returned']
- name: customer_id
tests:
- relationships:
to: ref('customers')
field: id
Normally, a data test query calculates failures on the fly. If you set the optional --store-failures flag or use the store_failures / store_failures_as configs, dbt will first save the test query results to a table in your database, then query that table to count the number of failures.
# dbt_project.yml
data_tests:
+store_failures: true
References
Subscribe to my newsletter
Read articles from Ahmad Muhammad directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ahmad Muhammad
Ahmad Muhammad
I’m Ahmad Muhammad, a data engineer applying mathematics and software principles to solve real-world problems using data. I consider myself a tool-agnostic engineer. Theory comes first. Implementation is usually the easy part. I believe that theory and abstract science should always come first, and implementation is often the easiest part. This is especially true with many data solution companies creating tools with great user experiences to attract the community's attention.