How RAG Enhances Context with Large Language Models
 Vasantha Ragavan
Vasantha Ragavan
RAG, or Retrieval-Augmented Generation, is a method used by some AI tools to improve the quality and relevance of the output generated with information fetched from specific and relevant data sources.
The Necessity of Retrieval-Augmented Generation (RAG)
Consider a scenario where an organization intends to use a Large Language Model (LLM). The initial phase involves pretraining the model to execute specific tasks effectively. If the organization requires the integration of real-time data, the model necessitates frequent fine-tuning to maintain accuracy and relevance, which can be resource-intensive. Additionally, if the organization demands outputs derived from a particular data source, the model must be adapted to generate contextually accurate information rather than producing arbitrary or erroneous content. To tackle these challenges, the implementation of Retrieval-Augmented Generation (RAG) becomes essential.
Ideal Workflow of RAG
When dealing with a data source like a PDF or a database, the information is converted into a suitable format, such as text or embeddings, and then fed into the system prompt of the LLM. This process enables user interaction with the system and is known as retrieval-augmented generation (RAG). However, processing all the data simultaneously using RAG is challenging due to the token limit, known as the context window, which restricts the amount of information a model can retain at once. Many data sources exceed this limit, leading to increased token usage as the LLM processes every piece of text in the PDF or database instead of efficiently retrieving only the necessary information.Consequently, loading everything into memory can lead to:
Fitting issues
The model hallucinating inputs and missing essential information
Inefficiency and increased costs
The RAG Solution

Start with a large collection of text or documents.
Divide the text into smaller segments, a process called chunking (like breaking a book into 50 digestible pages).
Feed these segments into a retrieval system, humorously called “Magic Code,” along with the user’s query.
The system acts like an intelligent search engine, comparing the user’s question with all segments to find the most relevant ones.
Merge the selected relevant segments with the original query.
Send this combined information to a language model.
The model uses the query and context to generate a final, precise answer.
RAG ensures that responses are coherent and factually accurate by basing them on retrieved data.
Step-by-Step Breakdown
Smarter Retrieval, Better Answers
let us see what happens inside the MAGIC CODE
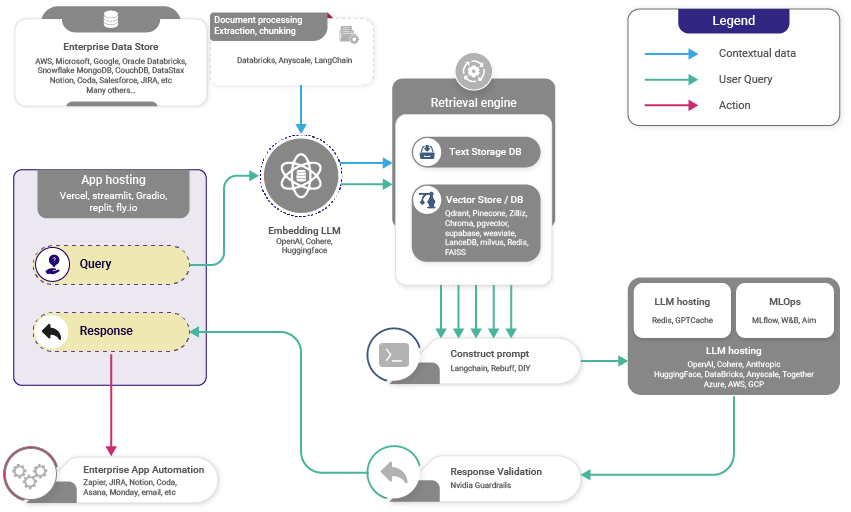
The process consists of two main phases. In the Ingestion Phase, an internal dataset is transformed into vector representations and stored in a vector database. This setup facilitates efficient retrieval based on semantic similarity. In the Retrieval Phase, a user query is converted into a vector, and the system searches the vector database for semantically similar segments. These relevant segments are combined with the query to create an expanded prompt, which the language model processes to generate a context-aware and accurate response.
Ingestion Phase
- Vector Database Creation: The process begins by transforming an internal dataset into vector representations, which are then stored in a vector database or any preferred database system. This step is crucial because it enables the efficient retrieval of relevant information based on semantic similarity. By converting data into vectors, the system can quickly compare and find similarities between different pieces of information, making it easier to access the most pertinent data when needed.
Retrieval Phase
User Input: A user initiates the process by submitting a query in natural language, seeking an answer or completion to their question. This query serves as the starting point for the retrieval process. The system interprets the user's input and prepares to find the most relevant information that can provide a comprehensive and accurate response.
Information Retrieval: The retrieval system plays a critical role by scanning the vector database to locate segments that are semantically similar to the user's query. The user's query is also converted into a vector to facilitate this comparison (similarity search). This step is essential as it ensures that the most relevant pieces of information are selected, which significantly enhances the model's ability to understand and respond accurately to the query.
Combining Data: Once the relevant data segments are identified from the database, they are combined with the user's original query to create an expanded prompt. This combination provides the language model with a richer and more detailed context to work with. By integrating additional information, the model gains a better understanding of the query, which helps in generating a more precise and informed response.
Generating Text: The expanded prompt, now enriched with additional context, is fed into the language model. The model processes this information to generate a final response that is both context-aware and accurate. This ensures that the output is not only relevant to the user's query but also informed by the retrieved data, providing a comprehensive and well-rounded answer. The entire process is designed to maximize the coherence and factual accuracy of the responses by grounding them in the data retrieved from the vector database.
Summary
The article discusses Retrieval-Augmented Generation (RAG), a method used to enhance the context and relevance of outputs generated by Large Language Models (LLMs). It highlights the necessity of RAG in scenarios where real-time data integration and contextually accurate information from specific data sources are required. The article outlines the ideal RAG process, which involves converting data into a suitable format, chunking it, and using a retrieval system to find relevant segments. These segments are combined with the user's query to generate precise answers. The process is divided into two main phases: the Ingestion Phase, where data is transformed into vector representations and stored in a vector database, and the Retrieval Phase, where user queries are matched with semantically similar data to create an expanded prompt for the language model. This approach ensures coherent and factually accurate responses by grounding them in retrieved data.
Subscribe to my newsletter
Read articles from Vasantha Ragavan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by