Step-by-Step: Build Your First RAG Chatbot Fast
 Kabir Arora
Kabir AroraTable of contents
- The RAG Solution: Why Context Is Everything
- How RAG Works: The Complete Workflow
- Types of RAG: From Simple to Enterprise-Scale
- Naive RAG: The Quick Start Approach
- Advanced RAG: Production-Ready Intelligence
- Modular RAG: Enterprise-Scale Architecture
- Implementing your first RAG Application
- The Future of RAG: Trends and Opportunities
Picture this: You’re sitting in an exam hall, faced with a complex question about machine learning algorithms. You have two choices. First, you could rely solely on your general knowledge — the concepts you’ve absorbed over time but might be fuzzy on the details. You’ll probably get partial credit, but your answer lacks the depth and specific examples that earn top marks.
Alternatively, you could have studied from the prescribed textbooks, research papers, and lecture notes specific to this course. With this targeted preparation, you can provide precise definitions, cite specific studies, and give concrete examples that demonstrate mastery. The difference? The teacher recognizes the depth and accuracy, rewarding you with full marks and high satisfaction

This exact scenario plays out millions of times daily in the AI world, where Large Language Models (LLMs) face the same dilemma. Traditional LLMs operate like students relying only on general knowledge — they provide responses based on their vast but static training data, often resulting in generic or outdated answers that lack the specificity users need. This is where Retrieval-Augmented Generation (RAG) transforms the game, acting as the “prescribed textbooks” that enable AI to deliver precise, source-backed responses that satisfy both accuracy and relevance requirements.
The RAG Solution: Why Context Is Everything
RAG represents a fundamental shift in how AI systems approach knowledge retrieval and response generation. Unlike traditional LLMs that generate responses purely from pre-trained parameters, RAG systems dynamically incorporate external knowledge sources during the generation process, creating responses that are both contextually relevant and factually grounded. This architectural innovation addresses the core limitations that have plagued AI applications: hallucinations, outdated information, and lack of domain-specific knowledge.
The power of RAG lies in its ability to bridge the gap between general AI capabilities and specific informational needs. By implementing a retrieval layer that searches through curated knowledge bases, RAG systems ensure that every response is informed by the most relevant and current information available. This approach has proven particularly valuable for AI startups, where 73.34% of enterprise RAG implementations are now happening in large organizations, demonstrating its critical role in production-ready AI applications 3.
How RAG Works: The Complete Workflow
Understanding RAG’s architecture requires breaking down its three core components: retrieval, augmentation, and generation. The retrieval component searches external knowledge bases to find information relevant to user queries, typically using vector embeddings to match semantic similarity between queries and stored documents. The augmentation phase combines retrieved information with the original query, creating enriched context that guides the generation process. Finally, the generation component uses this augmented prompt to produce responses that are both contextually appropriate and factually grounded.

The technical implementation of RAG involves several sophisticated processes that work together seamlessly. First, documents are processed through text splitters that break large texts into manageable chunks, typically 1000–2000 characters with 200-character overlaps to preserve context. These chunks are then converted into high-dimensional vector embeddings using models like “all-MiniLM-L6-v2” or OpenAI’s text-embedding-005, capturing the semantic meaning of the content. The embeddings are stored in specialized vector databases such as Pinecone, Weaviate, or ChromaDB, which enable fast similarity searches.
When users submit queries, the system converts their questions into the same vector space and performs similarity searches to identify the most relevant document chunks. The retrieved information is then combined with the original query using carefully crafted prompts that instruct the LLM on how to utilize the provided context. This process ensures that responses are grounded in specific, verifiable information rather than relying solely on the model’s training data.
Types of RAG: From Simple to Enterprise-Scale
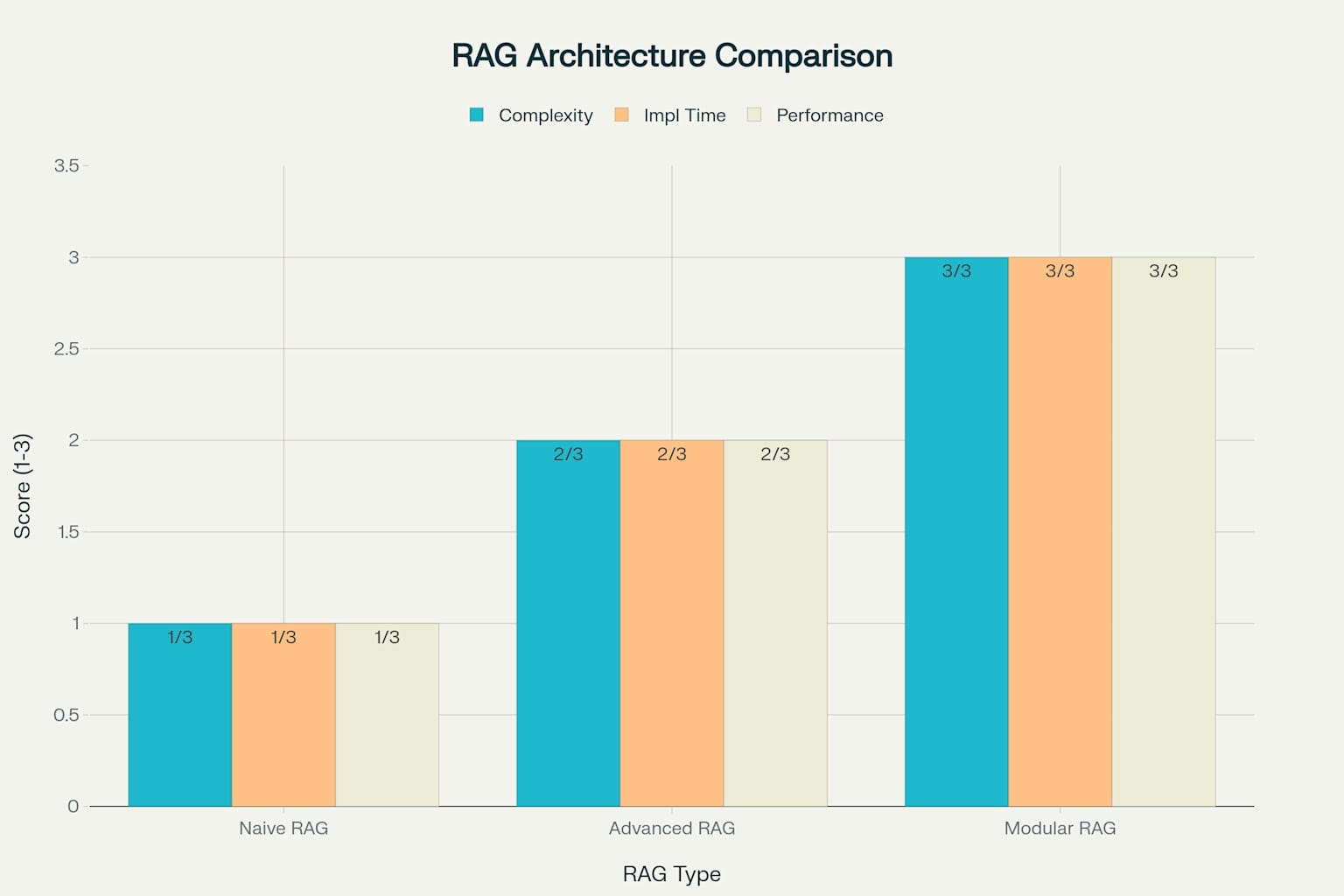
The evolution of RAG has produced three distinct architectural approaches, each suited for different use cases and complexity requirements . Understanding these variants helps developers choose the right implementation strategy for their specific needs and constraints .
Naive RAG: The Quick Start Approach
Naive RAG represents the foundational implementation that follows a straightforward pipeline: retrieve, concatenate, and generate. This approach works well for prototyping and simple use cases where the knowledge base is relatively static and queries are straightforward. Implementation typically requires only days of development time, making it ideal for getting started with RAG concepts or building proof-of-concept applications.
The simplicity of Naive RAG comes with trade-offs in accuracy and sophistication. Since it lacks advanced filtering mechanisms or query optimization, retrieved documents may include irrelevant information that can dilute response quality. However, this approach excels in scenarios like FAQ systems or customer support bots where the scope of information is limited and well-defined.
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.schema import Document
def naive_rag_query(query, raw_texts, openai_api_key=None):
"""
Simple RAG implementation:
- Embed documents
- Retrieve relevant ones
- Use OpenAI LLM to answer with context
"""
# Step 1: Wrap raw texts as Document objects
documents = [Document(page_content=text) for text in raw_texts]
# Step 2: Create embeddings and vectorstore
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
vectorstore = FAISS.from_documents(documents, embeddings)
# Step 3: Retrieve top-k relevant docs
relevant_docs = vectorstore.similarity_search(query, k=3)
# Step 4: Compose context and prompt
context = "\n".join([doc.page_content for doc in relevant_docs])
prompt = f"Context:\n{context}\n\nQuestion: {query}\nAnswer:"
# Step 5: Generate response using OpenAI
llm = OpenAI(temperature=0, openai_api_key=openai_api_key)
response = llm(prompt)
return response
# ✅ Usage
if __name__ == "__main__":
query = "What is deep learning?"
docs = [
"Deep learning is a subset of machine learning focused on neural networks.",
"Neural networks consist of layers that learn representations of data.",
"It is especially useful for image, audio, and natural language tasks."
]
# NOTE: Replace with your actual API key or set as env variable
api_key = "sk-..." # Or: os.environ["OPENAI_API_KEY"]
answer = naive_rag_query(query, docs, openai_api_key=api_key)
print("Answer:", answer)
Advanced RAG: Production-Ready Intelligence
Advanced RAG implementations incorporate sophisticated techniques like query optimization, document re-ranking, and contextual compression to significantly improve response quality. These systems use hybrid retrieval approaches that combine semantic search with keyword matching, ensuring better coverage across different query types. Implementation typically takes weeks but delivers the high accuracy and relevance required for production systems.
The key innovations in Advanced RAG include pre-retrieval query expansion, where the system enhances user queries to improve retrieval effectiveness. Post-retrieval processes like contextual compression filter out irrelevant information and re-rank documents based on multiple scoring algorithms. This multi-stage approach results in responses that are not only accurate but also highly relevant to the specific context of user queries.
Advanced RAG systems also incorporate feedback mechanisms that continuously improve performance based on user interactions and query patterns. This adaptive capability makes them particularly valuable for enterprise applications where accuracy requirements are stringent and user satisfaction directly impacts business outcomes.
# Advanced RAG Example - With Re-ranking and Optimization
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
def advanced_rag_query(query, vectorstore):
"""Advanced RAG: Query optimization + Re-ranking + Context compression"""
# Step 1: Query preprocessing and expansion
query_expander = LLMChainExtractor.from_llm(OpenAI())
expanded_query = query_expander.expand_query(query)
# Step 2: Hybrid retrieval (semantic + keyword)
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
# Step 3: Contextual compression and re-ranking
compressor = LLMChainExtractor.from_llm(OpenAI())
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
# Step 4: Retrieve and rank
compressed_docs = compression_retriever.get_relevant_documents(expanded_query)
# Step 5: Generate with optimized context
context = "\n".join([doc.page_content for doc in compressed_docs[:3]])
prompt = f"""Based on the following context, provide a comprehensive answer:
Context: {context}
Question: {query}
Please provide a detailed answer with specific examples:"""
llm = OpenAI(temperature=0.1)
response = llm(prompt)
return {
"answer": response,
"sources": [doc.metadata for doc in compressed_docs],
"confidence_score": calculate_confidence(response, compressed_docs)
}
Modular RAG: Enterprise-Scale Architecture
Modular RAG represents the most sophisticated approach, breaking the retrieval and generation processes into specialized, independently optimizable components. This architecture enables organizations to customize each module for specific requirements while maintaining overall system coherence. The complexity requires months of development but delivers optimal performance for large-scale deployments and research applications.
The modular approach allows for advanced features like multi-agent systems, where different specialized modules handle different aspects of the retrieval and generation process. Organizations can implement custom routing logic that directs queries to the most appropriate processing pipelines based on query type, domain, or user context. This flexibility makes Modular RAG ideal for enterprise environments with diverse use cases and complex integration requirements.
The orchestration layer in Modular RAG systems manages the entire workflow, deciding when retrieval is needed and how different modules should interact. This architectural sophistication enables features like real-time data integration, multi-modal content processing, and personalized response generation that adapt to individual user preferences and requirements.
Implementing your first RAG Application
import openai
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
from langchain.schema import Document
class SimpleRAG:
def __init__(self, openai_api_key):
openai.api_key = openai_api_key # Set the key globally
self.embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
self.llm = OpenAI(temperature=0)
self.vectorstore = None
self.qa_chain = None
def prepare_documents(self, text_documents):
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
)
docs = [Document(page_content=text) for text in text_documents]
splits = text_splitter.split_documents(docs)
self.vectorstore = Chroma.from_documents(
documents=splits, embedding=self.embeddings
)
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
retriever=self.vectorstore.as_retriever(search_kwargs={"k": 3})
)
return self
def query(self, question):
result = self.qa_chain({"query": question})
return result["result"]
The Future of RAG: Trends and Opportunities
The RAG landscape continues evolving rapidly, with several emerging trends reshaping how organizations implement and deploy these systems. Real-time RAG capabilities enable dynamic data retrieval from live feeds, improving accuracy and relevance for time-sensitive applications. Multimodal RAG systems that process text, images, and audio together open new possibilities for comprehensive content understanding and generation.
Personalized RAG represents another significant trend, where systems adapt to individual user preferences and behavior patterns through advanced fine-tuning techniques. On-device RAG processing addresses privacy concerns while reducing latency, enabling applications that process sensitive data locally without compromising performance. These developments position RAG as a foundational technology for the next generation of AI applications.
The market demand for RAG expertise continues growing, with AI startups increasingly seeking developer advocates who understand both technical implementation and business applications. This trend creates significant opportunities for developers who master RAG technologies and can effectively communicate their value to diverse audiences. The combination of technical depth and communication skills makes RAG expertise particularly valuable for DevRel roles in the expanding AI startup ecosystem
Subscribe to my newsletter
Read articles from Kabir Arora directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by