🚀 Build Your Own Document-Aware AI Assistant using RAG, Qdrant & OpenAI
 SAQUIB HASNAIN
SAQUIB HASNAIN🌍 The Sad Reality of LLMs
Large Language Models (LLMs) like GPT-3/4 or Gemini are amazing but they come with a big limitation:
❌ They only know things they were trained on nothing after that.
Which means:
They don’t know about recent events
They can’t read your private PDFs or company data
They guess (hallucinate) when unsure — and that’s risky!
So, what’s the solution? 🤔
🔧 First Attempt: Fine-Tuning
Fine-tuning means re-training the model on your own data so it understands your domain better.
Sounds good, but… here’s the catch:
💸 It’s expensive (requires GPUs)
🕐 It’s time-consuming
❌ Not flexible (change in data = retrain again)
🤯 Can make the model forget general knowledge
✅ Smarter Alternative: RAG (Retrieval-Augmented Generation)
RAG avoids all of that. It simply means:
📄 “Store your data somewhere and let the LLM fetch and answer based on it in real-time.”
In simple words:
You give the model just the right data when needed
No fine-tuning required
It stays flexible and fast
- fast
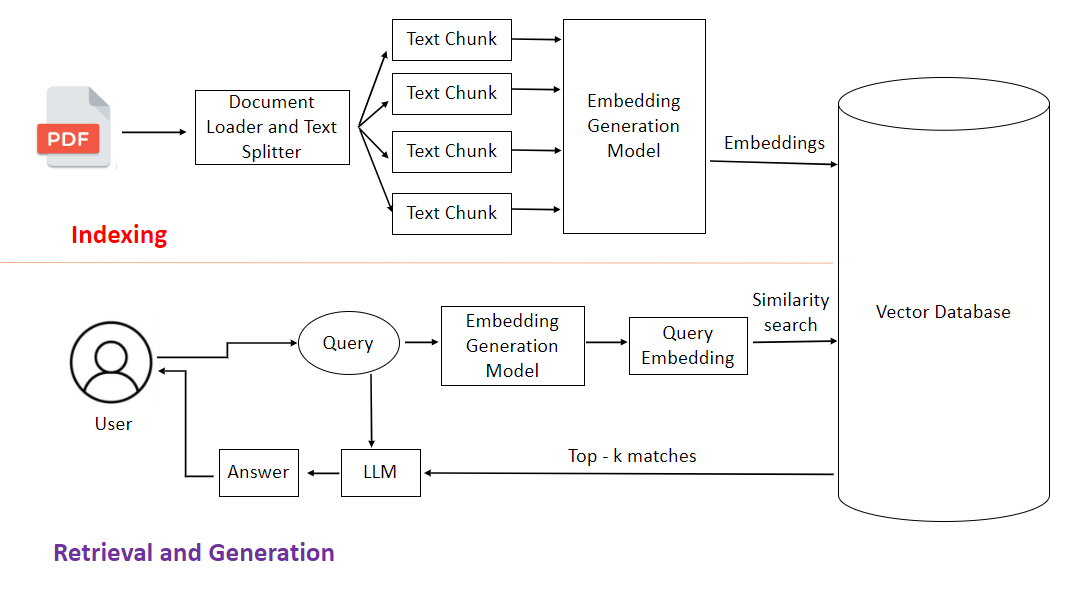
💡 How Does RAG Work?
Split your documents into smaller chunks (pages/paragraphs)
Convert chunks into vectors using OpenAI embeddings
Store those vectors in a Vector Database like Qdrant
When user asks something:
Convert question into a vector
Search the DB for similar chunks
Pass them to GPT for answering
Boom 💥 » Your LLM now understands your documents!
🔨 Let's Build It Step-by-Step
We'll create a real system that:
Loads a PDF
Indexes it into Qdrant
Starts a chatbot that answers based on that PDF
🧱 1. Docker Setup for Qdrant
Create a docker-compose.yml file like this:
services:
vector-db:
image: qdrant/qdrant
ports:
- "6333:6333"
Then run:
docker-compose up -d
✅ Qdrant is now running at http://localhost:6333
📥 2. Index Your PDF into Vector Store (index.py)
from dotenv import load_dotenv
from pathlib import Path
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_qdrant import QdrantVectorStore
# Load your OpenAI key
load_dotenv()
# Load your PDF
pdf_path = Path(__file__).parent / "nodejs.pdf"
loader = PyPDFLoader(file_path=pdf_path)
docs = loader.load()
# Split into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=400)
split_docs = text_splitter.split_documents(docs)
# Convert to vectors using OpenAI embeddings
embedding_model = OpenAIEmbeddings(model="text-embedding-3-large")
# Store vectors in Qdrant
vector_store = QdrantVectorStore.from_documents(
documents=split_docs,
embedding=embedding_model,
collection_name="learning_vectors",
url="http://localhost:6333",
)
print("✅ Indexing of documents completed!")
✅ This script:
Loads your
nodejs.pdfSplits it
Converts each chunk into vectors
Stores in Qdrant (vector DB)
💬 3. Start a Smart Chatbot (chat.py)
from dotenv import load_dotenv
from langchain_qdrant import QdrantVectorStore
from langchain_openai import OpenAIEmbeddings
from openai import OpenAI
load_dotenv()
client = OpenAI()
# Load embedding model
embedding_model = OpenAIEmbeddings(model="text-embedding-3-large")
# Load your Qdrant collection
vector_db = QdrantVectorStore.from_existing_collection(
url="http://localhost:6333",
collection_name="learning_vectors",
embedding=embedding_model
)
message_history = []
print("🤖: Ask your questions from the document (type 'exit' to quit)\n")
while True:
user_input = input("> ").strip()
if user_input.lower() in ["exit", "quit"]:
print("🤖: Goodbye!")
break
# Step 1: Semantic Search
search_results = vector_db.similarity_search(query=user_input)
context = "\n\n\n".join([
f"Page Content: {r.page_content}\nPage Number: {r.metadata['page_label']}\nFile Location: {r.metadata['source']}"
for r in search_results
])
# Step 2: Prepare prompt for GPT
system_prompt = f"""
You are a helpful AI assistant that answers user queries based only on the context below,
which is retrieved from a PDF file. Always guide the user by suggesting the relevant page number.
Context:
{context}
"""
messages = [{"role": "system", "content": system_prompt}] + message_history + [
{"role": "user", "content": user_input}
]
# Step 3: Ask GPT-4
response = client.chat.completions.create(
model="gpt-4.1",
messages=messages
)
reply = response.choices[0].message.content.strip()
print(f"\n🤖: {reply}\n")
# Update chat history
message_history.append({"role": "user", "content": user_input})
message_history.append({"role": "assistant", "content": reply})
✅ This script:
Loads your indexed vectors
Waits for user queries
Retrieves relevant text
Sends it to GPT-4 with context
Replies like a smart assistant (with page info!)
🧪 Sample Output
🤖: Ask your questions from the document (type 'exit' to quit)
> How does Node.js handle asynchronous operations?
🤖: According to Page 4 of the document, Node.js uses an event-driven architecture with a non-blocking I/O model...
🎁 What You’ve Learned:
Why fine-tuning is not always practical
What is RAG (Retrieval-Augmented Generation)
How to chunk + vectorize your PDF
How to store and search using Qdrant
How to build an actual chatbot on top of your own data
This is how modern RAG systems work under the hood and you just built one 💪
If you liked this blog, follow me on Hashnode for more AI/LLM deep dives 🚀
Subscribe to my newsletter
Read articles from SAQUIB HASNAIN directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by