The Chef’s Secrets: The Story behind ExamCooker
 ExamCooker
ExamCooker
Isn’t there something deeply invigorating about seeing an idea go from a messy whiteboard sketch to a widely-used working website? Well, Rome wasn’t built in a day. No one talks about the painful journey in between…the hours spent debugging, learning tech you’ve never heard of and figuring out how to turn ‘just another website’ into something people rely on. That’s what this blog is about: the experience of building, learning and sometimes getting it hilariously wrong!
It all started when Sunny, our senior, came up with this relatable idea that instantly clicked with everyone. A platform for past year papers and notes. The maintainers built on this and shaped it into one of the projects for last summer’s ACM project cycle that we would learn from. And that, kids, is the origin story of ExamCooker™ (unofficial trademark pending, courtesy of our favourite Bengali).

Initially, we were all equally clueless. That’s when our project maintainers, Supratim, Eshita, Nitesh and Kairav, stepped in. They didn’t dictate what ExamCooker should be. Instead, they left the brainstorming to us–what features we wanted, what problems to solve and what the platform should feel like for a lazy student using it at 2 AM before an exam.
Learning and building happened simultaneously. One minute we were hunched over VS Code, and the next we’d be on a Gmeet with Kairav, patiently guiding us through NextJS and breaking down concepts we barely understood. But we’ll save the emotional rollercoaster for later. First, let’s talk about what we were actually building.
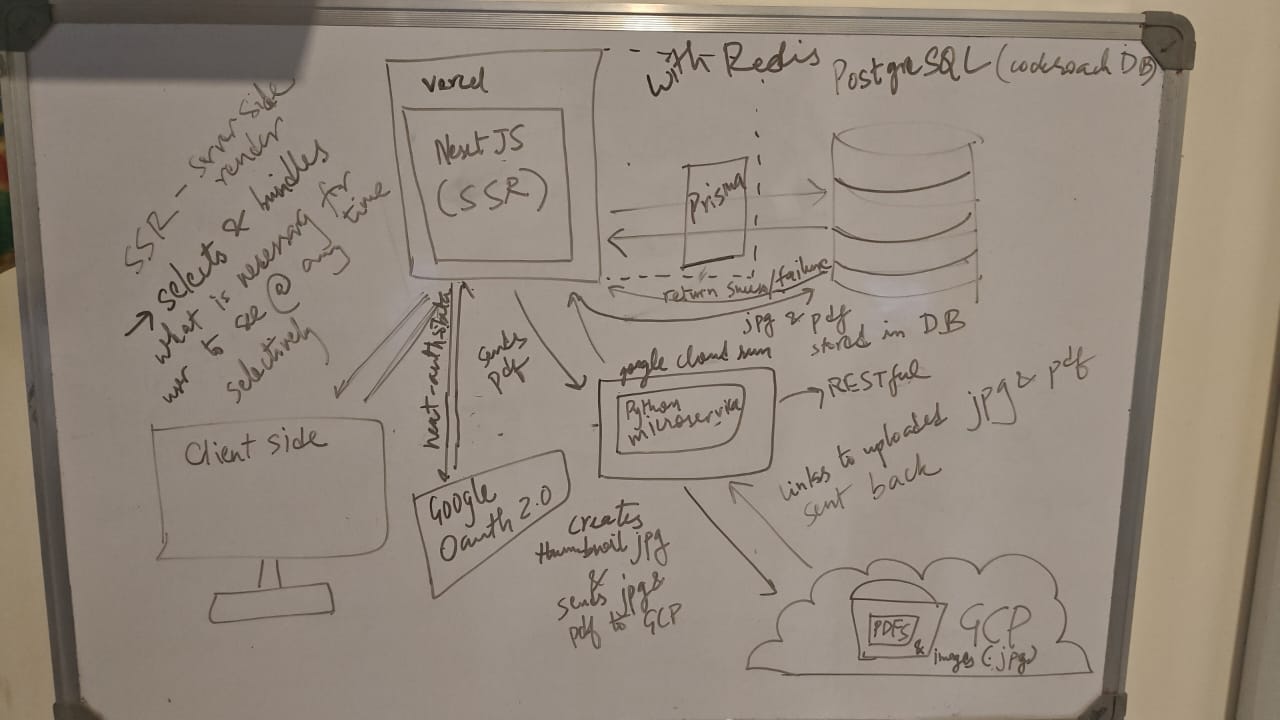
At its core, ExamCooker is a one-stop web application for exam resources, from notes and past papers to student forums, built by ACM-VIT for the students of VIT Vellore. Let’s walk through how everything comes together. What each part of the system does, how data travels from the user’s screen to our backend and database and how we keep things scalable, reliable, and easy to maintain. It wasn’t all smooth sailing, but every decision had a reason (and sometimes a lesson attached).
High-Level Architecture Overview
At a high level, ExamCooker follows a classic client-server model with a decoupled backend service and cloud-first architecture. Every key component in ExamCooker plays a pivotal role.
Time to enter dev mode because we’re going to dive into the details so that the next time you upload a paper, you’ll know exactly what’s happening in the background. And also to brag about the tech we do at ACM!

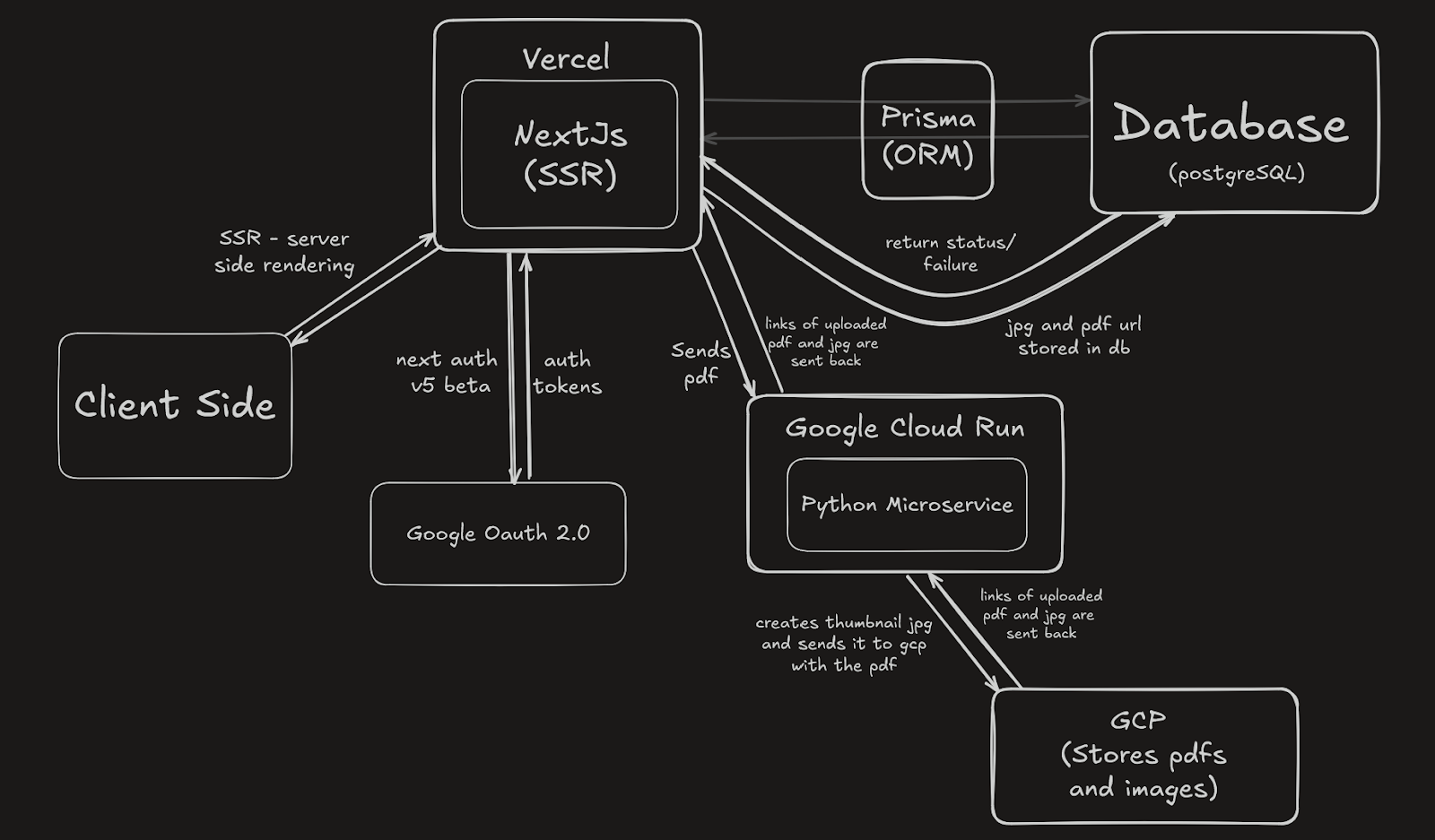
Frontend: Next.js on Vercel (with Server-Side Rendering)
The user interface is powered by Next.js (on top of React) and styled with Tailwind CSS for that clean, modern look. It's deployed on Vercel, which handles the scaling magic whenever traffic spikes (like the night before an exam). Server-Side Rendering (SSR) means pages are rendered on the server, so users get lightning-fast load times and content that Google bots can read (hello, SEO). We chose SSR to ensure that even dynamic content like exam resources or forum posts loads quickly. Vercel’s platform automatically handles scaling the Next.js serverless functions, so as traffic increases, more instances can render pages in parallel.
Once the page loads, it becomes an interactive React app, no page reloads, just smooth client-side routing. Take Instagram for instance. You can like a post, comment or scroll through profiles without the whole page refreshing. That’s the kind of seamless experience we aimed for. We also made use of Next.js 14's App Router and server actions. That means instead of writing a whole separate API just to update a favorite or post a forum reply, we let components call server-side functions directly.
Authentication: Google OAuth 2.0 via NextAuth
Login is handled by Google OAuth, courtesy of NextAuth. Only students with official VIT emails can get in. No passwords to store and no forgotten credentials to reset. It's secure, fast, and familiar. On the backend, user sessions are validated on every page request using NextAuth helpers. If you're not signed in, you won't even see the dashboard SSR makes sure of that before sending any content.

Backend Service: FastAPI Microservice
Some tasks are just too heavy for the frontend like parsing a PDF or generating a thumbnail. For that, there's a Python FastAPI microservice. It handles the grunt work i.e. processing uploaded files and pushing them to Google Cloud Storage. It talks to the frontend over REST APIs. If you've ever uploaded a 30 MB file and wondered how it didn't crash the site, now you know who to thank.
Here’s what happens when you upload a PDF:
Thumbnail Generation: The microservice takes the uploaded PDF and converts the first page into a JPEG thumbnail. This helps users preview files quickly without needing to open them. Python's powerful library ecosystem (think PyPDF2, Pillow, PDFPlumber, etc.) makes this process smooth and reliable.
Cloud Upload: Both the original PDF and the generated thumbnail are uploaded to Google Cloud Storage (GCS). Offloading large files to cloud buckets means scalable, durable storage and fast delivery when users request them.
Returning URLs: Once the upload is complete, the service generates public URLs or storage paths and sends them back to the main application as a JSON response containing links to the PDF, the thumbnail and any relevant metadata or status messages.

This microservice doesn't operate in isolation. It communicates with the Next.js server via RESTful API calls. When a user uploads a file from the frontend, Next.js hands it off to the FastAPI backend, waits for the processed links, and then stores those links in the database using Prisma. The final step is sending the links to the frontend so users can view previews or download the file directly.
Database: CockroachDB + Prisma
As mentioned earlier, for storing all the structured data, ExamCooker uses CockroachDB, a distributed SQL database that speaks PostgreSQL. Fun fact: CockroachDB was named after the word “cockroach” since cockroaches are infamous for being hard to kill! With CockroachDB, you get horizontal scalability (just add nodes to handle more users or data) and high availability (failures don’t bring the system down), making it a solid choice for a growing student platform.
The database handles everything from user profiles (hooked into Google Auth via NextAuth) to metadata about uploaded notes, past papers, forum discussions, and more. A single resource record (like a past paper) likely includes its title, a GCP URL for the file, a URL for the thumbnail, who uploaded it (linked to the Users table), and tags for categorization (like subject or year).
With Prisma and CockroachDB working in tandem, the website gets the best of both worlds: resilient infrastructure and developer-friendly data access.
Prisma doesn't just make querying the database easier, it also handles schema migrations as the application evolves. This ensures that the structure of the database stays in sync with the TypeScript code, drastically reducing bugs caused by schema mismatches. With Prisma in the stack, developers can iterate quickly and safely, knowing that both their types and their tables are aligned.
Rate Limiting Layer: Redis for Fair Usage
We didn't want anyone overwhelming our servers during those frantic exam prep sessions, which is exactly why ExamCooker integrates Redis (specifically Upstash Redis) as a rate-limiting layer. Redis is an in-memory data store that tracks server action usage patterns in real time, ensuring that no single user can make excessive requests that would slow down the platform for everyone else.
The rate-limiting works by tracking request counts per user within specific time windows. When someone tries to upload multiple files rapidly or makes too many server action calls in quick succession, Redis keeps count and temporarily throttles their requests once they hit the configured limits. This protects our backend services and ensures a smooth experience for all students, especially during peak usage periods like exam weeks.
With this rate-limiting system in place, ExamCooker can handle sudden traffic spikes without degrading performance for legitimate users. It's a simple but effective way to maintain platform stability while keeping the user experience fair and responsive for everyone.
To know more about Redis, this blog by one of our senior core members is all you need! https://blog.acmvit.in/redis-a-stellar-intro

File Storage: Google Cloud Storage for Media Assets
You're probably wondering what happens to those absurdly titled scanned papers that you upload after your exams. PDFs and thumbnails don't belong crammed inside your database or tangled up in serverless functions. They deserve their own VIP storage service backed by a CDN. This is why ExamCooker outsources these to Google Cloud Storage (GCS). GCS effortlessly handles storage and bandwidth, so your web servers don't have to break a sweat whether it's 10 users or 10,000 rushing to download a file at the same time. Behind the scenes, our FastAPI microservice handles file uploads using Google's SDK or REST APIs, then hands over neat public links to the Next.js server which stores these references in the database. This way only the file URLs live in the database keeping it fast and query-friendly.
Data Flow: From Click to Cloud
Let’s walk through two common use cases: viewing exam resources and uploading new study materials to trace the complete journey from the browser to backend.
Viewing Exam Resources (Read Flow)
Client Request: Eshita, a logged-in user navigates to the "Past Papers" page. The browser makes a request to the Next.js frontend.
Session & Cache Check: The server-side logic (SSR handler) verifies Eshita’s session via NextAuth. Before hitting the database, it may check Redis to see if a cached result is available for this query (e.g., recently fetched "Software Engineering" papers).
Database Fetch (Fallback): Prisma fires a SQL query to CockroachDB. Thanks to CockroachDB's PostgreSQL compatibility and strong consistency, the query returns reliable data, which Prisma serializes into TypeScript-friendly objects.
Page Rendering: Next.js renders the React components server-side with the data, returning a fully constructed HTML page. This is fast, SEO-friendly and user-ready.
Direct Media Delivery: The client browser fetches the linked media files directly from Google Cloud Storage (GCS). These static assets are never served through the application server, offloading bandwidth and latency.
Logging & Analytics: The website might log the access or update user activity ("recently viewed") via lightweight API calls.
Uploading a New Resource (Write Flow)
User Submission: Another logged-in student, Nitesh uploads a PDF titled “CAT1 A1 24-25 Artificial Intelligence-BCSE306L” (now you know the correct nomenclature!), adds a slot, year, tags and clicks submit.
Rate Limit Check: Before processing the upload, Redis verifies that Nitesh hasn't exceeded the upload rate limits for his account.
File Handling: The PDF is first uploaded from the browser to the Next.js backend. The backend then forwards it to the FastAPI microservice for further processing.
A direct backend fetch to the microservice via REST is made (e.g., POST /process_uploaded_pdf).
The FastAPI microservice saves the PDF to GCS. It generates a JPEG thumbnail (from the first page). Both files are uploaded to designated GCS buckets. It returns the public URLs of the PDF and image.
Database Write: Next.js (using Prisma) inserts a new resource entry into CockroachDB, including:
title, fileUrl, thumbnailUrl
authorId (from the session)
Associated tags (created or linked via a junction table)
User Feedback: Nitesh will now see a success message.

Man, that was way too much tech talk! If we had a coin for every time we wrote 'scalable' or 'microservice', poor Supratim wouldn't have had to pay Google Cloud Run every month! Anyway, once deployment was done, the team worked nonstop uploading past papers and marketing for ExamCooker. Then, right around CATs (no surprises there), we saw our first big surge… 1500 users!
It wasn’t a smooth sail all along. At one point, we hit Redis's 10,000 requests/month limit and boy did it hit hard! The site stopped processing requests altogether. No caching, no responses, just dead silence. It was our first major obstacle and a very real reminder that even the smartest architecture can crumble if you don’t account for limits and quotas.
Another fine day, we crossed the 50 million request units/month limit on CockroachDB. Yes, fifty million! It was humbling (and kind of impressive?) to realize we’d built something students were using that much.

Epilogue
You probably might be wondering why we are openly sharing the system design of our application. Well, we’re doing it to celebrate hitting 11,000 users!
As ExamCooker continues to scale and support more students every day, we believe milestones like these deserve more than just a post. They deserve a deep dive into the engine that powers it all.
Thinking back to a year ago at our amateur selves who didn't know how to create routes, we have certainly evolved. What started as a summer project that had us pulling all-nighters and nearly losing our minds turned into something so much bigger: a journey filled with learning, memories and some great friendships. More than just a project, ExamCooker ended up shaping our growth in ways we never imagined.
Here’s to growing users, more papers…and cooler features!
Subscribe to my newsletter
Read articles from ExamCooker directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by