Why NGINX Can Handle Millions of Requests With Just One Process: The Architecture Behind Internet Scale
 Deepak Prasad
Deepak Prasad"NGINX can handle over a million connections — all using just one process per CPU core."
Sounds unbelievable? It's not magic. It’s brilliant engineering.
In this blog, we’ll explore how NGINX achieves internet-scale performance with minimal resources. We’ll break down the architecture, system calls, configuration, and real-world examples — all explained in simple terms with relatable technical scenarios and code snippets. If you're a developer, SRE, or systems architect, this is your guide to understanding why NGINX powers a massive portion of the internet.
The Web Server Bottleneck: A Historical Perspective
Before NGINX, servers like Apache used a traditional thread-per-request or process-per-connection model. Here’s what that means:
A client sends an HTTP request.
The server spawns a new thread or process.
This thread stays alive, often blocking while waiting for I/O (e.g., reading from disk or network).
Once the response is sent, the thread is terminated or returned to a pool.
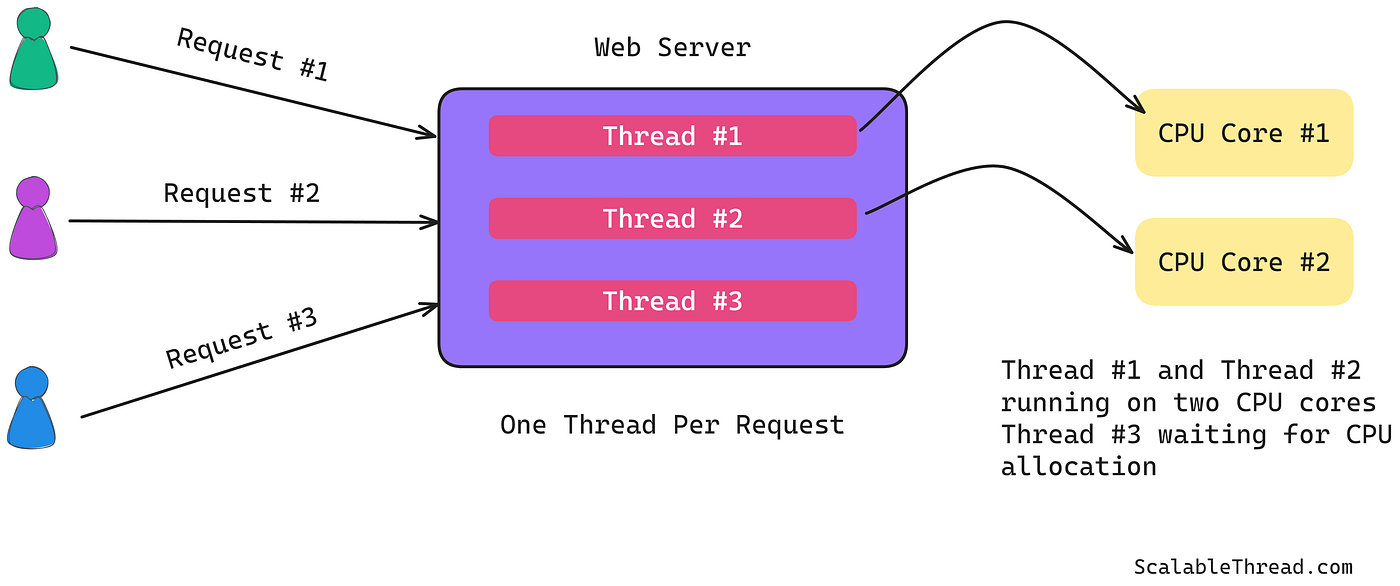
Problems with This Approach
Memory Intensive: Each thread/process takes up memory.
Context Switching: Thousands of threads means constant CPU overhead.
Poor Scalability: Can handle only a few thousand clients before failing.
Technical Breakdown:
Suppose you have a machine with 8GB RAM and you're running Apache. Each thread consumes 2MB. You can only handle about 4000 concurrent connections before exhausting memory. Add overhead from context switching and blocking I/O, and you quickly hit performance bottlenecks.
The NGINX Philosophy: Do More With Less
NGINX was designed to solve the C10k problem — how to handle 10,000+ concurrent connections efficiently. Its answer: event-driven, non-blocking I/O.
Instead of spinning up one thread per connection, NGINX:
Uses a single-threaded event loop per worker.
Handles I/O asynchronously.
Reacts only when data is ready to be read or written.
Simplified Technical Example:
Let’s imagine a simplified technical example:
Say 100 users make requests to an NGINX server.
Instead of spinning 100 threads, NGINX just notes their file descriptors (a kind of ID for network connections).
Using
epoll, NGINX waits for any of those connections to become active (like receiving a request).When data is ready on, say, connection #32, NGINX processes only that, not all 100.
This drastically reduces CPU and memory usage.
Node.js vs NGINX: Similar Foundations, Different Purposes
Both Node.js and NGINX utilize an event loop, but their implementations and responsibilities are very different.
Node.js Event Loop:
Built on libuv, a cross-platform abstraction that provides non-blocking I/O.
Runs JavaScript and handles callbacks, timers, HTTP requests, file system I/O, etc.
Designed to serve application-level logic like APIs, database calls, business logic.
NGINX Event Loop:
Built directly on epoll (Linux), kqueue (BSD/macOS), or select depending on the OS.
Written in C for performance.
Optimized for low-level networking tasks — serving static files, SSL termination, reverse proxying, caching.

Key Differences:
| Aspect | Node.js | NGINX |
| Purpose | Application runtime | Web server, reverse proxy, load balancer |
| Language Runtime | JavaScript | Native C |
| Event Loop Backend | libuv (built on epoll, kqueue, etc.) | Direct use of OS APIs like epoll |
| Handles | HTTP requests, database I/O, user logic | TCP/UDP sockets, static file serving, reverse proxy |
| Threading Model | Single-threaded (with worker threads for I/O) | Multi-process (each process has its own event loop) |
Technical Example:
Imagine you're building a video streaming site:
NGINX is the first point of contact. It terminates SSL, serves thumbnails and static assets (MP4 files), and routes API requests.
Node.js is behind NGINX, handling the API logic like login, comment submission, and video analytics.
Both use event loops, but at different layers of the stack.
NGINX Architecture Explained
Master and Worker Model
NGINX uses a master-worker architecture:
The master process is responsible for reading and evaluating configuration files, managing worker processes, and handling administrative signals (e.g., reload, restart).
The worker processes are where the real work happens. Each worker process is single-threaded and handles thousands of connections asynchronously.
Importantly, each worker has its own event loop, completely independent from others. This design allows NGINX to scale across multiple CPU cores by spawning one worker per core.
Why This Matters:
No thread contention or shared memory access between workers.
Fully parallelized use of CPU cores.
Workers never block — they sleep until
epollreports that I/O is ready, then handle just that event.
Listen Socket vs Connection Socket
To understand how NGINX handles new and active connections, it’s important to distinguish two key types of sockets:
Listen Socket: This is a special socket bound to a port (e.g., port 80 or 443) that the NGINX worker uses to accept new client connections. Only one listen socket is needed per port.
Connection Socket: When a client initiates a connection to the server, the operating system accepts the connection on the listen socket and creates a new connection socket for that client. This socket is now uniquely associated with that particular client session.

Here’s how NGINX uses these sockets:
The worker process monitors the listen socket using
epoll.When a client initiates a connection, the OS notifies NGINX via
epoll, and the worker accepts it usingaccept().The resulting connection socket is then added to the epoll watch list.
From then on, the worker only monitors and interacts with that connection socket — reading HTTP requests, writing responses, etc.
This separation ensures scalability: one listen socket to handle new connections, and a set of lightweight, non-blocking connection sockets for each client.
How NGINX's Event Loop Actually Works (Step by Step)
Let’s break down NGINX’s event loop in a clear sequence:
Accept Connections: NGINX listens on a port for HTTP/HTTPS requests.
Register Events: It registers each socket connection with the operating system using
epoll.Wait for Events: The worker process enters a loop and uses
epoll_wait()to sleep until an event occurs.React to Events: When data is ready (a request came in or a response is ready to be sent), NGINX reacts.
Process and Return: NGINX may serve a static file or proxy the request to a backend server like Node.js.
Real-World Use Case: CDN Edge Node
Let’s tie this into a real-world example: a CDN provider like Cloudflare or Akamai.
Each edge node:
Terminates SSL connections using NGINX.
Serves cached assets like images, CSS, JS directly from memory or disk.
Proxies API calls or dynamic content to backend services.
Even under 1M concurrent connections globally, only 10–20 NGINX workers are required across CPU cores. Static assets are delivered directly, while dynamic requests are handled intelligently through proxying — all using the same event-driven loop.
This is why NGINX is ubiquitous across tech companies — from Netflix to Dropbox — it forms the front door to the internet.
If You Enjoyed This Post…
If you enjoyed this blog, please consider leaving a comment below. Let me know what topics you'd love to see next — whether it's reverse proxy configurations, Kubernetes ingress, or load balancer deep dives.
Looking for more blogs like this? Follow me here on Hashnode for technical deep-dives into backend architecture, performance tuning, and infrastructure design.
💬 Got ideas or suggestions? Drop them in the comments. Let’s geek out together!
Subscribe to my newsletter
Read articles from Deepak Prasad directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by