🔍 Introduction to RAGs: Demystifying Vectorization, Chunking, Indexing and and Integration with Pinecone & LangChain
 Robin Roy
Robin Roy
Learn how Retrieval-Augmented Generation (RAG) works behind the scenes, why chunking is essential, what indexing does, and how to connect everything using LangChain, Pinecone, and OpenAI — with diagrams and a GitHub repo!
📌 Introduction
Large Language Models (LLMs) are powerful — but they forget things. They hallucinate. They can't access your data directly. This is where RAG (Retrieval-Augmented Generation) comes in.
In this article, we’ll cover:
What is Indexing?
Why Vectorization matters?
Why Chunking & Overlapping is done?
Why RAGs exist?
Full code for a working RAG system using LangChain, Pinecone, and OpenAI.
A GitHub repository to try it yourself.
🧠 Why do RAGs Exist?
LLMs are trained on data up to a certain point. They can’t know your documentation, files, or private resources.
RAG = Grounding LLMs in real-time context.
It allows your LLM to:
Look up external knowledge
Understand private/company data
Stay up-to-date
🔁 Retrieval + 💬 Generation = 🔥 Powerful, personalized AI
📦 What is Indexing?
Imagine you want to search across your entire documentation — but semantically, not just via keywords.
Indexing lets you:
Store chunks of content as vectors (dense embeddings)
Later, match user queries to the most relevant vectors
Think of Pinecone as a Google-like index — but for semantic meanings.
📐 Why Do We Perform Vectorization?
Vectorization converts text into numerical arrays (vectors) using models like OpenAI Embeddings.
Example:
from langchain_openai import OpenAIEmbeddings
embedding_model = OpenAIEmbeddings()
embedding = embedding_model.embed_query("What is RAG?")
This turns the sentence into a 1536-dimensional vector — ready to be compared with other document vectors.
📃 Why Chunking? Why Overlap?
Chunking
LLMs can’t process huge documents at once (token limits). Chunking breaks content into bite-sized parts (e.g. 500–1000 tokens).
Overlapping
Context often spans across boundaries. By overlapping chunks, you preserve the semantic flow.
Example:
Chunk A: lines 1–100
Chunk B: lines 80–180
That 20-line overlap helps the LLM retain flow.
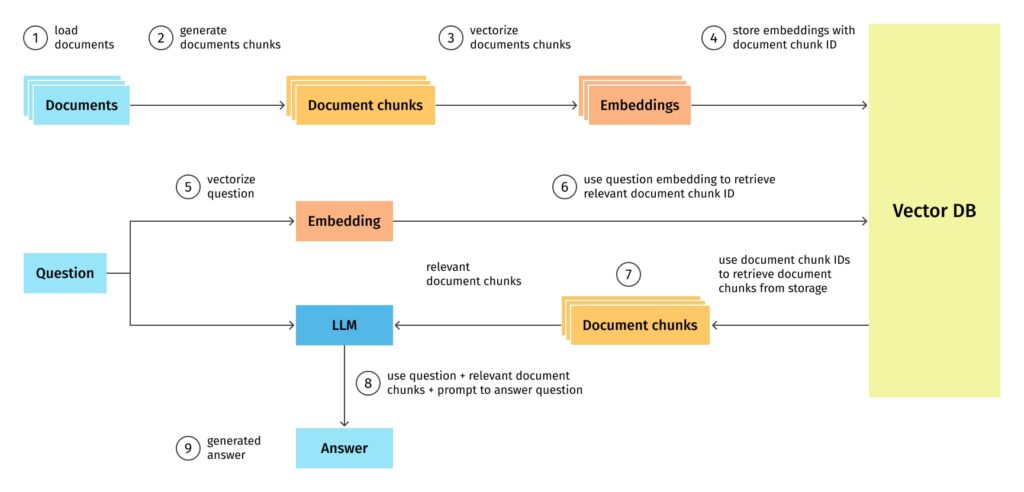
📊 1. Diagram: How RAG Works
The above infographic breaks down the common RAG pipeline:
Chunking (with optional overlap)
Embedding (vectorization using models like Llama embeddings or OpenAI’s)
Indexing in a vector store (e.g. Pinecone, Chroma)
Retrieval at query time
Generation via an LLM (GPT-4, Llama)
🛠️ Building a RAG Bot using LangChain + Pinecone + OpenAI
Let’s build a chatbot that can answer based on your documentation (like https://docs.chaicode.com).
🔧 Step 1: Install Dependencies
pip install langchain langchain-openai streamlit pinecone-client python-dotenv
🧪 Step 2: .env Config
OPENAI_API_KEY=your_key
PINECONE_API_KEY=your_key
PINECONE_ENVIRONMENT=us-east-1
🧱 Step 3: Chunk, Embed, and Index
import os
from dotenv import load_dotenv
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import OpenAIEmbeddings
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone, ServerlessSpec
load_dotenv()
loader = WebBaseLoader("https://docs.chaicode.com/")
documents = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY"))
index_name = "chaicode-rag"
if not pc.has_index(index_name):
pc.create_index(index_name, dimension=1536, metric="cosine", spec=ServerlessSpec(cloud="aws", region="us-east-1"))
vector_store = PineconeVectorStore.from_documents(chunks, embedding=embeddings, index_name=index_name)
🧠 Step 4: RAG Chain with LangChain
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.messages import AIMessage, HumanMessage
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4")
retriever = vector_store.as_retriever()
retriever_chain = create_history_aware_retriever(
llm,
retriever,
ChatPromptTemplate.from_messages([
MessagesPlaceholder("chat_history"),
("user", "{input}"),
("user", "Generate a search query to retrieve relevant context.")
])
)
stuff_chain = create_stuff_documents_chain(
llm,
ChatPromptTemplate.from_messages([
("system", "Answer using this context:\n\n{context}"),
MessagesPlaceholder("chat_history"),
("user", "{input}")
])
)
chain = create_retrieval_chain(retriever_chain, stuff_chain)
💬 Step 5: Streamlit UI
import streamlit as st
st.title("Ask Anything about ChaiCode Docs")
if "history" not in st.session_state:
st.session_state.history = []
query = st.chat_input("Ask something...")
if query:
answer = chain.invoke({"chat_history": st.session_state.history, "input": query})['answer']
st.session_state.history.extend([HumanMessage(content=query), AIMessage(content=answer)])
for msg in st.session_state.history:
role = "AI" if isinstance(msg, AIMessage) else "User"
with st.chat_message(role):
st.write(msg.content)
🧑💻 GitHub Repo
🔗 GitHub: robinroy/rag-chatbot-chaicode
The repo includes:
Pinecone integration
LangChain chains
Documentation scraper
Chatbot UI with Streamlit
Deployment-ready structure
🎯 Final Thoughts
RAGs are not just a trend — they are becoming the default for data-aware, high-accuracy LLM systems. Whether you're building an AI support assistant, educational tutor, or knowledge base — chunking, embedding, and retrieval is your path forward.
Subscribe to my newsletter
Read articles from Robin Roy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by