The Rise of AI SuperClouds: GPU Clusters for Next-Gen AI Models
 Tanvi Ausare
Tanvi AusareTable of contents
- Introduction
- 1. What is an AI SuperCloud?
- 2. The Evolution of GPU Cloud Hosting
- 3. Building Blocks of AI Cloud Infrastructure
- 4. High Performance Computing (HPC) for AI
- 5. GPU Clusters for AI: The Engine Behind Modern AI
- 6. Cloud GPU for AI: Democratizing Compute Power
- 7. Supercomputing for Machine Learning and LLMs
- 8. Cloud Computing for LLMs
- 9. Distributed AI Training in the Cloud
- 10. NVIDIA H100 Cloud: The Gold Standard
- 11. Scalable AI Infrastructure: Meeting Tomorrow’s Demands
- 12. Multi-GPU Cloud and LLM Deployment Cloud
- 13. Edge AI and Cloud Synergy
- 14. Choosing the Best Cloud Provider for Training Large AI Models
- 15. AI SuperCloud vs. Traditional Cloud: A Comparative Analysis
- 16. Affordable GPU Clusters for Startups
- 17. Deploying Generative AI on GPU Cloud
- 18. Optimizing LLM Performance with AI SuperClouds
- 19. Running Multi-Modal AI Models in the Cloud
- 20. Scalable GPU Architecture for AI Model Training
- 21. Benefits of GPU Cloud Computing for AI Research
- 22. Cloud-Native Infrastructure for AI Workloads
- The Growth of AI SuperClouds: A Visual Perspective
- Conclusion

AI SuperClouds combine GPU clusters, HPC, and cloud-native infra to power LLMs, generative AI, and multi-modal AI. They make AI faster, scalable, and affordable.
TL;DR: Why AI SuperClouds Matter
Definition: AI supercomputer in the cloud, multi-cloud + hybrid ready
GPU Hosting: From fractional → bare-metal, multi-GPU, global scale
Infra & HPC: GPUs + NVLink/InfiniBand, distributed storage, MLOps
GPU Clusters: Train trillion-parameter LLMs, real-time generative AI
Cloud AI Power: Democratized compute, pay-as-you-go, seamless scaling
Training & Performance: Distributed parallelism, NVIDIA H100 speedup
Scalability: Elastic infra, multi-GPU deployment, batch + real-time
Edge & Startups: Edge-cloud synergy + affordable GPU clusters
Applications: Generative, multi-modal, research, CI/CD workflows
Growth: Enterprise AI cloud spend rising sharply
Introduction
The world of artificial intelligence (AI) is undergoing a seismic transformation, driven by the explosive growth of large language models (LLMs), generative AI, and multi-modal systems. At the heart of this revolution lies a new breed of infrastructure: the AI SuperCloud. These next-generation platforms combine the raw computational power of GPU clusters with the flexibility and scalability of cloud-native architectures, enabling organizations to train, deploy, and optimize the most demanding AI models ever conceived.
In this comprehensive blog, we’ll explore the rise of AI SuperClouds, the pivotal role of GPU cloud hosting, and how scalable AI infrastructure is reshaping the landscape for startups, enterprises, and researchers alike. We’ll also dive deep into the technical underpinnings, such as high performance computing (HPC), distributed AI training, and the latest offerings that make it all possible.
1. What is an AI SuperCloud?
An AI SuperCloud is a multi-node, AI-training-as-a-service solution that spans multiple cloud platforms, including on-premises and edge installations. It abstracts the complexity of hyperscale infrastructure, providing a seamless, unified environment for training and deploying next-gen AI models. Think of it as an “AI supercomputer in the cloud,” engineered for the unique demands of enterprise AI and LLMs.
Key features of AI SuperClouds include:
Multi-cloud and hybrid integration
Unified API and management layer
Advanced GPU clusters optimized for AI workloads
Predictable, transparent pricing models
End-to-end workflow management for AI development
2. The Evolution of GPU Cloud Hosting
GPU cloud hosting has evolved from niche offerings to mainstream platforms powering everything from research labs to global enterprises. Early cloud solutions often provided fractional GPU access, but modern providers now offer bare-metal performance, multi-GPU clusters, and seamless scaling for the largest AI models.
Benefits of modern GPU cloud hosting include:
Instant access to the latest NVIDIA GPUs (e.g., H100, H200)
Flexible configurations (single-tenant, multi-GPU, bare metal)
Pre-installed AI frameworks (TensorFlow, PyTorch, JAX)
Global availability with ultra-low latency networking
3. Building Blocks of AI Cloud Infrastructure
The foundation of any AI cloud infrastructure is the combination of high-performance GPUs, fast interconnects (e.g., NVLink, InfiniBand), and cloud-native orchestration tools. This infrastructure enables:
Rapid provisioning and scaling of compute resources
Fault-tolerant, distributed storage
Real-time monitoring and API-driven management
Seamless integration with DevOps and MLOps pipelines
4. High Performance Computing (HPC) for AI
High performance computing (HPC) is no longer just for scientific simulations, it’s now essential for AI model training and inference. HPC in the cloud leverages powerful GPU clusters to accelerate:
Deep learning model training (NLP, computer vision, multi-modal)
Large-scale simulations (climate, genomics, finance)
Real-time analytics and data processing
Cloud-based HPC offers on-demand scalability, pay-as-you-go pricing, and democratized access to supercomputing resources for organizations of all sizes.
5. GPU Clusters for AI: The Engine Behind Modern AI
GPU clusters for AI are the backbone of today’s most ambitious machine learning projects. By connecting thousands of GPUs via high-speed networks, these clusters enable:
Training of trillion-parameter LLMs (e.g., GPT-4, Llama 2)
Distributed AI training (data, model, and hybrid parallelism)
Real-time inference for generative AI applications
Modern clusters leverage technologies like NVIDIA NVLink and Quantum-2 InfiniBand for ultra-fast GPU-to-GPU communication, ensuring efficient scaling across massive workloads.
6. Cloud GPU for AI: Democratizing Compute Power
Cloud GPU for AI solutions have made high-end compute accessible to everyone from startups to Fortune 500s. Key advantages include:
Scalability: Instantly scale up or down based on project needs
Cost efficiency: Pay only for what you use, with no upfront hardware investment
Accessibility: Collaborate globally, with resources available anywhere
High performance: Accelerate model training and reduce time-to-insight
7. Supercomputing for Machine Learning and LLMs
Supercomputing for machine learning is now a reality thanks to cloud-based GPU clusters. These platforms deliver the computational power required for:
Training and fine-tuning LLMs and foundation models
Running multi-modal AI (text, image, audio, video)
Pushing the boundaries of generative AI and reinforcement learning
8. Cloud Computing for LLMs
Cloud computing for LLMs enables organizations to train and deploy large language models without the need for on-premises supercomputers. Benefits include:
Access to the latest GPUs (H100, H200, GB200)
Seamless scaling for massive datasets and models
Integration with MLOps tools for automated deployment and monitoring
9. Distributed AI Training in the Cloud
Distributed AI training is essential for accelerating model development and optimizing resource utilization. Common techniques include:
Data parallelism: Splitting datasets across multiple GPUs
Model parallelism: Partitioning models across devices
Hybrid parallelism: Combining both for maximum efficiency
Cloud platforms provide the orchestration tools and networking required to synchronize updates and manage large-scale distributed training jobs.
10. NVIDIA H100 Cloud: The Gold Standard
The NVIDIA H100 cloud represents the cutting edge of AI compute. Key features:
Fourth-generation Tensor Cores and Transformer Engine
Up to 4X faster training for LLMs (e.g., GPT-3) compared to previous generations
NVLink and Quantum-2 InfiniBand for 900 GB/s GPU-to-GPU interconnect
Enterprise-grade security, manageability, and support
H100-powered clouds are ideal for training and deploying the most demanding generative AI, computer vision, and multi-modal models.
11. Scalable AI Infrastructure: Meeting Tomorrow’s Demands
Scalable AI infrastructure is crucial for supporting the rapid growth of AI workloads. Modern platforms offer:
Elastic scaling of GPU and CPU resources
Automated provisioning and workload balancing
Support for both batch and real-time processing
This flexibility ensures that organizations can adapt to changing demands without costly hardware upgrades.
12. Multi-GPU Cloud and LLM Deployment Cloud
Multi-GPU cloud solutions allow users to run large models across multiple GPUs, dramatically reducing training times. LLM deployment clouds provide:
Pre-configured environments for rapid LLM deployment
Optimized networking for low-latency inference
Tools for monitoring, scaling, and managing live AI services
13. Edge AI and Cloud Synergy
The convergence of Edge AI and cloud synergy enables organizations to leverage the strengths of both centralized and decentralized computing:
Cloud: Scalable infrastructure for training and analytics
Edge: Real-time inference and localized decision-making
Seamless data flow between edge devices and cloud platforms
This hybrid approach reduces latency, optimizes bandwidth, and enhances data privacy.
14. Choosing the Best Cloud Provider for Training Large AI Models
When selecting the best cloud provider for training large AI models, consider:
Availability of the latest GPUs (H100, H200, GB200)
Network bandwidth and latency (NVLink, InfiniBand)
Support for distributed training and multi-GPU configurations
Transparent pricing and flexible billing
Integration with popular AI frameworks and MLOps tools
15. AI SuperCloud vs. Traditional Cloud: A Comparative Analysis
| Feature | AI SuperCloud | Traditional Cloud |
| GPU Cluster Scale | Massive, multi-node, optimized for AI | Limited, often fractional access |
| Distributed AI Training | Native support, high-speed interconnects | Limited or manual configuration |
| Cloud-Native AI Tools | Integrated, end-to-end workflow | Basic or third-party integration |
| Cost Transparency | Predictable, all-inclusive pricing | Variable, often with hidden fees |
| Edge AI Integration | Seamless cloud-edge synergy | Limited or siloed |
AI SuperClouds offer a purpose-built environment for AI workloads, while traditional clouds may struggle with the scale and complexity of modern AI.
16. Affordable GPU Clusters for Startups
Startups can now access affordable GPU clusters due to cloud-based and pay-as-you-go models:
No upfront hardware investment
Flexible scaling as projects grow
Access to the latest GPU technology
Pre-configured AI environments for rapid prototyping
This democratization of compute power is accelerating innovation across industries.
17. Deploying Generative AI on GPU Cloud
Deploying generative AI on GPU cloud platforms enables organizations to:
Launch large-scale generative models (text, image, audio, video)
Scale inference workloads to meet user demand
Integrate with APIs for real-time applications
GPU clouds provide the performance and flexibility required to support the next wave of generative AI.
18. Optimizing LLM Performance with AI SuperClouds
To optimize LLM performance with AI SuperClouds:
Leverage high-speed GPU interconnects (NVLink, InfiniBand)
Use distributed training strategies (data/model/hybrid parallelism)
Monitor and tune resource utilization in real-time
Employ automated scaling to handle peak loads
These optimizations reduce training times and improve inference latency for production LLMs.
19. Running Multi-Modal AI Models in the Cloud
Multi-modal AI models (combining text, vision, audio, etc.) require immense compute power and flexible infrastructure. Cloud platforms enable:
Parallel training across multiple data modalities
Scalable storage and data pipelines
Integrated APIs for deploying multi-modal inference services
20. Scalable GPU Architecture for AI Model Training
A scalable GPU architecture is essential for training the largest AI models:
Modular design allows for incremental scaling
High-bandwidth networking ensures efficient data transfer
Automated workload distribution maximizes GPU utilization
This architecture underpins the performance and reliability of AI SuperClouds.
21. Benefits of GPU Cloud Computing for AI Research
GPU cloud computing offers transformative benefits for AI research:
Accelerated model training and experimentation
Access to cutting-edge hardware and tools
Collaboration across global research teams
Cost-effective scaling for projects of any size
Researchers can focus on innovation rather than infrastructure management.
22. Cloud-Native Infrastructure for AI Workloads
Cloud-native infrastructure for AI workloads enables organizations to:
Deploy containerized AI models with Kubernetes and Docker
Automate scaling and failover for high availability
Integrate with CI/CD pipelines for rapid iteration
This approach streamlines the development, deployment, and management of AI services.
The Growth of AI SuperClouds: A Visual Perspective
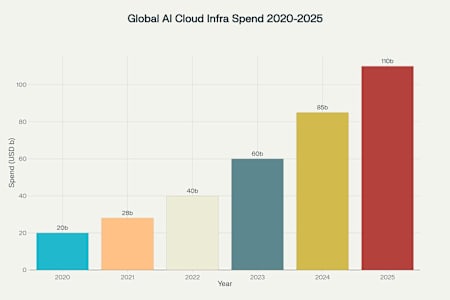
Bar chart showing the rapid growth in global enterprise spending on AI cloud infrastructure from 2020 to 2025
The rapid adoption of AI SuperClouds and GPU clusters is reflected in the explosive growth of enterprise spending on AI cloud infrastructure.
Conclusion
The rise of AI SuperClouds marks a new era in the evolution of artificial intelligence. By harnessing the power of GPU cloud hosting, distributed AI training, and scalable AI infrastructure, organizations can unlock unprecedented levels of performance, flexibility, and innovation. Whether you’re a startup seeking affordable GPU clusters, a research lab pushing the boundaries of LLMs, or an enterprise deploying generative AI at scale, the AI SuperCloud is your gateway to the future of machine learning.
At NeevCloud, we’re committed to empowering the global AI community with state-of-the-art GPU clusters, cloud-native infrastructure, and seamless cloud-edge synergy. Experience the next generation of AI compute power—experience the AI SuperCloud.
Subscribe to my newsletter
Read articles from Tanvi Ausare directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tanvi Ausare
Tanvi Ausare
Digital Marketer & Technical Writer at NeevCloud, India’s AI First SuperCloud company. I write at the intersection of technology, cloud computing, and AI, distilling complex infrastructure into real, relatable insights for builders, startups, and enterprises. With a strong focus on tech marketing, I simplify technical narratives and shape strategies that connect products to people. My work spans cloud-native trends, AI infra evolution, product storytelling, and actionable guides for navigating the fast-moving cloud landscape.