SQLFlashiHow Predicate Pushdown Enhances SQL Query Performance?
 SQLFlash
SQLFlashIntroduction
In big data scenarios, optimizing SQL query performance is a critical task for database management. Predicate pushdown, a classic query rewriting optimization technique, reduces data processing volume by pushing filtering conditions closer to the data source. This directly lowers I/O consumption, improves index utilization, and minimizes CPU computation. This article validates the optimization effects of predicate pushdown across different query structures using real-world testing environments (1M-row datasets), compares execution plans, analyzes performance metrics, and clarifies optimization boundaries — providing actionable guidance for developers.
Test Environment Setup
1. Table Structure Design
-- Student scores main table (1 million records)
CREATE TABLE students (
student_id INT AUTO_INCREMENT PRIMARY KEY,
dept_id INT NOT NULL,
score DECIMAL(5,2) NOT NULL DEFAULT 0.0,
exam_time DATETIME DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB;
2. Test Data Generation
-- Generate 1 million student score records
SET cte_max_recursion_depth=1000000;
INSERT INTO students (dept_id, score)
WITH RECURSIVE seq AS (
SELECT 1 AS n UNION ALL
SELECT n+1 FROM seq WHERE n < 1000000
)
SELECT
FLOOR((n-1)/500000)+1 AS dept_id,
ROUND(50 + RAND(n)*50 + (n%10)*0.5, 2) AS score
FROM seq;
SQL Optimization
1. Original SQL
SELECT *
FROM (
SELECT
student_id,
AVG(score) AS avg_score
FROM students
GROUP BY student_id
) AS temp
WHERE avg_score > 5.0;
2. Optimized SQL with SQLFlash
We rewrote the query using SQLFlash.
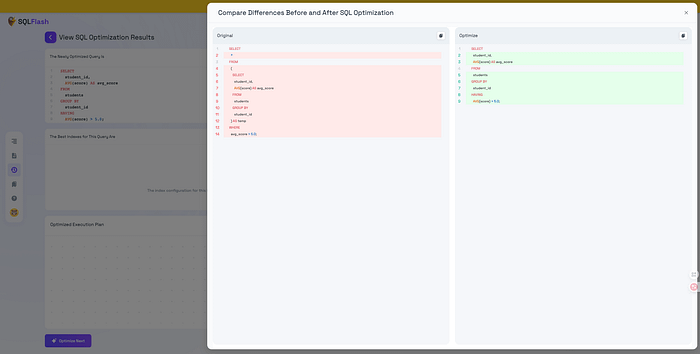
Optimized SQL:
SELECT student_id, AVG(score) AS avg_score
FROM students
GROUP BY student_id
HAVING AVG(score) > 5.0;
Performance Analysis
SQLFlash Insights
SQLFlash’s analysis reveals that the optimized query moves the avg_score > 5.0 filter into the HAVING clause. This allows the aggregation step (grouping and calculating AVG(score)) to filter out unqualified groups during computation, reducing the result set size before outer processing. Combined with subquery folding, it merges aggregation and filtering into a single step, eliminating redundant intermediate result sets and streamlining the query structure.
Original Execution Plan
mysql> explain SELECT * FROM ( SELECT student_id, AVG(score) AS avg_score FROM students GROUP BY student_id ) AS temp WHERE avg_score > 5.0;
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 997899 | 33.33 | Using where |
| 2 | DERIVED | students | NULL | index | PRIMARY | PRIMARY | 4 | NULL | 997899 | 100.00 | NULL |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+--------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
Optimized Execution Plan
mysql> explain SELECT student_id, AVG(score) AS avg_score FROM students GROUP BY student_id HAVING AVG(score) > 5.0;
+----+-------------+----------+------------+-------+---------------+---------+---------+------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+--------+----------+-------+
| 1 | SIMPLE | students | NULL | index | PRIMARY | PRIMARY | 4 | NULL | 997899 | 100.00 | NULL |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+--------+----------+-------+
1 row in set, 1 warning (0.00 sec)
Performance Metrics Comparison
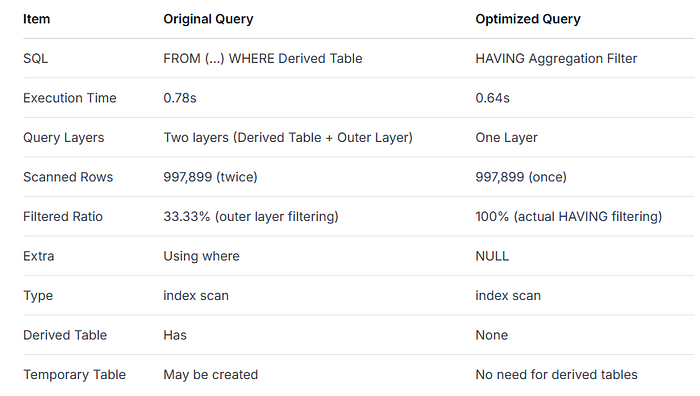
Optimization Principles
1. Rows Scanned
Both queries scan 997,899 rows (full table scan). However:
The subquery version scans twice: once to generate the derived table, then again to filter the temporary result (33.33% filtered by
WHERE).The
HAVINGversion completes grouping and filtering in a single scan, with a more compact workflow.
✅ Conclusion: Both scan the same rows, but HAVING eliminates intermediate table processing.
2. CPU Usage
Subquery + Outer
WHERE: Higher CPU cost due to grouped aggregation in the first scan, followed by row filtering on the temporary table.HAVINGVersion: Single scan and aggregation, with no intermediate table—reducing CPU load, especially with large result sets.
✅ Conclusion: HAVING saves CPU time, particularly with large datasets.
3. Disk I/O
Subquery Version: May generate temporary tables (depending on data size and
tmp_table_size). Large temporary tables spill to disk, increasing I/O.HAVINGVersion: No intermediate tables; aggregation completes in-memory (if memory permits), avoiding disk spills.
✅ Conclusion: HAVING minimizes disk I/O, improving performance in large-data scenarios.
Conclusion
Optimization Outcomes
- Efficiency Gains:
Eliminates derived table generation, reducing intermediate table scans and overall execution time.
Merges aggregation and filtering into a single step, lowering CPU usage.
Avoids disk temporary tables, reducing I/O pressure in big-data scenarios.
2. Optimization Boundaries
Always prioritize
HAVINGover outerWHEREfor post-aggregation filters.Combine with index optimization when filters can be pushed to base table scans (e.g.,
WHEREclauses).
Development Recommendations
Use
HAVINGinstead of outerWHEREfor grouped aggregation filters.Monitor
EXPLAINplans forDERIVEDidentifiers to eliminate unnecessary intermediate tables.Refactor queries instead of solely increasing
tmp_table_sizewhen threshold limits are hit.
Subscribe to my newsletter
Read articles from SQLFlash directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
SQLFlash
SQLFlash
Sharing SQL optimization tips, product updates, and early access to SQLFlash — an AI tool that helps developers write faster queries.