Tech Behind the Scenes: Mastering Software Architecture Patterns
 Pratyush Pragyey
Pratyush Pragyey
When you launch a rocket, every nut and bolt matters — but it all starts with the blueprint. That’s software architecture: the grand design, the city layout, the strategic chessboard. Whether you’re building a side project, a startup MVP, or a planet-scale system, choosing the right architecture can be the game-changer. Let’s decode the most impactful software architecture patterns — with energy, clarity, and zero yawns.
Architecture vs Design Patterns — What’s the Difference?
Think of architecture as city planning — zoning out commercial districts, residential areas, industrial zones. Now think of design patterns as building blueprints — where the staircase goes, how the windows open, or the plumbing flows.
Architecture = High-level system structure (how components talk).
Design Patterns = Code-level tactics within a component (how logic flows).
Monolithic Architecture — The OG Setup
Imagine building a mall where the food court, stores, parking, cinema — all live in a single, giant building. That’s monolithic architecture.
Pros:
Easy to develop & deploy.
Great for MVPs and quick go-to-market plans.
Cons:
Poor scalability.
One crash can take down the whole system.
Hard to adopt modern DevOps practices.
Examples: Layered, Pipeline, and Microkernel architectures often start as monoliths.
Distributed Architecture — Divide and Conquer
Unlike a mall, imagine a city where every store is its own building, communicating over a network. That’s distributed architecture — systems made of independent deployment units that work together to perform some business logic.
But beware of the 8 deadly fallacies developers assume when working with distributed systems:
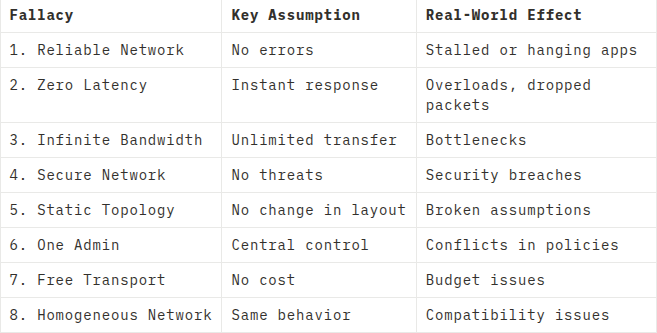
Fallacies made by developers
Partitioning: Slice It Right!
Partitioning refers to the process of dividing a software system’s codebase or logic into smaller, cohesive units that can be developed, tested, and maintained independently. Let’s say you’re building an e-commerce app. You’ve got two ways to slice your code:
Technical Partitioning:
Divides the codebase based on technical responsibilities (e.g., UI, business logic, data access).
Key Layers in Technical Partitioning
Presentation Layer
Business Logic Layer (Application Layer)
Persistence Layer (Data Access Layer)
Database Layer
Domain Partitioning:
Divide by features — Wishlist, cart, payment, support. Then apply technical layers inside each. This is more modular and matches real-world complexity.
Layered Architecture — The Classic Stack
In layered architecture, the application is divided into horizontal layers, each responsible for a specific type of functionality. The layers communicate in a structured manner, typically with higher layers depending on lower ones.
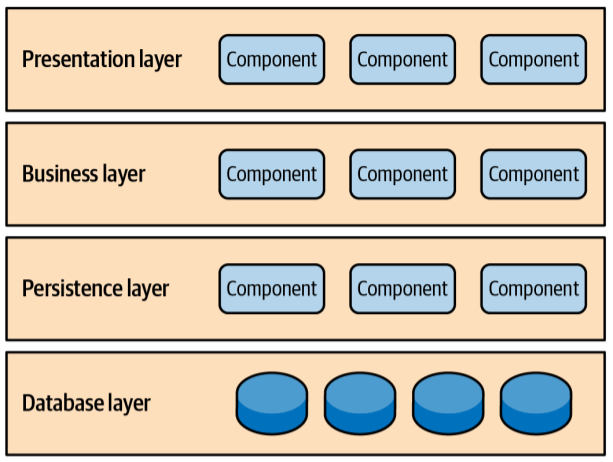
Layered Architecture
Presentation Layer:
Handles the user interface (UI) and user interactions.
Responsible for rendering views, capturing user input, and forwarding requests to the business layer.
Examples: Web controllers, front-end frameworks (e.g., React, Angular), or API endpoints.
Business Logic Layer (Application Layer):
Contains the core logic of the application, including rules, workflows, and computations.
Manages tasks like validating input, enforcing business rules (e.g., checking inventory before confirming a product’s availability), or coordinating operations across multiple components.
Examples: Service classes, domain logic, or orchestration of use cases.
Persistence Layer (Data Access Layer):
Manages interactions with data storage systems, such as databases, file systems, or external APIs.
Responsible for CRUD operations (Create, Read, Update, Delete) and data mapping.
Examples: Repositories, ORMs (e.g., Hibernate, Sequelize), or database query logic.
Database Layer:
Executes queries to fetch or manipulate data, such as retrieving user details or saving order records.
Abstracts the specifics of the storage system (e.g., relational databases like MySQL, NoSQL databases like MongoDB, or file-based storage) from higher layers.
But watch out for the Sinkhole Anti-Pattern:
If all your service methods just pass data to the next layer without any logic, you’re wasting layers. It’s Increasing processing time, network latency, etc. Example:
getUserById(id) → return dataLayer.getUserById(id);
This adds latency without value. As Martin Fowler says:
“If 80% of the calls just pass through a layer, rethink that layer!”
Microkernel Architecture — Plug it In!
Also called the plugin architecture, it’s all about extensibility. You’ve got a core app, and then you bolt on features like plugins — think text editors like VSCode or media players with skins and codecs.
Great when your base system is solid, but you want to add turbo boosters on demand.
Event-Driven Architecture — Let the Events Flow!
Perfect for systems where stuff needs to happen because something else happened. Like:
“Order placed” → “Send confirmation email” → “Update inventory” → “Trigger shipping.”
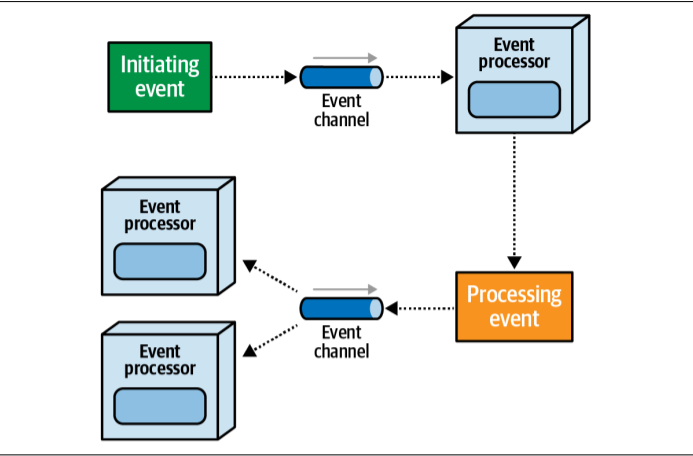
The main components of event-driven architecture
Key Components:
Event Processor: Usually called a service now, is the main deployment unit in event-driven architecture. They can trigger async events and respond to async events being triggered.
Initiating Event: It comes from outside the main system and kicks off the async workflow. For example — placing an order, buying a stock, filling an insurance claim, they don’t exist in the system but trigger the workflow. Usually initiating events are received by only one service and then starts the chain of events.
Processing Event: Known as derived event, as name suggest they get derived from an event. For example — A order has been placed, which triggers an order placed processing event, payment applied, inventory updated and E-mail notification processing events. so, one imitating event fired multiple events, and they are known as processing events.
Event Channel: It’s a queue for processing or initating the events. Like we would need a channel to process all these upcoming events, right? so initiating events use queues or messaging services whereas processing events use pub/sub channels using topics or notification services.
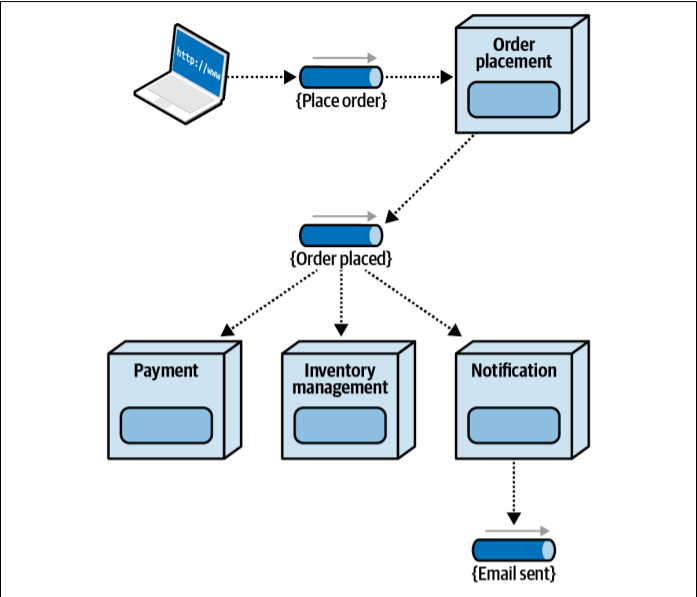
Workflow for event-driven architecture
This architecture is highly decoupled. Services don’t care who’s listening or reacting — they just shout, “Hey! An order was placed!” and move on.
Event Driven VS Message Driven:
An event is telling others about the state change or something you did. example — “I just placed an order”, “I just made a bid”. Whereas a message is a command or request to a specific service. example — “ship the item to this address”, “give me the customer’s email address”. Event has no idea which all services will respond whereas message is usually directed to a single known service.
With events the sender owns the event channel whereas with messages, the receiver owns the channel. consider the diagram below, in this order placement service is sending out an order placed event that is responded by the payment service. In this case sender (Order placement) owns the contract and the event channel so any changes to the contract will have to be adopted by the payment services and all the other services responding to that event (order placed).
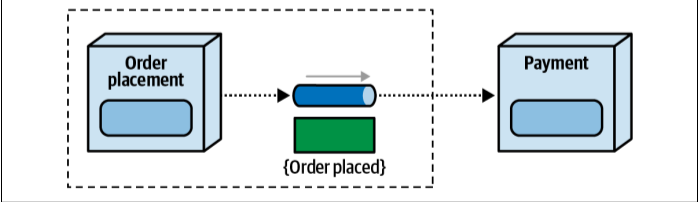
With events, the sender owns the event channel and
contract
- Now looking at the diagram below, with messages in message driven system, it’s the opposite — the receiver owns the message channel and the contract. In this order placement will need to adopt any changes in the contract done by the payment services.
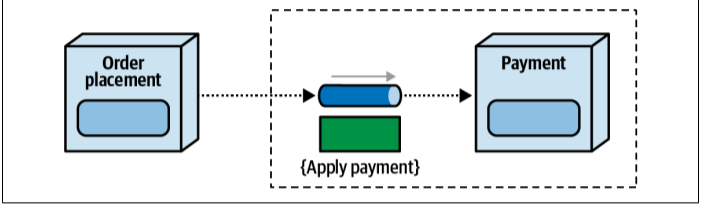
With messages, the receiver owns the message channel and
contract
With events*, you say “I placed an order.” You don’t care who listens.
With **messages**, you say “Ship this item” — and expect a response.*
Microservices Architecture — Divide, Specialize, Conquer!
This is the dream team of services. Each does one thing well. Email? One service. Payments? Another. Wishlist? Yet another. Microservices architecture breaks down monolithic applications into small, independent services, each responsible for a specific business capability. Think of it as transforming a large, complex machine into a collection of specialized tools that work together.
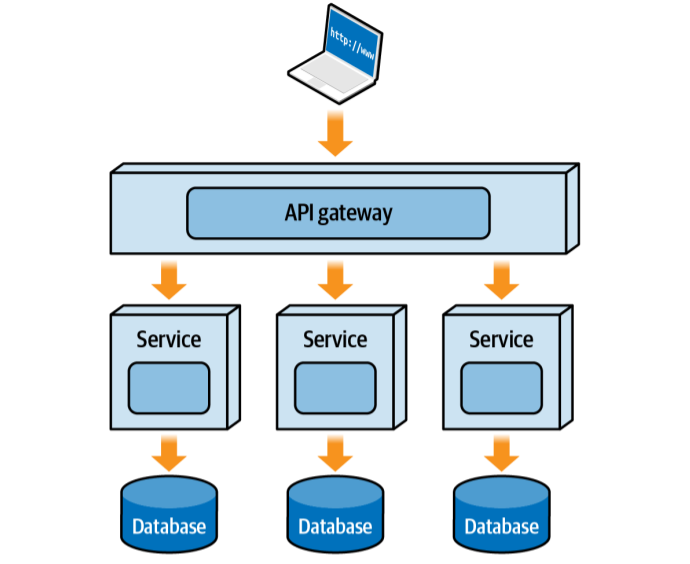
Topology of the microservices architecture style
Bounded Context:
Each service typically owns its own data, meaning that the tables belonging to a particular service can only be accessed by that service. For example, a Wishlist service might own its corresponding Wishlist tables. If other services need Wishlist data, those services will have to ask the Wishlist service for that information rather than accessing the Wishlist tables directly.
API Gateway Pattern
The API Gateway serves as the single-entry point for client requests, acting as a reverse proxy that:
Routes requests to appropriate microservices
Handles cross-cutting concerns like authentication and authorization
Collects metrics and handles rate limiting
Manages API versioning and documentation
🛠️ How it works:
A client hits the API Gateway.
Gateway routes to the appropriate service (but doesn’t do any business logic).
Each service owns its bounded context and its data.
Want to talk to another service’s data? You have to ask it, not access it.
Don’t use this if your data is tightly coupled and can’t be split easily. You’ll run into a wall of latency:
Network latency — Amount of time it takes for the data packets to reach the target service over the network. Can vary between 30 MS to 300 Ms.
Security latency — Amount of time it takes to authenticate or authorize the request to the remote endpoint. can vary between 300ms to more.
Data latency — Amount of time it takes for other services to query data on your behalf that you don’t own.
Space-Based Architecture — When You Need to Go Interstellar
Built for massive, unpredictable workloads, this architecture ditches the database for in-memory processing across multiple nodes — kind of like Iron Man suits working in sync.
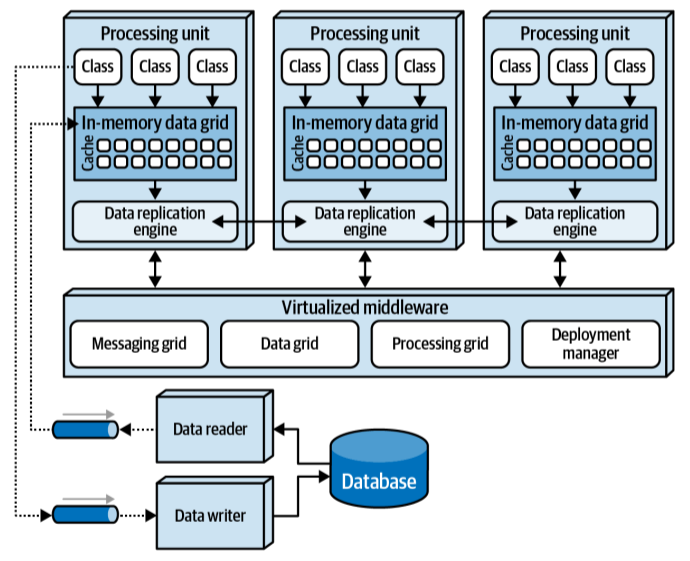
The space-based architecture style
Key Components:
Processing Unit (PU): It contains the business logic, an in-memory data grid containing transactional data. They can be dynamically started up and shut down as user load increases or decreases, thereby addressing variable scalability. Since there is no DB involved in the transactional processing of the system it provides infinite scalability. Services in this architecture is formally referred as processing units. Processing units may also communicate with each other directly or via virtualized middleware.
Virtualized middleware: Middleware manages things as request and session management, data synchronization, communication and orchestration between processing units, and the dynamic tearing down and starting up of processing units to manage elasticity and user load.
Messaging grid: It manages input request and session information. So what it does is basically looks over all the PUs, and redirect to request to the active ones. It uses algo like round-robin or next-available that keeps track of which request is being processed by which PU.
Data grid: Interacts with the data replication engine in each PUs to manage the data replication between PUs when data update occurs. since messaging grid can forward the request to any PUs, it is necessary that each PUs contains the exact same data in it’s in-memory data grid as other PUs. This sync typically occurs asynchronously behind the scenes in the in-memory data grids.
Data pump: It is a part of Data grid that asynchronously sends the update to the DB. It is implemented via persistent queues using messaging and streaming. Components called data writers asynchronously listen to these updates and then in turn updates the DB.
Deployment manager: Manages the dynamic startup and shutdown of PUs based upon load condition.
In-memory Data Grid: Shared memory space where data is stored and accessed across PUs.
Data replication Engine: Ensures all data updates are propagated to other nodes for consistency.
How It Works (Step-by-Step)
User sends a request → Load balancer receives it.
Load balancer routes it to a suitable PU.
PU reads data from its in-memory store, processes the request.
If data needs to be persisted → it is written behind to a database.
PU replicates changes to other PUs to maintain eventual consistency.
Example — Ticket booking system where we aren’t sure how many concurrent requests will be there, in this case we will be needing very elastic system with a huge scale performance.
It’s super elastic and highly available*. Think: ticketing systems, bidding wars, flash sales — anywhere you expect a tsunami of users.*
🏁 Final Thoughts — Choose Wisely, Architect Boldly!
Each architecture pattern has its place. It’s not about what’s trendy — it’s about what fits your system goals, your team size, and your future scale.
Your takeaways:
Start small. Think monolith if you’re MVPing.
Go distributed or microservices if you’re scaling fast and need flexibility.
Use event-driven when decoupling is king.
Go space-based when performance and elasticity are non-negotiable.
👋 Until Next Time…
That’s it for today’s deep dive into the world of software architecture.
We’ve got more tech wisdom, real-world breakdowns, and fire content coming your way.
Catch you in the next post — until then, stay curious, stay building, and stay updated! 🚀
Subscribe to my newsletter
Read articles from Pratyush Pragyey directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by