Prototyping Smarter with Aspire, Ollama & GitHub Models
 Jorge Castillo
Jorge Castillo
That’s exactly what I set out to do—transforming a single-provider AI demo into a flexible, production-like playground that supports local models with Ollama, and remote models with GitHub Models and Azure AI Foundry deployments. Along the way, I experimented with model orchestration, tool support, plugins, and a dynamic provider switcher—all while learning a ton and pushing my productivity further.
In this post, I’ll walk you through what I built, what worked (and what didn’t), and why this turned into one of my most exciting AI automation experiments yet.
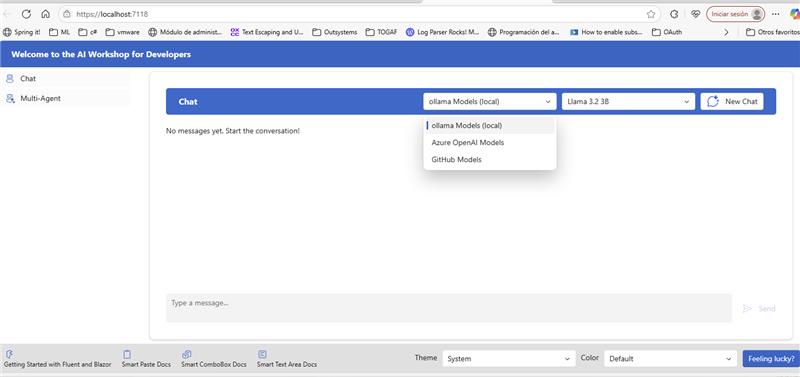
🌐 Multi-Provider, One Kernel: Why Settle for Less?
The original AI Developer Workshop provided a solid foundation for working with .NET Aspire and AI agents—but it was locked to a single model provider.
So I refactored the kernel configuration to support dynamic model switching, allowing the user to toggle between:
Local Ollama-based models (e.g.
llama3.2:3b,qwen3:8b)Remote GitHub-hosted models via OpenAI-compatible endpoints
Azure AI Foundry deployments with enterprise-grade infrastructure
Here’s the core logic powering the switch:
switch (currentProvider)
{
case Provider.Local:
kernelBuilder.AddOllamaChatCompletion(selectedModel, new Uri(ollamaApirUrl));
break;
case Provider.Remote:
kernelBuilder.AddAzureOpenAIChatCompletion(
deploymentName: azureModelName,
endpoint: new Uri(azureEndpoint),
apiKey: azureKey);
break;
case Provider.GitHub:
kernelBuilder.AddOpenAIChatCompletion(
modelId: githubModelName,
endpoint: new Uri(githubEndpoint),
apiKey: githubKey);
break;
default:
throw new InvalidOperationException("Unknown provider selected");
}
🔄 Why it matters: With this setup, I could A/B test models, validate fallback strategies, and explore performance trade-offs in real-time—no code changes needed.
🧠 Local Models with Tool Support? Tougher Than Expected.
Running LLMs locally has clear advantages—privacy, cost control, and the joy of offline AI. But finding a model that supports tool usage reliably? That took work.
My path:
✅
llama3.2:3b: Lightweight and quick for single-tool calls, but broke on multi-tool prompts.🔥
qwen3:8b: Surprisingly capable—handled multi-step toolchains in a single prompt with no issues.🧩 GitHub Copilot’s GPT-4o (remote): Zero problems, blazing fast, and great fallback when local wasn't enough.
Lesson learned: Not all local models are “agentic ready.” Test them like you would test any external service: with real-world tasks and failure conditions.
🧩 Real Plugins, Real Use Cases
To make conversations useful (not just clever), I build a set of simple semantic kernel plugins following the guide presented in the Workshop:
TimePlugin: Answers time/date-related questions.GeocodingPlugin: Converts place names into lat/lon coordinates.WeatherPlugin: Fetches current and historical forecasts via OpenWeatherMap.
Plugin registration was frictionless:
kernel.Plugins.AddFromObject(new WeatherPlugin(), "Weather");
🔌 Pro tip: Plugins are the secret sauce for turning LLMs into real-world agents. They give structure, context, and purpose to your AI prompts.
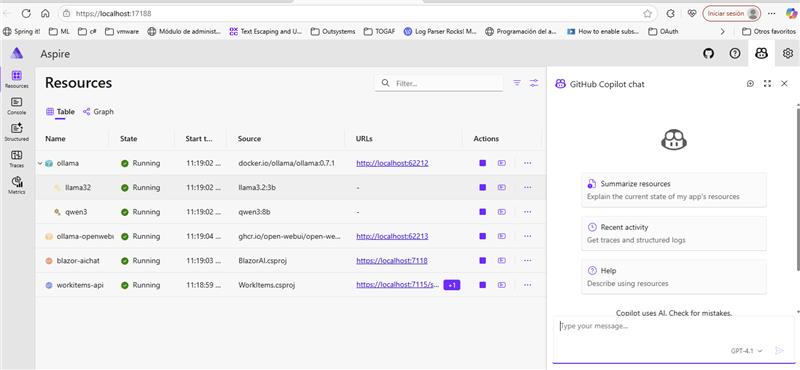
⚙️ Ollama + Aspire: An Unexpectedly Good Developer UX
I was curious about the new CommunityToolkit.Aspire.Hosting.Ollama package—and I’m glad I tried it. In just a few lines, I spun up GPU-backed containers with Open WebUI access and model preloading:
var ollamaService = builder.AddOllama("ollama")
.WithDataVolume()
.WithGPUSupport(OllamaGpuVendor.Nvidia)
.WithOpenWebUI();
ollamaService.AddModel("qwen3", "qwen3:8b");
Using Aspire’s dashboard, I could visualize dependencies, inspect logs, and even debug calls through GitHub Copilot integration. If you’re building local-first LLM services, this stack is a dream.
💻 GitHub Models: Fast Prototyping, No Vendor Lock-in
GitHub’s hosted models turned out to be perfect for prototyping. They speak the same API as OpenAI, so swapping backends was painless. Key benefits:
✅ No credit card required for dev/test.
✅ Fully OpenAI-compatible endpoints.
✅ Ideal for CI environments or demos.
🚀 Tip: Don’t underestimate hosted OSS models—they can save you hours and dollars during the exploration phase.
🛡️ Secrets, Logging, and Keeping It Clean
While AI was the star of the show, security and maintainability were never an afterthought:
Used
user-secretsandappsettings.Development.jsonfor sensitive values.Cleaned up
.gitignoreto avoid config leaks.Added usage docs and diagrams to
README.md.
🧼 Reminder: Productivity without hygiene is a debt trap. Automate config and document your architecture as you go.
🧪 GitHub Copilot: Still My Favourite Pair Programmer
From generating plugins to rewriting chat UX logic, GitHub Copilot was there every step of the way:
💡 Suggested API patterns and integration tricks.
🧠 Helped debug multi-provider setup quirks.
🪄 Wrote most of the boilerplate so I could focus on design.
Even with all the cool tools I’ve tested, Copilot remains my daily accelerator.
🔚 Final Thoughts: What I’ll Keep (and What I’ll Tweak)
🚀 What worked:
Dynamic provider selection made testing effortless.
Aspire + Ollama delivered solid local dev ergonomics.
Qwen3 + tools = big win for offline agentic workflows.
🧱 What needs improvement:
Tool-based prompting is still fragile with some models.
Add support for the chat output.
Implement stream chat support.
🗣️ Join Me in the Experiment
If you're building LLM-powered apps, don’t stop at the default examples. Push boundaries. Mix providers. Try weird models. Break things and rebuild them better. That’s how we move from “toy demos” to real innovation.
You can access the repository with the code of this article in https://github.com/jcastillopino/ai-developer-enhanced
Leave a comment or reach out—I'd love to hear about your own agentic setups.
Let’s keep building smarter. 🧠💻
Subscribe to my newsletter
Read articles from Jorge Castillo directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Jorge Castillo
Jorge Castillo
I’m a seasoned software architect and technical leader with over 20 years’ experience designing, modernizing, and optimizing enterprise systems. Lately I’ve been harnessing large language models—integrating agents like GitHub Copilot, Cline, and Windsurf—to automate workflows, build n8n and VS Code extensions, and power custom MCP servers that bring generative AI into real-world development. A cloud-native specialist on Azure, I’ve architected scalable, resilient microservices solutions using Service Bus, Cosmos DB, Redis Cache, Functions, Cognitive Services and more, all backed by DevOps pipelines (GitHub Actions, Azure DevOps, Terraform) and strict IaC practices. Equally at home crafting UML diagrams, leading multidisciplinary teams as CTO or tech lead, and championing agile, TDD/BDD, clean-architecture and security best practices, I bridge business goals with robust, future-proof technology solutions.