AI Model Compression Techniques for Cost-Efficient Cloud Deployment
 Tanvi Ausare
Tanvi AusareTable of contents
- The Need for Model Compression in Cloud AI
- Core AI Model Compression Techniques
- Combinational Compression: Maximizing Efficiency
- Compression Techniques vs. Model Size and Accuracy
- AI Model Compression for Cloud and Edge Deployment
- Deploying Compressed Models on NeevCloud
- Best Practices for Model Optimization and Deployment
- Efficient LLM Deployment on Cloud
- Low-Power AI Deployment Strategies
- Summary Table: Compression Techniques Comparison
- Conclusion: The Future of Cost-Efficient Cloud AI

AI model compression is redefining cloud AI by making large-scale deep learning faster, cheaper, and more sustainable. Using techniques like pruning, quantization, and knowledge distillation, organizations can reduce GPU costs, cut inference latency, and deploy models seamlessly across both cloud and edge. Platforms like NeevCloud empower businesses to scale compressed models on top GPUs, making compression the backbone of cost-efficient AI.
TL;DR: Why AI Model Compression Matters in Cloud AI
Shrinks models to cut GPU costs, latency, and energy use
Core methods: Pruning, Quantization, Knowledge Distillation, Hybrid
Enables faster, scalable, edge-ready AI deployment
NeevCloud simplifies deployment with top GPUs & AI SuperCloud
Benefits: cost savings, near-original accuracy, green AI efficiency
Future: Compression will be the foundation of cloud & edge AI
The rapid growth of artificial intelligence (AI) and deep learning has revolutionized industries, but it has also brought significant computational and financial challenges, especially when deploying large-scale models on the cloud. As organizations strive for cost-efficient, scalable, and high-performance AI solutions, AI model compression has emerged as a critical strategy for optimizing deep learning models for cloud deployment. This article explores the landscape of model compression techniques, their impact on cloud AI infrastructure, and how providers like NeevCloud are enabling efficient, affordable, and scalable AI deployments with cutting-edge GPU resources.
The Need for Model Compression in Cloud AI
Deep learning models, particularly those powering advanced applications like language models, computer vision, and recommendation systems, are often massive, with millions or even billions of parameters. Deploying such models on the cloud, especially at scale, can lead to:
High GPU and storage costs
Increased inference latency
Elevated energy consumption
Barriers to deploying AI on edge devices or in low-power environments
AI model compression addresses these challenges by reducing model size and computational requirements while maintaining accuracy, enabling cost-efficient deep learning on cloud and efficient AI inference across diverse platforms.
Core AI Model Compression Techniques
Let’s explore the most impactful model compression techniques for cloud deployment and their role in optimizing deep learning models for low-latency, cost-effective inference.
1. Pruning in Deep Learning
Pruning is a neural network compression technique that removes redundant or less significant parameters (weights, neurons, filters, or even entire layers) from a trained model. By eliminating these components, pruning creates a sparse, lightweight model that requires less computation and memory, directly reducing cloud GPU costs and improving inference speed.
Types of pruning:
Weight Pruning: Sets insignificant weights (often close to zero) to zero.
Neuron Pruning: Removes entire neurons that contribute minimally.
Filter Pruning: Discards less important filters in convolutional layers.
Layer Pruning: Removes entire layers if they are deemed unnecessary.
Workflow:
Train a baseline model to convergence.
Apply a pruning criterion (e.g., magnitude of weights).
Remove selected components.
Fine-tune the pruned model to recover accuracy.
Benefits:
Reduces model size and computational cost
Enables faster inference and lower latency
Directly reduces GPU and storage costs in the cloud
Makes models suitable for edge deployment
Example:
A ResNet model can have up to 30% of its convolutional filters pruned with minimal accuracy loss, followed by retraining to restore performance.
2. Quantization in Machine Learning
Quantization reduces the precision of model weights and activations, typically from 32-bit floating-point to 8-bit integers or lower. This significantly decreases the memory footprint and computational requirements, making it ideal for both cloud and edge deployments.
Types of quantization:
Static Quantization: Applies during training; quantization parameters are fixed.
Dynamic Quantization: Applies during inference; quantization parameters adapt to input data.
Benefits:
Reduces model size (up to 4x or more)
Accelerates inference by leveraging integer arithmetic
Lowers memory and bandwidth usage
Enables deployment on resource-constrained devices
Quantization vs. Pruning:
While pruning removes unnecessary parameters, quantization reduces the precision of those that remain. Combining both can yield highly compressed, efficient models.
3. Knowledge Distillation
Knowledge distillation compresses large, powerful models (teacher models) into smaller, faster student models without significant loss in performance. The student model is trained to mimic the outputs of the teacher, capturing essential knowledge in a more compact architecture.
Distillation techniques:
Response-based: Student learns from the teacher’s soft predictions.
Feature-based: Student mimics intermediate representations.
Relation-based: Student captures relationships between data points as learned by the teacher.
Benefits:
Produces lightweight models with near-teacher accuracy
Reduces inference time and cloud resource usage
Facilitates deployment on both cloud and edge devices
4. Low-Rank Factorization and Hybrid Approaches
Low-rank factorization decomposes large weight matrices into smaller, low-rank components, further reducing model size and computation. Additionally, hybrid approaches combine pruning, quantization, and distillation for maximum compression and efficiency.
Combinational Compression: Maximizing Efficiency
Recent research and industry practice show that combining multiple compression techniques can achieve greater cost and performance benefits than using any single method. For example, pruning followed by quantization can reduce FLOPs by over 50% with negligible accuracy loss. Advanced strategies like Deep Compression and Deep Hybrid Compression Networks leverage all three core techniques—pruning, quantization, and knowledge distillation—for state-of-the-art efficiency.
Compression Techniques vs. Model Size and Accuracy
Below is a conceptual graph illustrating the trade-off between model size reduction and accuracy retention for different compression techniques:
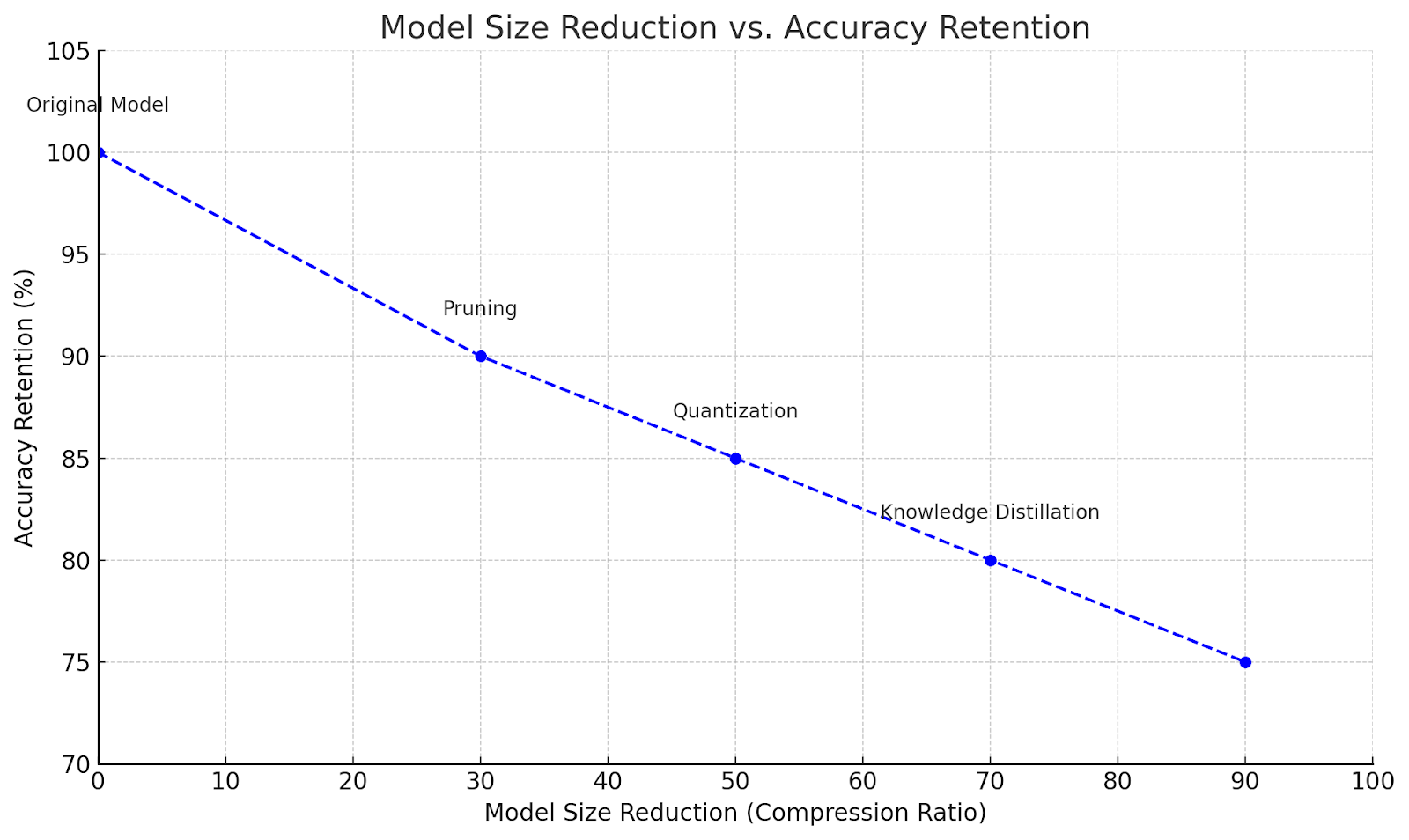
Original Model: Baseline, uncompressed
Pruning: Moderate size reduction, minor accuracy loss
Quantization: Significant size reduction, minimal accuracy loss
Knowledge Distillation: High compression, accuracy close to original
AI Model Compression for Cloud and Edge Deployment
Benefits for Cloud AI Infrastructure
Deploying compressed AI models on cloud GPU clusters—like those offered by NeevCloud’s AI SuperCloud and AI SuperCluster—delivers:
Lower GPU costs: Smaller models require fewer GPU hours and less memory, directly reducing operational expenses.
Faster inference: Compressed models process requests more quickly, improving user experience and throughput.
Scalability: Efficient models enable serving more users or workloads per GPU, maximizing infrastructure utilization.
Energy savings: Reduced computation translates to lower power consumption, supporting green AI initiatives.
Benefits for Edge AI Deployment
Low-power operation: Essential for deploying AI on edge devices with limited battery or compute resources.
Offline capability: Smaller models can run locally without cloud connectivity.
Real-time performance: Reduced latency for time-sensitive applications.
Deploying Compressed Models on NeevCloud
NeevCloud provides a robust, scalable, and cost-effective platform for deploying compressed AI models. With access to the latest NVIDIA GPUs (including H200s and GB200 NVL72), organizations can leverage NeevAI tools to:
Seamlessly deploy and manage compressed models on Cloud GPU infrastructure
Scale workloads across the AI SuperCluster for high-throughput inference
Monitor and optimize resource utilization for maximum cost savings
Key features:
One-click deployment of compressed models
Bare-metal performance without infrastructure overhead
Distributed, fault-tolerant storage for model artifacts
Real-time utilization tracking and full API access
Best Practices for Model Optimization and Deployment
How to Compress AI Models for Cloud Deployment
Baseline Training: Train your deep learning model to high accuracy using full precision and architecture.
Apply Compression Techniques:
Start with pruning to remove redundant parameters.
Apply quantization to reduce precision.
Use knowledge distillation to train a compact student model.
Optionally, use low-rank factorization for further gains.
Fine-tune and Validate: Retrain or fine-tune the compressed model to recover any lost accuracy.
Benchmark: Evaluate model size, inference speed, and accuracy.
Deploy on Cloud GPU: Use platforms like NeevCloud for scalable, cost-effective deployment.
Monitor and Optimize: Continuously monitor performance and costs, iterating as needed.
AI Model Optimization Tools
Many open-source and commercial tools support compression and deployment, including:
TensorFlow Model Optimization Toolkit
PyTorch Quantization and Pruning APIs
ONNX Runtime for quantized inference
NeevAI deployment and monitoring tools
Efficient LLM Deployment on Cloud
Deploying large language models (LLMs) like GPT or BERT on cloud GPUs can be cost-prohibitive. By applying pruning, quantization, and distillation, organizations have achieved:
Up to 4x reduction in GPU memory usage
2-3x faster inference times
30-70% reduction in cloud GPU costs
Near-original accuracy for most tasks
Low-Power AI Deployment Strategies
Combine compression techniques for maximum efficiency
Deploy lightweight models on edge and cloud
Optimize for low-latency and high-throughput inference
Leverage cloud AI infrastructure for scalable, distributed workloads
Summary Table: Compression Techniques Comparison
| Technique | Model Size Reduction | Inference Speed | Accuracy Impact | Best Use Cases |
| Pruning | Moderate | Moderate | Low | General cloud/edge |
| Quantization | High | High | Very low | Edge, low-power, cloud |
| Knowledge Distillation | High | High | Very low | LLMs, cloud, edge |
| Hybrid (Combined) | Very high | Very high | Minimal | Large-scale, cost-sensitive |
Conclusion: The Future of Cost-Efficient Cloud AI
AI model compression is essential for cost-efficient, scalable, and sustainable AI deployments on the cloud. By leveraging advanced compression techniques—pruning, quantization, knowledge distillation, and hybrid approaches—organizations can dramatically reduce cloud GPU costs, accelerate inference, and enable AI on both cloud and edge devices.
Platforms like NeevCloud’s AI SuperCloud and AI SuperCluster empower companies to deploy compressed, optimized models at scale, unlocking new possibilities for innovation and growth. As deep learning continues to evolve, model compression will remain at the heart of efficient, accessible, and impactful AI solutions.
Subscribe to my newsletter
Read articles from Tanvi Ausare directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tanvi Ausare
Tanvi Ausare
Digital Marketer & Technical Writer at NeevCloud, India’s AI First SuperCloud company. I write at the intersection of technology, cloud computing, and AI, distilling complex infrastructure into real, relatable insights for builders, startups, and enterprises. With a strong focus on tech marketing, I simplify technical narratives and shape strategies that connect products to people. My work spans cloud-native trends, AI infra evolution, product storytelling, and actionable guides for navigating the fast-moving cloud landscape.