How Serverless Architecture Works — and How I Built One with AWS
 Shravani Gundaye
Shravani Gundaye
Designed by Freepik
What is serverless architecture ?
Applications run on servers. These servers need monitoring, and thus, people are assigned to provision them. Developers building applications have to invest time in managing the servers in addition to building the software that runs on them.
This is where serverless architecture comes into play.
A common misconception about serverless is that it means there are no servers. But that’s not entirely true — applications still need servers to run. So what does “serverless” really mean?
Modern technology gave rise to the term “serverless architecture,” which simply means there's no need for developers to provision or manage servers manually. Instead, the responsibility is taken over by cloud service providers. It includes server provisioning, hardware maintenance, software updates, etc.
Servers are still very much a part of the system. But when we choose a traditional server based architecture, we also take on several responsibilities, such as:
What size server is right for my application’s performance ?
How do I control access to my servers ?
How many servers should I budget for ?
When should I scale my servers up or down ?
And many more…
Difference between Traditional and Serverless models
| Traditional Model | Serverless Model |
| Server provisioning is done by developers or operations teams | Server provisioning is handled by cloud service providers |
| Higher cost overhead due to manual management and resource over-provisioning | Lower cost due to automatic scaling and pay-per-use billing |
| Example: Amazon EC2 (Elastic Compute Cloud) | Example: AWS Lambda |
Real-World Use Cases
Serverless architecture is commonly used for event-driven tasks. These tasks typically follow a sequence of three steps:
Event – A defined activity that occurs (e.g., file upload, user request, database update)
Trigger – The event triggers a serverless function
Action – The function executes a predefined action in response to the trigger
Here, the servers are automatically managed by AWS, so developers or operations teams don’t need to handle those tasks manually.
Example:
A user uploads a high-resolution image to an Amazon S3 bucket.
This upload is the event.
It triggers an AWS Lambda function.
The action performed by the Lambda function could be to preprocess the image (e.g., resize, compress, or analyze it) before storing it or passing it to another service.
Pros and Cons
Pros:
Automation – No need to provision or manage servers; tasks are handled automatically by the cloud provider.
Scalability – Automatically scales up or down based on demand, with no manual intervention required.
Developer Focus – Developers can completely focus on writing application logic, improving overall productivity.
Cons:
Limited Use Cases – Best suited for event-driven or short-lived tasks; not ideal for long-running processes.
Less Customization – Limited control over the underlying infrastructure compared to traditional server-based setups.
Reduced Control – Developers have less visibility and control over server behavior and performance tuning.
Implementing a Serverless Workflow with AWS S3 and Lambda
In this workflow, I am using Amazon S3 to invoke a Lambda function.
The following are the AWS Services used for the implementation : S3, IAM, Lambda, CloudWatch.

Major Steps :
S3 bucket
Lambda Function
Trigger
Test
Flow :
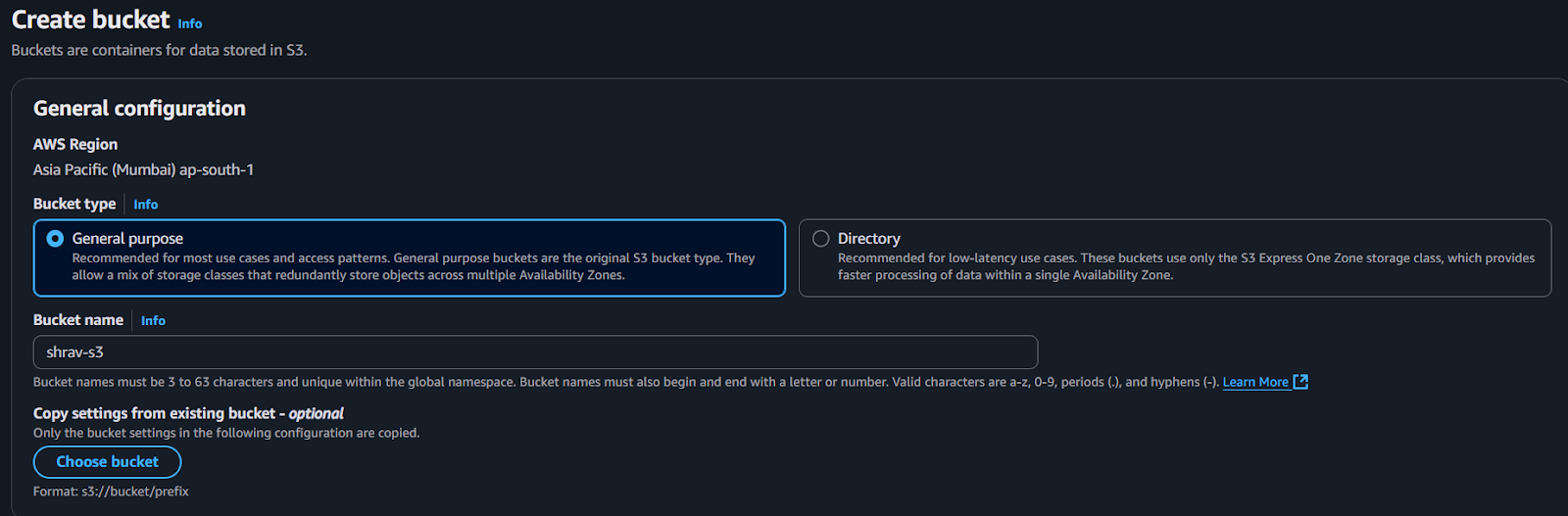
- Create an S3 bucket
Amazon S3 serves as the storage location for the objects. The files uploaded to S3 will trigger the Lambda function.
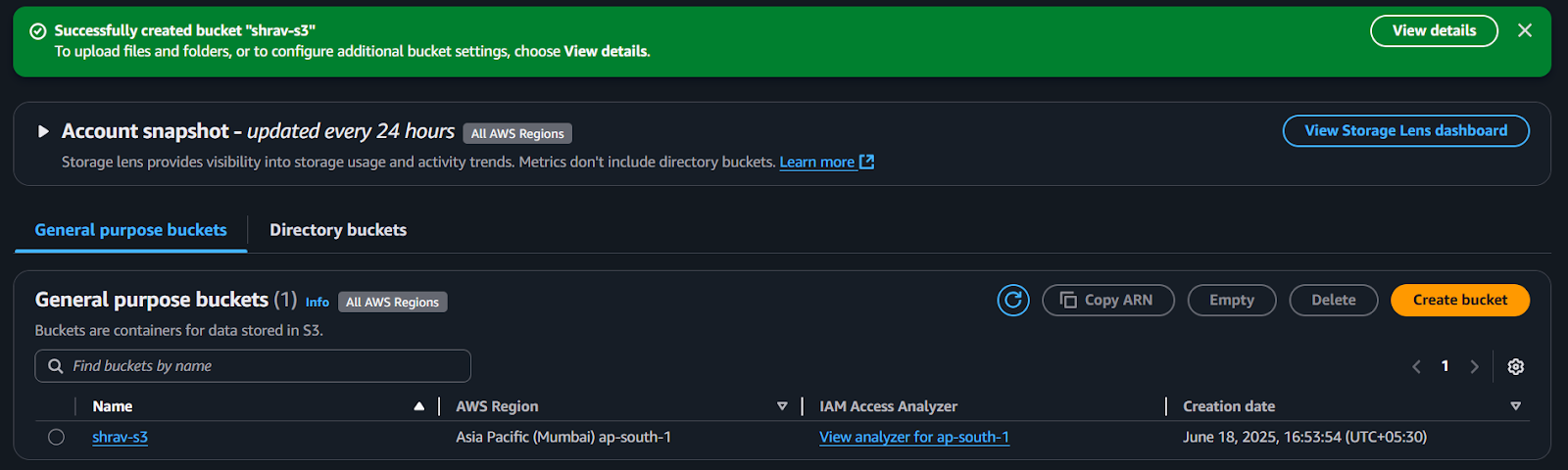
- Upload a test object to the bucket
It is crucial to have an object in the S3 bucket to test the Lambda function, initially with a dummy event.

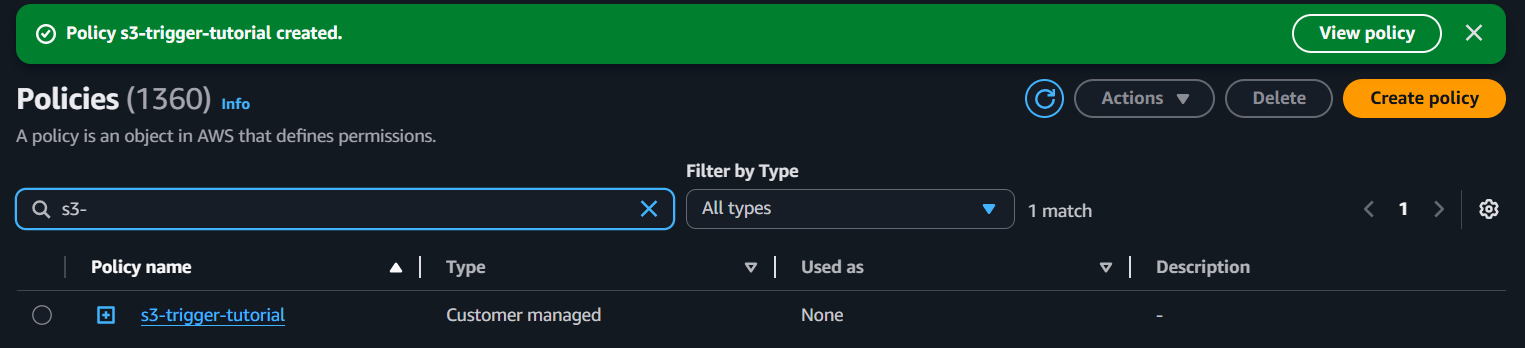
- Create a permissions policy
The Lambda function needs explicit permission to interact with other AWS Services. The policy defines the actions that the Lambda function is allowed to perform.
For instance, reading from S3 and writing log to CloudWatch.
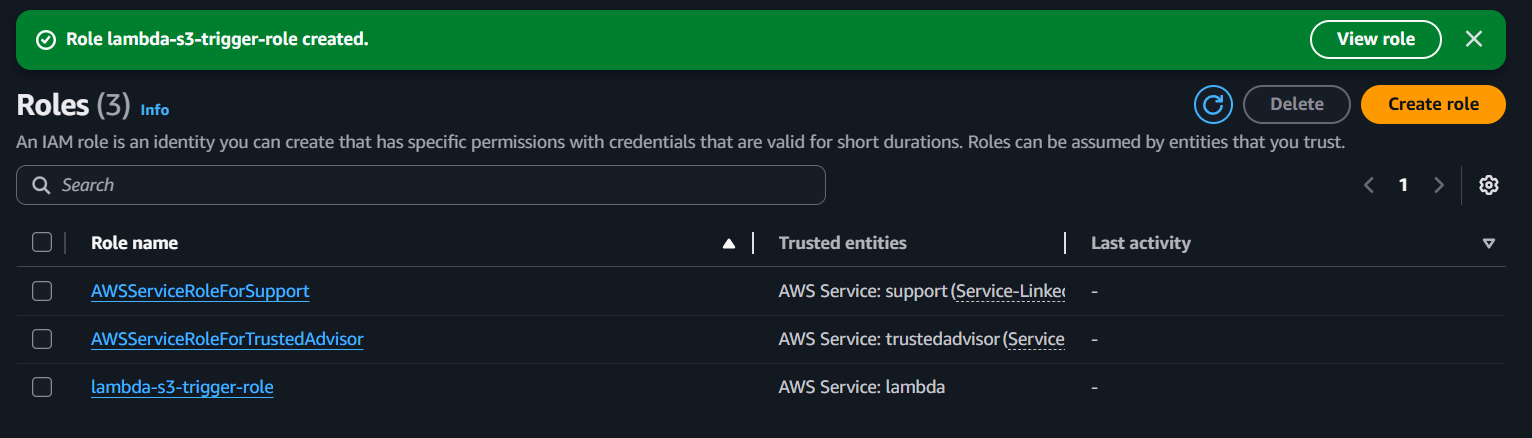
- Create an execution role
An execution role acts as the identity of the Lambda function. The policy created earlier is attached to this role, which gives the Lambda function the necessary permissions to securely interact with AWS resources.
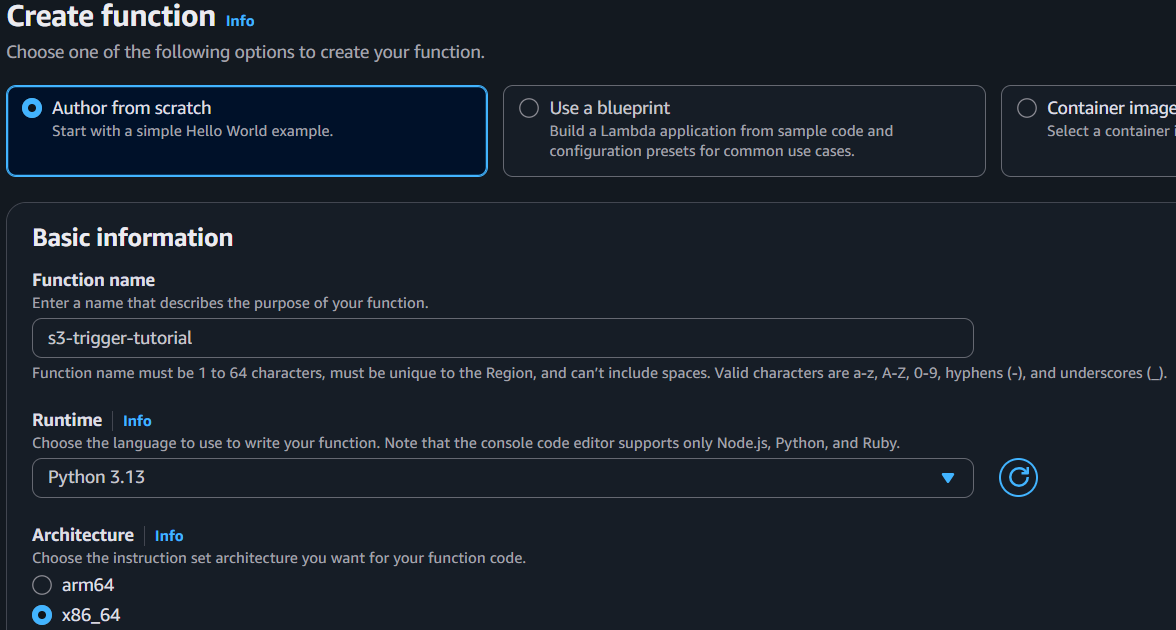
- Create the lambda function
This is the core compute service that will execute the custom code. It processes events and performs actions in response.

- Deploy the function code
This step uploads the actual code (in this case, Python Code) to the Lambda function. It contains the function logic that reads S3 object metadata when the Lambda is triggered.
# Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
# SPDX-License-Identifier: Apache-2.0
import json
import urllib.parse
import boto3
print('Loading function')
s3 = boto3.client('s3')
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event, indent=2))
# Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
response = s3.get_object(Bucket=bucket, Key=key)
print("CONTENT TYPE: " + response['ContentType'])
return response['ContentType']
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e
- Create the S3 Trigger
This trigger links the S3 bucket to the Lambda function. Whenever an action is performed (like object uploads), S3 sends an event notification to the Lambda function, thereby triggering it.

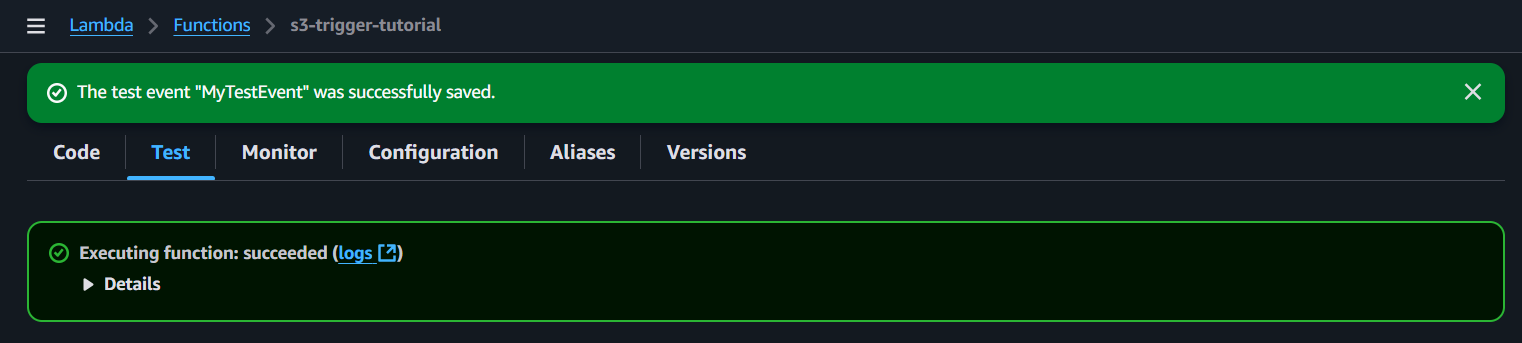
- Test Lambda function with a dummy event
A crucial debugging step that simulates an S3 event directly within the Lambda console. It provides feedback on whether the function’s code and permissions are working correctly before relying on the actual S3 trigger.
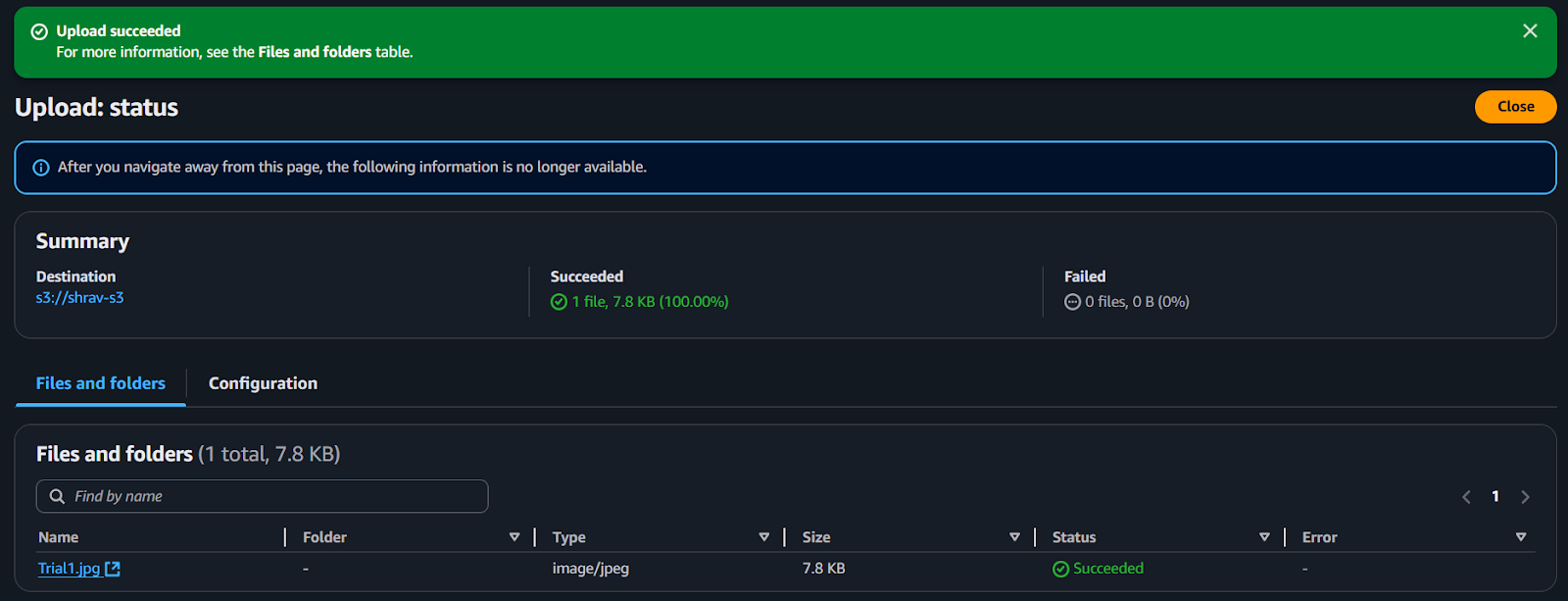
- Test the Lambda function with the Amazon S3 Trigger
The final step that ensures end-to-end flow is maintained. A new object is uploaded in the S3 bucket. It confirms that the S3 event notification is correctly sent and the function executes successfully.
- Observe the Log groups in Amazon CloudWatch
If everything is configured correctly, the following output is observed :

Conclusion :
I followed the official AWS guide for implementing this use case. You can check it out here for more technical details or alternate configurations.
My learnings from this project :
I understood the actual working of serverless architecture — while servers still exist, developers don't need to provision or manage them manually. That’s the core idea of "serverless."
I explored the benefits of using serverless: effortless scalability, automated execution, and improved developer productivity by reducing operational overhead.
I built and tested a real-world event-driven use case using AWS S3 and Lambda, where uploading a file automatically triggered a background process — no infrastructure setup required on my part.
Subscribe to my newsletter
Read articles from Shravani Gundaye directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Shravani Gundaye
Shravani Gundaye
Computer Engineering Student with experience in Python, AWS Cloud, and cybersecurity. Passionate about learning new technologies, problem-solving, and building secure and scalable solutions. Constantly improving my skills to stay ahead in the tech industry.