Snowflake’s Pipe operator, please meet my dbt workflow
 John Penek
John PenekThis May, Snowflake released the pipe operator which looks like this:
->>
Its promise? To revolutionize the CTE/subquery approach to SQL writing.
For those of you who are new to writing SQL, there are two competing paradigms in creating production level code: CTEs (common table expressions) and subqueries. To start, CTEs look like this:
with x as (
select * from table
),
y as (
select a few columns from x
),
z as (
select even fewer columns from y
)
select just the columns I want to display from z;
We can think of CTEs x y and z as their own tables minus the storage, the individual compute, and the mental burden of adding the objects table_x table_y and table_z. In the above query, I take every field in expression x and throw them in expression y, then take a subset of fields from y and put them in z, and finally take an even smaller sample of z and output those fields and records. The query reads top to bottom, like a book.
The downside? If there is a lot of computation happening in the query’s CTEs, then it will kick off every time the query is run. If a lot of window functions and aggregations are happening in x, it could take a long time to run the rest. Nothing is saved or even cached.
Some data leaders think that subqueries are always faster (even though subqueries also get re-run at runtime). A decade ago, I recall mentor architects stating that CTEs must “project the step-wise output to memory for the next CTE to capture”, but I do not think this is currently accurate, especially within today’s columnar architectures like Snowflake’s. Also, in my experience, Snowflake’s query optimizer makes the speed difference between paradigms negligible, and that claim is widely backed (here is a strong supporting article by Alisa in Techland).
Perhaps this theory arises simply because using subqueries means writing fewer lines:
select just the columns I want to display from (
--z
select even fewer columns from (
--y
select a few columns (
--x
select * from table
)
)
);
Shorter? Yes. But much harder to read. Instead of reading like a story, the first and outer-most query is the output, and the story starts in the middle of the query (here, it is with table). As subqueries get heftier, reading them becomes tougher.
So in Snowflake (and specifically as production-level code), CTE structure is the winner when it comes to simple reading and easy code maintenance. But why change what already works? What’s so interesting about Snowflake’s new pipe operator?
->>
The pipe is a flow operator that tells the next query to pull from the $n(th) expression before the current one. It makes the book format of a CTE even simpler, removing the extra words and commas. In our example query, we always pull the data in from the immediately preceding expression (1 step before: $1). Here is our example query re-written with pipes:
select * from table
->> select "a few columns" from $1
->> select "even fewer columns" from $1
->> select "just the columns I want to display" from $1
Immediately, the pipes make the SQL query quicker to read. Only relevant parts remain. It combines the top-to-bottom style of a CTE, and shortens line count even more than a subquery does.
You might be wondering about the significance of the $ , or if there are ways to select relative references out of order…
$
Historically, $ has been used in Snowflake as a column position reference. It is especially handy when doing CRUD commands (doing ETL) when the column names are inconsistent. For example, if some batches in a Snowpipe have different field headers, but we assert (and test) that the first column is always the first column no matter its name, then the following shortcut can be used to, in this case, select the first three columns:
select $1, $2, $3 from reference;
With Snowflake’s new release, in combination with the pipe, $ can reference an expression position reference, too. That said, when used carefully and strategically, we can do both:
select * from table
->> select $1, $2, $3 from $1 -- first three columns from above
->> select $1, $2 from $1 -- first two columns from above
->> select $1 from $1 -- first column from above
Reference order
Just like a CTE, we can select from any reference as long as that reference comes before the current select statement, and is validly formatted. Let’s use Snowflake sample data this time:
select * from snowflake_sample_data.tpch_sf1.customer
->> select $3::string as first_col, $4::string as second_col from $1
->> select $1::string, $2::string from $2
->> select * from $2 union all select * from $1
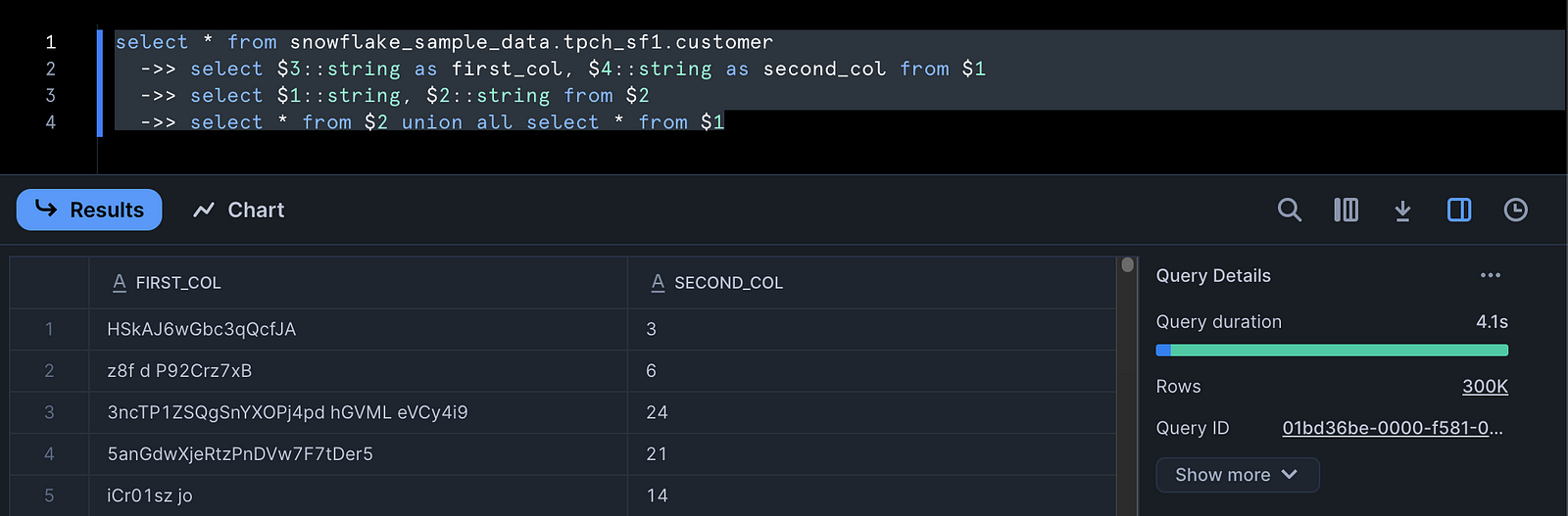
The above flow operation successfully unions all records in the first two fields with all records in the second two fields of the original table. As long as there is a ->> after a previous expression, it is fair game for referencing.
->> in dbt (hypothetically)
dbt is a data transformation tool that sits atop your data warehouse and pulls on the puppet strings of your data transformations. It lets you create new tables and views with simple select statements, and importantly, without exposing risk. Analysts do not need to worry about update statements, replacing or dropping tables, general RBAC or job orchestration (if handled correctly by us engineers). In any and every way, a robust dbt implementation streamlines the analyst’s workflow so they can focus on their job, minimizing production breaks.
In our discussion about new syntax releases, the most relevant feature of dbt is that it simply sends the query to the warehouse. This means if you are using Snowflake SQL in dbt, you can write whatever would compile directly in the Snowflake UI without issue.
To some’s surprise, however, ->> does not work in dbt. Here is why:
Both ->> and $1 are part of Snowflake's specific query-chaining syntax. This syntax only works in interactive queries, not in DDL (data definition language) statements like create table . But isn’t all of dbt just select statements? Well, yes. For the analyst. But under the hood, a model refactored with pipes:
{{ config(
materialized='view',
schema='intermediate'
) }}
select
customer_name,
customer_address,
customer_phone,
account_balance,
market_segment,
row_number() over (partition by market_segment order by account_balance desc) as rank
from {{ ref('stg_customer') }}
->>
select
market_segment,
customer_name,
account_balance
from $1
where rank = 1
->>
select
sum(account_balance) as total_balance,
listagg(customer_name, ', ') as customers
from $1
would compile to this:
create or replace transient table dev.dbt_jpenek_intermediate.int_highest_balance_by_segment
as (
select
customer_name,
customer_address,
customer_phone,
account_balance,
market_segment,
row_number() over (partition by market_segment order by account_balance desc) as rank
from dev.dbt_jpenek.stg_customer
->>
select
market_segment,
customer_name,
account_balance
from $1
where rank = 1
->>
select
sum(account_balance) as total_balance,
listagg(customer_name, ', ') as customers
from $1
)
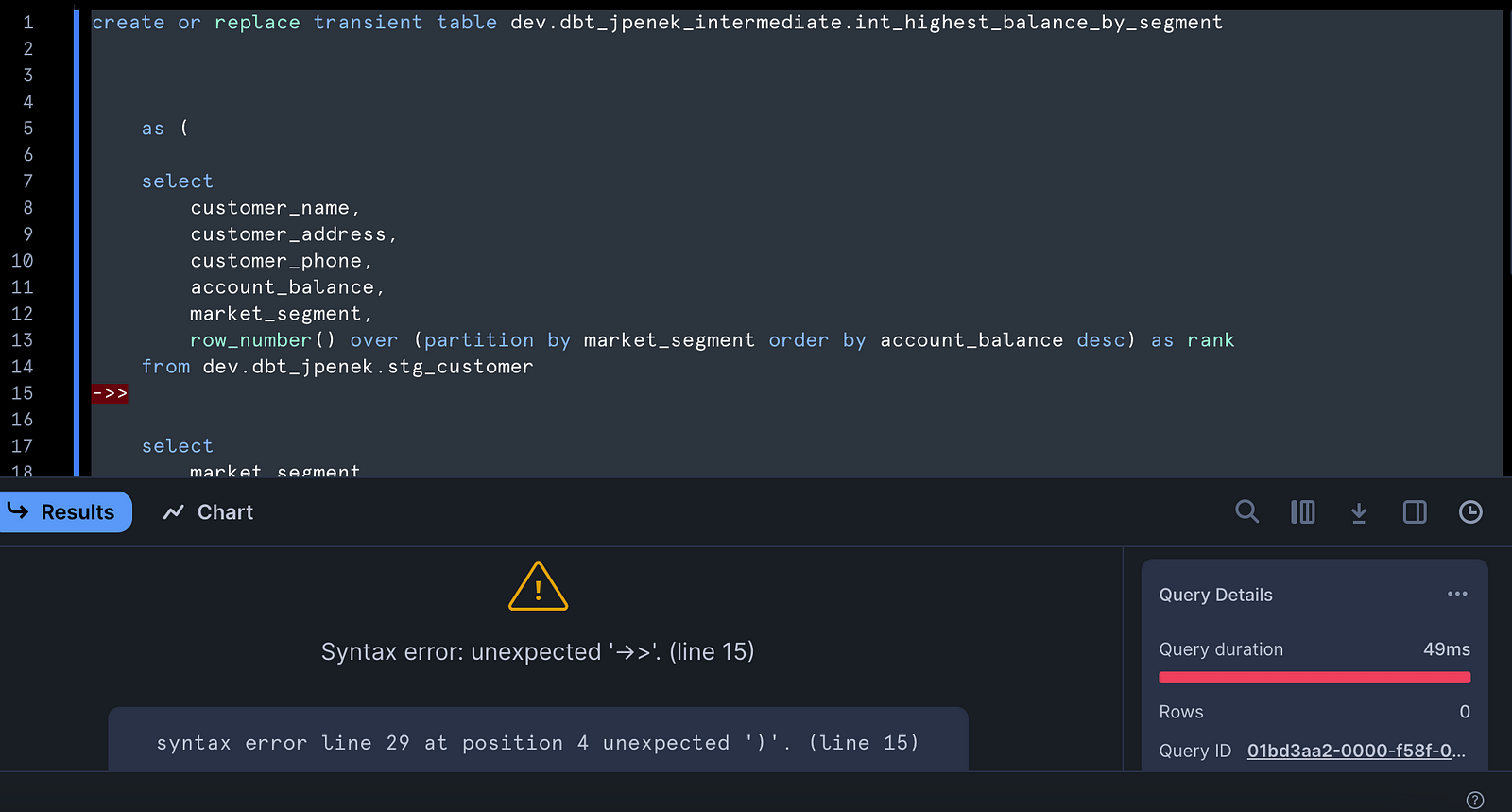
The create line at the top is DDL (defining a new table), and because Snowflake can’t process the chaining syntax, the statement fails:
Potential upside
Now, if using pipes were possible in dbt, we could reduce query line count on average by 3x, and in some cases, remove the need for all parentheses and commas. This would mean less dead white-space in repos, smaller diffs in pull requests, and fewer formatting discrepancies and SQL linter errors. But the upside does not stop there. It can also help unlock Snowflake object analytics.
Ever need another way to assert table freshness? Currently, to get information about a table’s last build, we would need to query Snowflake’s information schema, or look for changefeed timestamps. However, many enterprises lock down access to information schema, and tables downstream of source often do not propagate load timestamps. Fortunately, the pipe can interact with show commands too, and we can directly query table metadata. Let’s look at resources created today:
show views in database dev
->>
select *
from $1
where "created_on"::date = current_date::date

Again, in dbt, this type of query pattern could provide huge value. Here, we could more succinctly assert that downstream transformations are up to date (i.e. if Airflow or GitHub actions fail to notify that a task failed). Pipe compatibility in dbt would immediately unlock freshness cross-validation within the project.
So in sum, if Snowflake establishes pipe compatibility with DDL commands, this small symbol could pack a big punch when it comes to reducing tech debt, cleaning up a repo, and unlocking metadata analytics. Let’s all push for that follow-up feature enhancement from Snowflake.
Sources
Subscribe to my newsletter
Read articles from John Penek directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by