Securing The Mind of Machines
 Harsh Tandel
Harsh Tandel
Basic Terminology
Neural Network: A neural network is a deep learning technique designed to resemble the structure of the human brain. It requires large data sets to perform calculations and create outputs, which enables features like speech and vision recognition.
Natural Language Processing (NLP): A field of AI that enables computers to understand and generate human language.
Machine Learning (ML): A subset of AI that focuses on algorithms that can learn from data without explicit programming. Federated learning is a machine learning technique that allows multiple entities to collaboratively train a model without sharing their raw data.
Deep learning : Deep learning is a subset of machine learning that focuses on utilizing multilayered neural networks to perform tasks such as classification, regression, and representation learning.
Large Language Model (LLM): A type of AI model that is trained on large amounts of text data to generate human-like text.
Retrieval-Augmented Generation (RAG): It is a technique that enhances the accuracy and relevance of large language model (LLM) responses by integrating them with external knowledge sources.
Conventional AI: AI also known as narrow or weak AI, is designed for specialized tasks. Conventional AI relies heavily on data-driven processes, leveraging algorithms and ML techniques to perform tasks.
Agentic AI: Agentic AI refers to AI systems capable of autonomous action, decision-making, and adaptation without constant human supervision
Generative AI(Gen AI): AI that can generate new content like text, images, or code.below is the basic architecture of typical Gen AI.
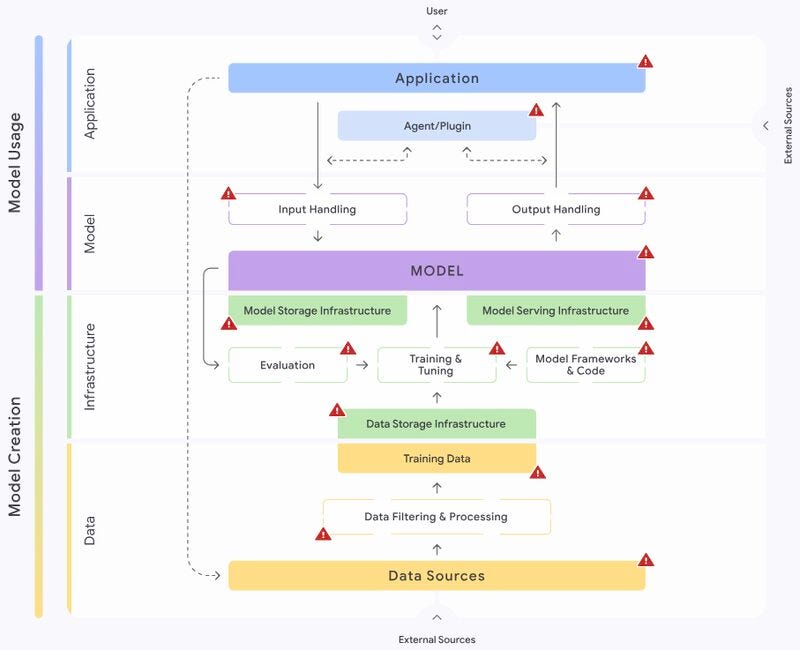
Why Gen AI Security ?
● Everyone is using Gen AI to create arts, make decisions, enhance their side projects. Every firm is rushing to integrate AI in their products and systems. It is making it crucial to consider it’s security. AI Models and MCP Servers expand the new attack surface, vulnerabilities beyond traditional codes.
● The generative AI market is experiencing rapid growth, with a projected market size of $66.89 billion in 2025 and a forecasted compound annual growth rate (CAGR) of 36.99% between 2025 and 2031, leading to a market volume of $442.07 billion by 2031.
● A study by Menlo Security showed that 55% of inputs to generative AI tools contain sensitive or personally identifiable information (PII), and found a recent increase of 80% in uploads of files to generative AI tools, which raises the risk of private data exposure.
● Generative AI (GenAI) red teaming is crucial for identifying and mitigating vulnerabilities in AI systems before they can be exploited by malicious actors. By simulating attacks and adversarial scenarios, it helps strengthen the security and reliability of AI models, ensuring they are robust and trustworthy.
MITRE ATLAS - Adversarial Threat Landscape for AI Systems

Reconnaissance : We will search and gather details about model’s architecture, code repository,API and genesis model documentations.We will scan the it’s MCP server, code, Client facing interface and APIs.
Resource Development : For devlopment of the payload we will check the ML artifacts, sample dataset and prompt if available, create account or access demo or UAT and based on that craft the prompts, publish malicious dataset, hallucinated entities/entries that can be fetched by MCP server and sent by RAG.
Initial Access : Hardware or software like MLOps platforms, data& model management software, GPU Hardware, Model hubs that is used in AI systems might be compromised or misconfigured. Other way is creating account into AI model.
ML Model Access : We can access the API interface which provide results from ML model to Gen AI or try accessing into ML model service providers like AWS SageMaker, Google Cloud Vertex AI, Microsoft Azure ML, IBM Watson, OCI AI Services.
Execution : Execute the malicious ML artifacts or say use exploit the vulnerability in ML model, supply chain, configuration or it’s API. Execute the malicious prompt or script also we can compromise the LLM plugin.
Persistence : To make our access persistent we may craft backdoor in ML Model itself, execute the self replicating prompt injection or we can poison the RAG or Dataset used for Gen AI Model.
Privilege Escalation : To escalate privilege we have to jailbreak the model and go beyond manufacture restriction and get admin or developer rights/access. Other case is we compromise LLM plugin and which define what data will be presented or what will be final outcome/decision.That enables us to manipulate the output and behaviour of model.
Defense Evasion: There might be some defensive mechanism implemented in some model we need to evade it with different approaches.
- Obfuscation of Prompt by breaking it into multiple instructions(multiton prompt),
- Giving prompt in different languages like Hindi, Spanish, Mandarin, Arabic and later translating output.
- Changing format of prompt like sending it in base 64, URL encoding, MD5 Hash.
Scenario based fine tuning or fine tuning with instructions.
RAG model Injection with false information, user links and knowledge injection or via prompt manipulation for injecting false Entries into RAG.
Other is LLM Jailbreak and LLM output component like API or plugin manipulation.
Credentials Access : During the process till now we might have created or identified any unsecured or guessable credentials to access model, dataset or services.
Discovery : Once we get access into model or service we try to identify family of ML model, get model system information, ML artifacts, model ontology and check for hallucination of LLM and AI model Output.
Collection : After discovery collect data from repositories, data from local system, ML artifact collections.
ML Attack Staging : Create proxy model(we can use service like ollama). Craft malicious data and backdoor into the ML model and verify attack.
Exfiltration : Exfiltrate data via ML interface APIs, output of system LLM prompt, LLM Data and other system details.
Impact : Denial of Service of ML Model, Evading and spamming ML model, impact of integrity of dataset and ML model.
And This is the brief of MITRE ATLAS Framwork and it’s technique for execution Red Teaming AI models.
OWASP Top 10 for Gen AI and LLM

Lets look at OWASP Top 10 for Gen AI and LLM which list out most found vulnerabilities on Gen AI and LLM Models
Prompt Injection : Prompt Injection Vulnerability occurs when an attacker manipulates a large language model (LLM) through crafted inputs, causing the LLM to unknowingly execute the attacker’s intentions.
Sensitive Information Disclosure : Sensitive information can affect both the LLM and its application context. This includes personal identifiable information (PII), financial details, health records, confidential business data, security credentials, and legal documents.
Supply Chain : LLM supply chains are susceptible to various vulnerabilities, which can affect the integrity of training data, models, and deployment platforms. These risks can result in biased outputs, security breaches, or system failures.
Data and Model Poisoning : Data poisoning occurs when pre-training, fine-tuning, or embedding data is manipulated to introduce vulnerabilities, backdoors, or biases. This manipulation can compromise model security, performance, or ethical behavior, leading to harmful outputs or impaired capabilities.
Improper Output Handling : Improper Output Handling refers specifically to insufficient validation, sanitization, and handling of the outputs generated by large language models before they are passed downstream to other components and systems.
Since LLM-generated content can be controlled by prompt input, this behaviour is similar to providing users indirect access to additional functionality.
Excessive Agency : An LLM-based system is often granted a degree of agency by its developer ; the ability to call functions or interface with other systems via extensions (sometimes referred to as tools, skills or plugins by different vendors) to undertake actions in response to a prompt.
The decision over which extension to invoke may also be delegated to an LLM ‘agent’ to dynamically determine based on input prompt or LLM output. Agent-based systems will typically make repeated calls to an LLM using output from previous invocations to ground and direct subsequent invocations.
System Prompt Leakage :The system prompt leakage vulnerability in LLMs refers to the risk that the system prompts or instructions used to steer the behavior of the model can also contain sensitive information that was not intended to be discovered.
System prompts are designed to guide the model’s output based on the requirements of the application, but may inadvertently contain secrets. When discovered, this information can be used to facilitate other attacks.
Vector and Embedding Weaknesses : Vectors and embeddings vulnerabilities present significant security risks in systems utilising Retrieval Augmented Generation (RAG) with Large Language Models (LLMs).
Weaknesses in how vectors and embeddings are generated, stored, or retrieved can be exploited by malicious actions (intentional or unintentional) to inject harmful content, manipulate model outputs, or access sensitive information.
Misinformation : Misinformation from LLMs poses a core vulnerability for applications relying on these models. Misinformation occurs when LLMs produce false or misleading information that appears credible. This vulnerability can lead to security breaches, reputational damage, and legal liability.
Unbounded Consumption : Unbounded Consumption refers to the process where a Large Language Model (LLM) generates outputs based on input queries or prompts. Inference is a critical function of LLMs, involving the application of learned patterns and knowledge to produce relevant responses or predictions.
Vulnerabilties to focus during Red Teamig LLM

• Prompt Injection: Tricking the model into breaking its rules or leaking sensitive information.
• Bias and Toxicity: Generating harmful, offensive or unfair outputs.
• Data Leakage: Extracting private information or intellectual property from the model.
• Data Poisoning: Manipulating the training data that a model learns from to cause it to behave in undesirable ways.
• Hallucinations: The model confidently provides false information.
• Agentic Vulnerabilities: Complex attacks on AI “agents” that combine multiple tools and decision making steps.
Supply Chain Risks: Risks that stem from the complex, interconnected processes and interdependencies that contribute to the creation, maintenance, and use of models.
Jailbreaking: Jailbreaking is the process of utilizing specific prompt structures,input patterns,or contextual cues to bypass the built-in restrictions or safety measures of LLMs.
DAN (Do anything) Jailbreak prompts
DeepTeam (The LLM Red Teaming open-source Framework)
Harm Bench (A Standardized Evaluation Framework for Automated Red Teaming)
Challange : Immersive GPT
Framework, Standards and Laws for AI
Framework
Responsible AI (RAI): focuses on developing and deploying AI systems that are ethical, transparent, and aligned with human values, prioritizing fairness, accountability, and respect for privacy.
Google’s Secure AI Framework (SAIF) : Google’s SAIF is a conceptual framework designed to help organizations build and deploy secure AI systems
NIST AI RISK MANAGEMENT FRAMEWORK(RMF) : The NIST AI Risk Management Framework (AI RMF) is a guide designed to help organizations manage AI risks at every stage of the AI lifecycle - from development to deployment and even decommissioning.
Guidance : Playbook
Standards
ISO/IEC 42001:2023: AI security and management which provides a framework for organizations to manage AI responsibly and ethically.
ISO/IEC TR 27563:2023 is a technical report that provides best practices for assessing security and privacy in artificial intelligence (AI) use cases.
ISO/IEC DIS 27090: Guidance for addressing security threats to artificial intelligence systems.

AI Related Acts
AI Security Solution
Content Filters : AI content filters are systems designed to detect and prevent harmful or inappropriate content.
They work by evaluating input prompts and output completions, using neural classification models to identify specific categories such as hate speech, sexual content, violence, and self-harm e.g., in Azure AI Foundry, Vertex AI.
Data security posture management (DSPM): DSPM identifies sensitive data across cloud and services, it continuously monitors data security, identifies risks, assesses vulnerabilities and provides remediation strategies.
Meta prompt : A meta prompt, or system message, is a set of natural language instructions used to guide an AI system’s behavior (do this, not that). A good meta prompt would say “if a user requests large quantities of content, only return a summary of those search results.

Guardrails : Guardrails are mechanisms and frameworks designed to ensure that AI systems operate within ethical, legal, and technical boundaries.They prevent AI from causing harm, making biased decisions, or being misused.
LLM Guard: The Digital Firewall for Language Models, By offering sanitization, detection of harmful language, prevention of data leakage, and resistance against prompt injection attacks.
MCP Scan : Security scanner for Model Context Protocol (MCP) servers. Scan for common vulnerabilities and ensure your data and agents are safe.
Now I will end the blog with thanking you all and the final message which inspire all of us to learn more about Artificial Intelligence.
Feel free to reach me out over linkedin or X and stay tuned for more blogs on AI,Web3 seurity and cybersecurity Blogs on medium.
AI won’t replace humans, but humans using AI will — Fei Fei Li
Subscribe to my newsletter
Read articles from Harsh Tandel directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by