RAG : Optimizing LLM's Response
 Garv
GarvTable of contents

✨Introduction
Retrieval Augmented Generation systems popularly known as RAG systems. RAG systems are the implementation of LLMs in one’s business usecase. It involves Indexing the data , fetching and feeding the relevant context data to the LLM and based on the context the LLM, which is capable of NLP, generates the response to the user’s query. A RAG pipeline not only answers the specific user query but also make the LLM be able to respond to data which is business specific, thus integrating AI with the business workflow
In this article you will understand how a RAG functions, what are its various steps involved in building a RAG and what are some popular, industry standard tools which aid in building RAGs.
❓What is RAG?
RAG stands for Retrieval Augmented Generation, it works on the following steps :
Chunking the data for better storage, access and retrieval
Indexing / Ingesting the data in a vector store or graph DB.
Retrieving the relevant chunks which best answer the user’s query.
Based on the relevant chunks feeded in the context window of the LLM, generating the optimal and apt response to the user’s prompt.
RAGs are dynamic, specific and unique to each business use case. Hence developing a functioning end-to-end RAG is complex and tricky ; and requires constant updation, re-evaluation and fitting to give best answers to the users. However, once a RAG pipeline is successfully implemented then the efficiency of tasks completion and the quality of response to the user’s query is greatly improved.
Now, before diving deeper into each step individually, let’s first clear “Why?” a RAG system is needed in first place and what alternate way can be used instead of RAGs and in what situations are RAGs best suited.
🤔Why & When RAG?
Is RAG system the only way to modify the LLM to answer specific user’s request? NO!; there is another way called as Fine Tuning. So then when to use when? Let’s answer this properly!
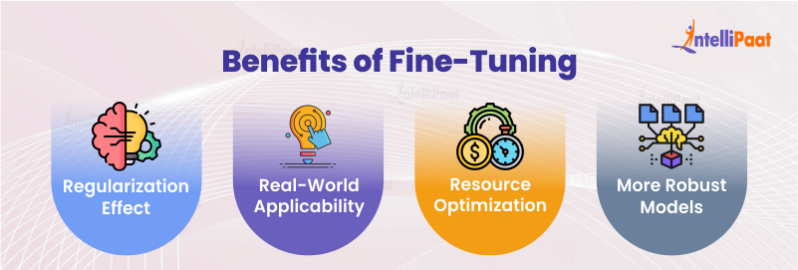
🧂Fine Tuning
As the name suggests, fine tuning is modifying the base model by training it further on your specific dataset. It is used when :
You need the model to internalize domain-specific language, tone or style.
You want faster inference without relying on external knowledge.
Your data is relatively static and not too large (or you can afford the cost to fine-tune on large data).
You need offline or on-device capability.

Effects of using Fine Tuning :
| Pros | Cons |
| Fast at runtime ( no retrieval step). | Expensive and time consuming to train. |
| More coherent and domain-specific outputs. | Hard to update - you must retrain for changes. |
| Works offline once fine-tuned. | Risk of overfitting or hallucinations if data is limited or biased. |
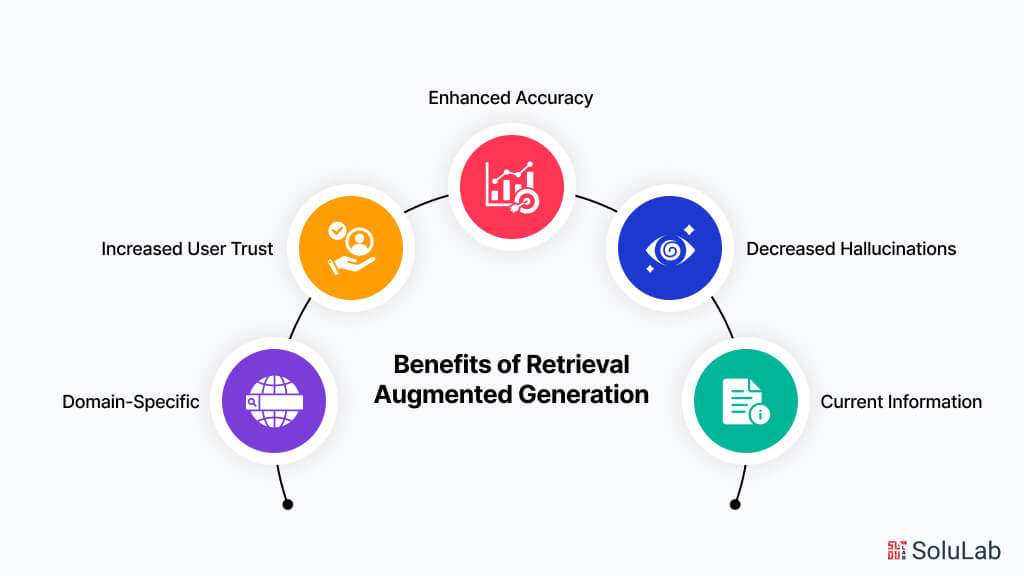
🧩RAG
RAG combines a language model with an external vector database that retrieves relevant documents to help generate responses. It is used when:
Your data is large, dynamic, or frequently updated.
You need transparency (can show sources).
You want better factual accuracy and up-to-date knowledge.
You’re working with FAQs, documentation, or enterprise data.
Effects of using RAG systems
| Pros | Cons |
| Easier to update ( just update the database) | Slower inference (retrieval adds latency) |
| More accurate and grounded responses. | More complex system (requires database, embeddings etc). |
| No model training required. | Model may not fully “understand” the domain language/style. |
🛠️Steps of RAG Systems Explained
🔍Indexing/ Ingestion
- It involves pre-processing of the data, storing it in the relevant format at the relevant database . Its processes are:
A. ✂️Chunking
- Splitting the knowledge data into appropriate size chunks such that is it neither too big for the context window of LLM to cause hallucinations in response or too small to miss out on important points while answering is very very important part of a RAG system.

B. 🧭Vector Embeddings
- After chunking, the data chunks are stored in vector embeddings format i.e. the the data are related to each other based on their semantic meanings. This aids in similarity search, feasible and easy access of the relavant data chunk(s).

C. 📦Storing : Vector Databases
- Now since the issue of what and how to prepocess the data ; the next important step is where to store the data chunks for easy retrieval, similarity search and many more features like also storing metadata; for that Vector Databases are used. Below are the various popular Vector DB Stores :

This completes the Ingestion/Indexing process of the external knowledge data. Now the RAG system is ready for user prompt.
🕵️Retrieval
Now after the user enters its prompt, the vector embeddings of the user’s query is created and the similarity search is performed on the pre-stored/ pre-organized data in the vector database and the most relevant chunks are retrieved as a result.

Now the LLM is all setup to do its magic.
📝Generation
- Now the LLM does the process of generating the appropriate response to the user’s query based on the context, of the most relevant chunks, it was feeded in its context-window.
![]()
🚀Advance RAGs
These three above mentioned steps are no way final, fixed and restrictive. As already mentioned above RAGs are dynamic, specific and unique to each business use case, so these steps can be modified, reused, remixed etc accordingly as the need is. For more information read my blog-series on Advance RAG Systems.
There are multiple types of RAGs commonly used in industry, you can refer to them in these articles : Article 1, Article 2
🧱 Core RAG Frameworks
🦜LangChain
An open-source framework (Python & JS) launched in Oct 2022, still the industry leader for RAG workflows.
Why it stands out: Modular architecture linking:
Document loaders
Text splitters
Embeddings
Vector stores (Chroma, FAISS, etc.)
Retrievers
Memory
LLMs
Ideal for versatile, production-grade chatbot pipelines.
📚LlamaIndex (formerly GPT‑Index)
Focused on data ingestion and indexing. Excels at structuring complex or multi-format (PDF, HTML, etc.) documents.
Strengths:
Sophisticated retrieval for heavy document pipelines
Integrates easily as a retriever within LangChain
👩💻Haystack (by deepset)
A powerful end‑to‑end framework (13.5k+ GitHub stars), built for enterprise use.
Features:
Modular drills with Elasticsearch / FAISS
Hugging Face readers
Multilingual support
Docker/Kubernetes deployment
High performance (balance between accuracy & speed)
👨🍳RAGatouille
One of the “top 5” RAG libraries.
Highlights: Simplifies RAG pipelines with easy-to-use interfaces.
🔗EmbedChain
Also on the top 5 list.
Use case: For integrating embedding & retrieval workflows quickly into apps.
⚡UltraRAG
Cutting‑edge toolkit (released Mar 2025):
Features:
Automated knowledge adaptation
Multimodal support
No-code Web UI
Best for: Low‑code path to production RAG.
🥊FlexRAG
Research-optimized toolkit (Jun 2025):
Designed for:
Flexible, async RAG
Text & multimodal
Caching
Ideal for researchers & prototyping
🎬Conclusion
Now that you have got a fair idea and intro into the world of RAG and Fine Tuning, practice and implement RAGs in your businesses and harness the power of AI Generation and NLP to enhance your user experience and productivity.
Subscribe to my newsletter
Read articles from Garv directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Garv
Garv
A person trying to learn and question things.