Advance RAG : Overview
 Garv
Garv
📝Introduction
Retrieval Augmented Generation (RAG) systems help in integrating AI capabilities with the business workflow and answer the user’s query; thus improving the business efficiency and user experience. Indexing/Ingestion, Retrieval & Generation are the three fundamental steps in building a RAG pipeline but in production grade these steps merely do not give the best, optimised output. For this Advance RAG comes into picture. In this article various tenets and features of Advance RAG will be introduced.
🤖What Is RAG?
Retrieval Augemented Generation systems popularly known by their acronym RAG, is an efficient way to collect external data, store it efficiently, retrieve the relevant chunks for context feeding to the LLM and answering the user’s query.
For more detailed explanation of RAGs check out this blog here.
🚀Why Advance RAGs Are Needed?
Mere Retrieval, Augmentation & Generation is not sufficient in handling large and scattered data ; neither is it production grade. For such purposes Advance RAGs are needed. Below are the problems that a simple/normal RAG fails to address effectively:
Lack of ability to handle sparse data, store and retrieve it efficiently.
Lack of ability to handle production grade challenges and difficulties.
Since user query is not in the hands of the developer, and often there is difference in what the user intends to ask and what the user actually asks , so modifying a user query gives more control to the developer to handle the LLM’s response otherwise LLM will respond just what the user asked i.e. Garbage In Garbage Out. Simple RAGs are unable to optimise user query.
📜Tenets of Advance RAG
Now since the need for Advance RAG is already discussed above, let’s look at the various tenets of what constitute Advance RAG.
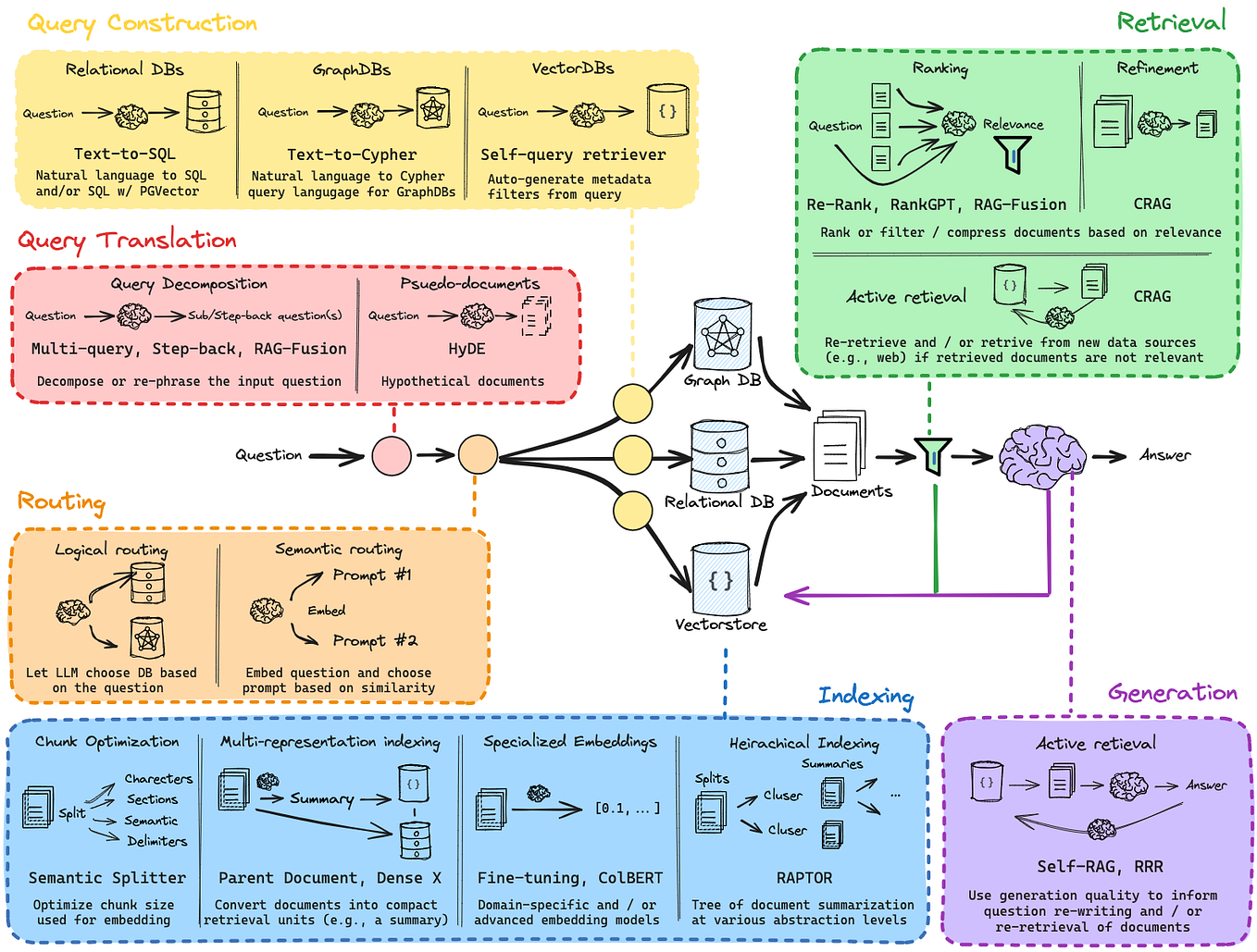
🔁Query Transformation/ Translation Patterns :
As already explained that user’s query is not in developer’s hand and if the user’s query is passed as it is to the LLM there might be difference in what was the output expected by the user and what the actual output is, and user query can be very abstract, too much detail, ambiguious, garbage - anything.
The default property of the LLM is to return the same output as user query, Garbage In Garbage Out
Query Transfomation/ Translation is optimizing the user query for and optimized response from the LLM. This not only ensures efficacy but also gives control to the developer to ensure that LLM responses are optimal.
Various Query Transformation/Translation Techniques are as follows:

🛣️Query Routing
Query routing is a system that intelligently directs an incoming query to the most appropriate data source or processor. Think of it as a traffic controller for data—when a user asks a question, the router analyzes the request, decides which database or service can best answer it, and forwards the query there. In modern architectures—like RAG (Retrieval-Augmented Generation) systems—there may be multiple indexes, structured databases, or APIs. The query router uses techniques such as semantic analysis or predefined rules (e.g., logical vs. semantic routing) to figure out:
A. Which data source to hit (e.g., customer database vs. product catalog).
B. What operation to perform (e.g., text search, summarize).
C. How to distribute the query across services (e.g., parallel calls, collated responses). This improves response accuracy, reduces wasted work, and scales better across large, distributed systems

To understand Query Routing in more detail see this article here.
🕸️Knowledge Graphs
A knowledge graph is a structured representation of real‑world entities (like people, places, things) and the relationships between them, organized as a directed graph. Each node represents an entity, each edge (relationship) connects two entities, and both can carry properties (attributes). Unlike tables in a relational database, knowledge graphs explicitly map meaning and context—e.g., “Alice → worksAt → AcmeCorp” or “Paris → capitalOf → France.” They often use ontologies to define schemas and enable richer logical inferences.
This structure makes it easier to:
Answer complex queries (e.g., "Who works in Paris for companies in France?")
Integrate data from multiple sources with shared semantics
Support AI tasks like reasoning or embeddings via graph neural nets.
Used widely in search engines, enterprise data platforms, and AI assistants, knowledge graphs power smarter data-driven decisions.

To understand Knowledge Graphs in more detail see this article here.
🔚Conclusion
Now through this article you would have got a fair overview and idea about how to optimize the response from the RAG pipeline. This article is the first of the series of articles, explaining each aspect of Advance RAG. If you want to continue reading, see the Advance RAG Series here.
Subscribe to my newsletter
Read articles from Garv directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Garv
Garv
A person trying to learn and question things.