When Jethalal Met GPT: A Hilarious Yet Deep Dive into the Internals of Generative AI
 Kunal Verma
Kunal VermaTable of contents
- A New Guest Arrives in Gokuldham — Meet GPT
- Jethalal the Developer, Taarak the Researcher
- From AI to GenAI — The Tech Pyramid of Gokuldham
- GPT Ka Postmortem – A Society-Level Investigation
- Tokenization – Breaking Sentences Like Society Notices
- Vector Embeddings – Gokuldham Personalities in Numbers
- 🧭 Positional Encoding – Word Order Matters
- 🔍Self-Attention – Who Focuses on Whom?
- 🔀 Multi-Head Attention – Different Brains in the Same Society
- Transformer Block – Gokuldham Society Ka Control Room
- 🧪Training – When Tapu Sena Learns from Mistakes
- 🎭Inference – When GPT Performs Like Jethalal on Stage
- 🕵️♂️ Tapu Sena Discovers the GPT Secret Vault

A world where Jethalal meets GPT. Where Babita ji unknowingly explains vector embeddings. Where Popatlal’s marriage story is just a token. Welcome to Gokuldham — the perfect lens to understand the world of GenAI.

A New Guest Arrives in Gokuldham — Meet GPT
One peaceful morning in Gokuldham Society, something unusual takes place.
Jethalal, enjoying his usual tapri-style chai, overhears Abdul talking to Sodhi. Abdul mentions that a new person has moved into the society, and his name is GPT.
As expected, Jethalal is confused. He wonders if GPT is an engineer or someone who has come from Bhopal.
Popatlal, always dramatic, jumps in and suggests that this might be another marriage scam.
Bhide, the rule-abiding secretary, adjusts his glasses and reminds everyone that, as per society rules, any new member must first fill out a registration form.
Just then, Taarak Mehta enters the scene calmly and clears the confusion. He explains that GPT is not a person, but an advanced AI model. It has learned from vast amounts of data across the internet and can generate new sentences from that knowledge. This, he explains, is what we call Generative AI.
And so begins our light-hearted yet insightful journey to understand what GPT truly is, as seen through the familiar and humorous world of Gokuldham Society.
Jethalal the Developer, Taarak the Researcher
Later that evening at the soda shop, Jethalal vents his frustration to Taarak. He says he only wants to know how to use GPT, not how it works internally. He claims he's a developer, not a scientist.
Taarak listens patiently and smiles. He explains that this is exactly the difference between developers and researchers. Jethalal, as a developer, is focused on using GPT to build apps and tools. Taarak, on the other hand, is a researcher — someone who is curious about how GPT functions under the hood.
And that, dear reader, brings us to our first core concept: the distinction between developers and researchers in the world of GenAI.
Developers are the ones who apply GenAI models like GPT in real-world applications. They work on building things like chatbots, AI-based search engines, productivity tools, and APIs. They don’t necessarily need to know how the model was trained or how the architecture works, but they do need to master how to use prompts effectively, how to fine-tune a model when needed, and how to integrate it into products.
Researchers, on the other hand, are the minds behind the creation of GenAI models. They focus on designing and understanding the inner workings — architectures like Transformers, the process of tokenization, embeddings, training loops, and much more. Their job is to make the models smarter, faster, more accurate, and less prone to hallucinations.
To put it in Gokuldham terms:
Jethalal is the Developer.
He just wants GPT to answer his questions or help him write emails to Babita ji.
Taarak Mehta is the Researcher.
He’s interested in how GPT understands language, learns patterns, and predicts the next word.
Both roles are essential. Just like Gokuldham society needs both Tapu Sena’s chaos and Bhide’s rulebook to function, the world of Generative AI depends on both developers who build with it and researchers who build it.
From AI to GenAI — The Tech Pyramid of Gokuldham
Back at the society’s meeting hall, Taarak Mehta arrives with a whiteboard in hand. Everyone is seated on plastic chairs. Even Bapuji is present, adjusting his hearing aid, ready to listen.
Taarak begins explaining with a simple analogy.
“Imagine that in Gokuldham, every person has a specific skill, and each skill builds on top of the previous one. The same way, in the world of Artificial Intelligence, there’s a hierarchy — like a tech pyramid.”
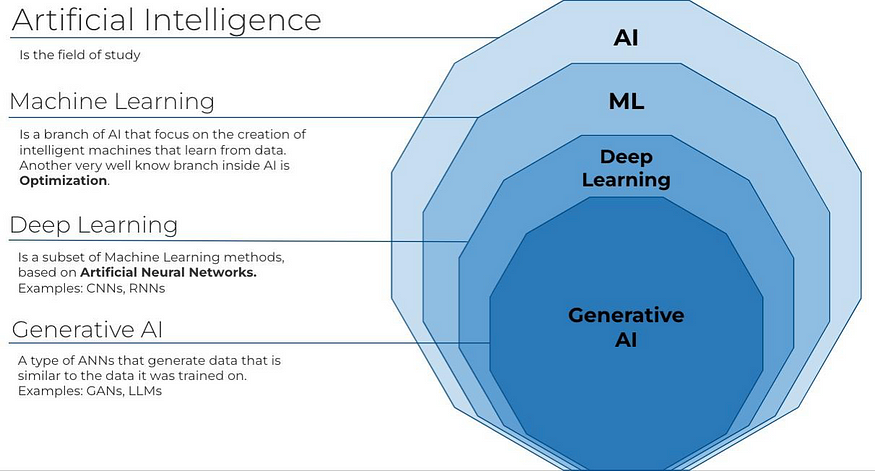
1. Artificial Intelligence (AI) – Like Bhide’s Rulebook
Artificial Intelligence is the broadest concept. It refers to any machine that mimics human decision-making — even if it doesn’t learn from data.
For example, if Bhide creates a rule that the society gate should close at 10 PM, and an automatic system locks the gate at 10:01 PM without needing to learn anything — that’s AI.
In technical terms:
AI includes rule-based systems and learning-based systems.
The behavior can be hardcoded, without the machine learning from data.
2. Machine Learning (ML) – Like Tapu Sena Learning from Mistakes
Machine Learning means giving data to a machine so it can find patterns on its own, instead of us writing rules manually.
For example, Tapu Sena eventually realizes that breaking Babita ji’s flower pot always leads to scolding. So over time, they (hopefully) stop doing it.
That’s supervised learning — where:
The model is trained on input-output pairs.
It learns the mapping from data over time.
Example:
Input: “Tapu Sena broke flower pot”
Output: “Scolding expected”
After seeing many examples, the model starts predicting outcomes from experience — like humans do.
3. Deep Learning (DL) – Like Everyone in the Society Thinking Together
Deep Learning is a type of Machine Learning that uses deep neural networks — with many layers.
Imagine not just Tapu Sena, but the whole society — from Iyer to Madhavi to Sodhi — all analyzing a situation, layer-by-layer, before reacting.
That’s what deep neural networks do.
In technical terms:
Early layers learn simple things like alphabets or edges.
Middle layers identify patterns like words or shapes.
Final layers understand meaning — like full sentences or objects.
This layered understanding is what makes Deep Learning powerful.
4. Generative AI (GenAI) – Like TMKOC Writers Creating New Episodes
Now we arrive at the star of the show: Generative AI.
While ML often just classifies or predicts outcomes, GenAI creates something entirely new — like text, images, music, or videos.
Imagine the TMKOC writing team. They’ve watched every past episode. But when they sit down to write a Diwali special, they create fresh dialogues, scenes, and jokes — even though they’ve never written them before.
That’s what Generative AI does.
Technically:
GenAI models are trained on massive datasets (like books, code, images).
They use architectures like Transformers (which we’ll explore soon).
They don’t just predict a label; they generate full sequences, like paragraphs or stories.
Some popular examples:
ChatGPT – generates human-like conversations.
DALL·E – generates images from text.
Copilot – writes code based on comments or partial inputs.
MusicLM – creates new music from prompts.
So when GPT entered Gokuldham, it wasn’t just acting smart like Bhide or learning like Tapu Sena.
It was generating new ideas — like the TMKOC writers brainstorming a new episode. That’s the power of Generative AI.
At this point, Bhide, still skeptical, raises his hand.
“All this sounds fine, Mehta sahab... but what exactly does GPT stand for?”
Taarak smiles and flips the whiteboard.
GPT Ka Postmortem – A Society-Level Investigation
🧬 Part 1: G = Generative – The Writer Inside the Machine
Let’s first understand what "Generative" really means.
Imagine GPT as a writer who has read every TMKOC episode, every Hindi newspaper, countless novels, memes, blogs — and now, when you give it a sentence, it continues the story in a way that sounds logical and creative.
For example, you might type:
“Jethalal went to Babita ji’s house and...”
GPT could complete it as:
“...accidentally broke Iyer’s solar panel again.”
The point is, GPT doesn’t just retrieve a sentence from memory. It generates a brand-new response based on what it has learned from millions of examples. It mimics the flow and rhythm of natural language.
Technically:
GPT doesn’t work from a fixed response database.
It predicts the next word (or token) based on the words before it.
It has been trained on billions of text sequences, learning how language is structured and how it flows.
That’s why it’s called “Generative” — because it creates something new each time, rather than just predicting a category or retrieving pre-written text.
📚 Part 2: P = Pretrained – Trained on the Entire Internet
Now let’s talk about the second part — “Pretrained.”
Taarak explains to Jethalal that GPT isn’t trained from scratch every time someone uses it. Instead, it was trained once on an enormous dataset, and now it simply uses that learned knowledge to answer questions and generate content.
It’s like Bapuji — he doesn’t re-learn life lessons every day. He learned over decades, and now he just shares his wisdom. That’s inference.
Technically:
GPT is trained once on a vast dataset (like Common Crawl, Wikipedia, books, StackOverflow, and more).
It uses self-supervised learning, where it learns by trying to predict the next word in a sentence.
After training is complete, it moves into inference mode, where it responds to prompts using its learned knowledge — just like Bapuji offering advice from experience.
So, “Pretrained” means the learning phase is already done — and what we interact with is the result of all that intense training.
🏗️ Part 3: T = Transformer – The Engine Behind Everything
Now comes the most powerful part — the “Transformer”.
Taarak describes it as the engine that powers GPT. It’s a type of neural network, but far more advanced than older models like RNNs or LSTMs.
Before Transformers, models struggled with long sentences and remembering earlier words. Transformers introduced self-attention, a mechanism that changed everything by allowing the model to focus on important parts of the input, regardless of their position.
Technically, a Transformer includes:
Token Embeddings – converting words into numbers
Positional Encoding – understanding the position of each word in a sentence
Multi-Head Self Attention – focusing on multiple parts of the sentence at once
Feed Forward Networks – processing each token’s information
Layer Normalization and Residual Connections – stabilizing and improving performance
These blocks are stacked — often 12, 24, or even 96 layers deep in large models
At this point, Iyer joins the discussion and asks:
“So you’re saying GPT works like a factory, with different internal departments — one for memory, one for context, one for attention?”
Taarak nods and confirms:
“Exactly. And to truly understand how GPT works step by step, we now need to follow what happens when it receives a sentence.”
Tokenization – Breaking Sentences Like Society Notices
Taarak now turns to the whiteboard and writes a simple sentence:
Sentence: Popatlal is not married.
He explains that GPT does not see this sentence as a whole. Instead, it breaks it down into smaller parts called tokens — just like how Bhide breaks down society members into flat-wise entries in his register.
🧱 What is a Token?
A token is the smallest unit of text that the GPT model can understand and process.
Depending on the tokenizer used, the sentence might be split like this:
[ "Pop", "at", "lal", " is", " not", " mar", "ried", "." ]
So, instead of treating "Popatlal" or "married" as one word, GPT splits them into parts based on how frequently those pieces appear in its training data.
📌 Technically Speaking:
GPT uses methods like Byte Pair Encoding (BPE) or WordPiece for tokenization.
A token might be:
A full word: like "not"
A subword: like "mar" and "ried"
Or even a character: in rare cases
GPT maintains a large vocabulary of 50,000 to 100,000 tokens.
Each token has a unique ID — like how Bhide assigns flat numbers to society members.
For example, GPT might internally map tokens like this:
"Pop" → 1456
"lal" → 2981
"mar" → 3409
"ried" → 5531
This dictionary helps GPT understand and convert words into a format that can be processed mathematically.
Taarak summarizes it by saying:
“Just like how Gokuldham notices every little thing — who came, who left, who said what — GPT also notices everything, but in the form of tokens. That’s how it starts understanding language.”

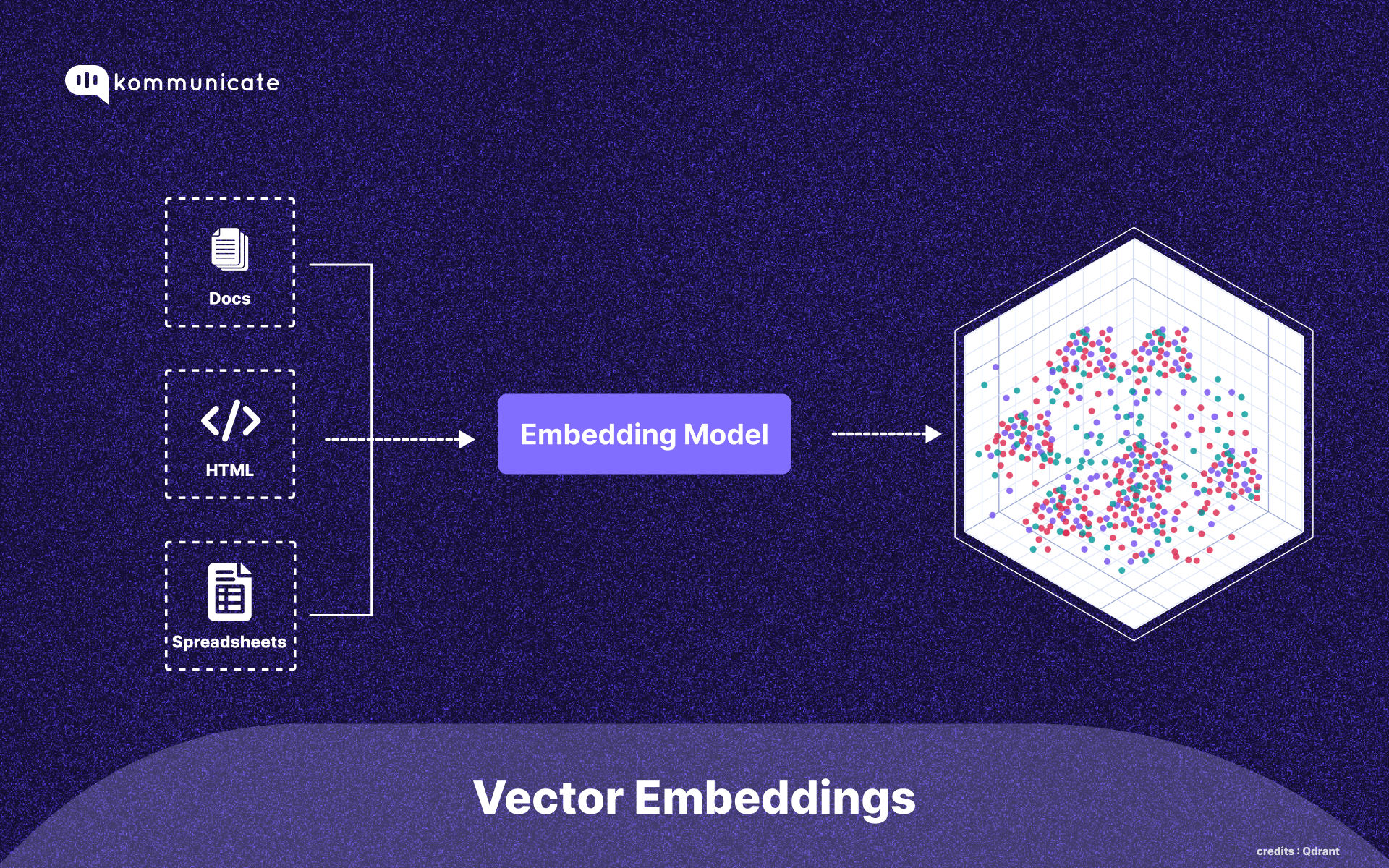
Vector Embeddings – Gokuldham Personalities in Numbers
After tokenization, each token is transformed into a vector embedding — a set of numbers that represent the meaning of that token in a high-dimensional space.
Taarak explains this using a simple analogy:
“Just like every Gokuldham member has a distinct personality, each token also gets its own ‘personality profile’ — in the form of a vector.”
Think of it like this:
Jethalal = [funny, confused, loud]
Iyer = [smart, technical, sarcastic]
Babita = [kind, intelligent, observant]
Similarly, tokens are represented like:
"Pop" → [0.91, -1.2, 0.03, ..., 0.78]
"mar" → [0.11, 1.03, -0.47, ..., 0.92]
These vectors don’t have labels like “funny” or “technical,” but they exist in hundreds or thousands of dimensions, capturing all sorts of semantic patterns that the model has learned from data.
📌 Technically:
These embeddings are learned during the pretraining phase.
Each word or token is placed in a mathematical space such that:
Similar meanings are placed closer together
Unrelated meanings are placed far apart
For example:
“happy” and “joyful” → their vectors are close together.
“Popatlal” and “married” → their vectors are extremely far apart (naturally 😄).
This helps the model understand relationships, emotions, and context, not just raw words.
Taarak summarizes it beautifully:
“GPT doesn’t understand words the way we do. It understands numbers — and through these vectors, it captures meaning, relationships, and even Gokuldham-style drama.”
🧭 Positional Encoding – Word Order Matters
At this point, Taarak drops another knowledge bomb.
He explains that while humans naturally understand the order of words in a sentence, Transformers don’t. They process all tokens simultaneously, not one by one.
So how does GPT know the order of words like:
“Jethalal scolds Bhide”
versus
“Bhide scolds Jethalal”?
Both sentences use the same words — but they mean very different things (and surely raise different levels of shock in Gokuldham!).
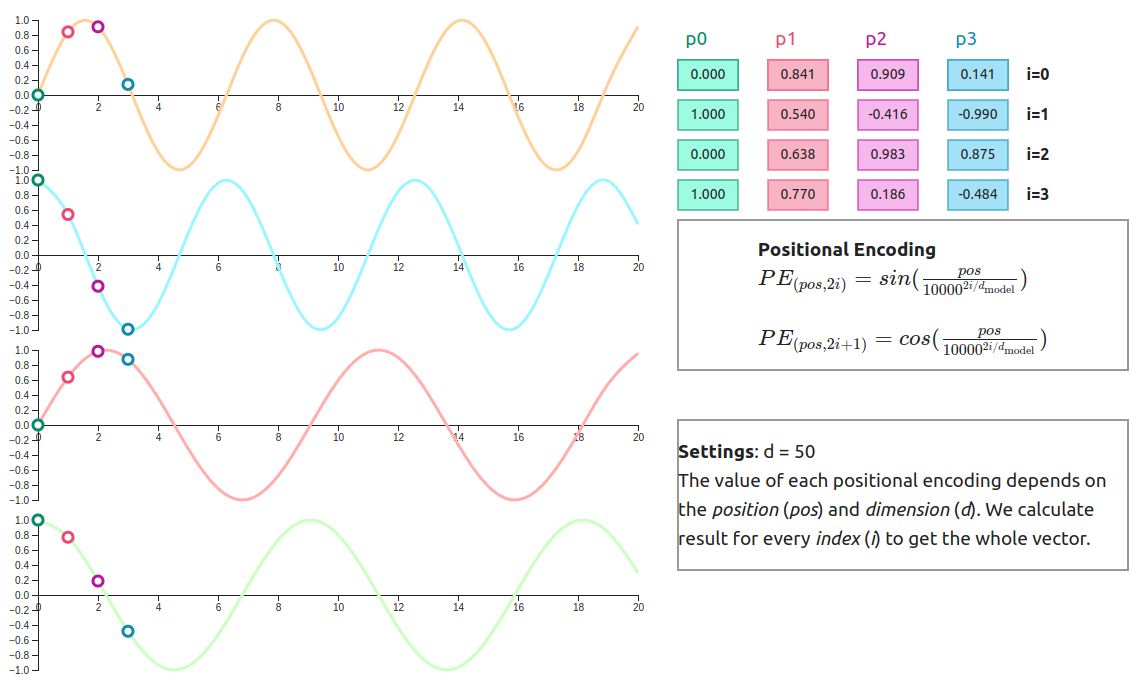
To solve this, GPT uses something called Positional Encoding — a clever way of injecting word order into the token embeddings.
📌 Technically:
Each token already has a vector embedding based on meaning.
Now, we add another vector — the position embedding — to show where the token appears in the sentence.
Example:
Token Embedding: [0.9, 0.1, 0.3, 0.7]
Position Embedding: [0.01, 0.09, 0.03, 0.02]
Final Input Vector: [0.91, 0.19, 0.33, 0.72]
So instead of just knowing what the word is, GPT now also knows where it appears.
Behind the scenes, this is achieved using mathematical sinusoidal functions, which generate unique patterns for each position.
Taarak summarizes:
“Word meanings matter — but word order gives meaning. GPT captures both — what the word is and where it is — thanks to positional encoding.”
🔍Self-Attention – Who Focuses on Whom?
Now comes the real magic that powers GPT — the concept of Self-Attention.
Taarak explains it in classic Gokuldham style:
“When Babita ji walks by, who gets maximum attention?
Of course — Jethalal gives her 100% attention.
But when Iyer speaks, Jethalal gives only 20% attention — and 80% fear.”
This is exactly how Self-Attention works in Transformers.
🤖 In Transformers:
Every token doesn’t just sit alone. Instead, each word/token looks at every other word in the sentence and decides:
“Whom should I pay attention to? And how much?”
This attention mechanism allows the model to understand context deeply.
📌 Technically:
Each token is converted into three vectors:
Query (Q)
Key (K)
Value (V)
Using these, the model calculates how much each token should attend to others using this formula:
Attention = softmax(Q • Kᵗ / √d) × V
Where:
Q • Kᵗ is the similarity between words
softmax normalizes the attention weights
The final result is a weighted sum of values based on importance
🧠 Example:
In the sentence:
“Popatlal is not married”
The word “not” must heavily influence the meaning of “married”.
Thanks to Self-Attention, GPT understands that and doesn’t treat “married” in isolation.
This is how GPT builds meaning from context, not just from isolated words — it’s not magic, it’s math.
Taarak concludes:
“GPT doesn’t blindly read left to right. It calculates attention — just like Gokuldham residents decide who to listen to at the society meeting.”
🔀 Multi-Head Attention – Different Brains in the Same Society
Taarak walks back to the board, chalk in hand, and asks the society:
“We understood how one word can pay attention to others. But tell me — can one single perspective capture everything?”
He points to the audience and says:
“Let’s imagine a Gokuldham society meeting. Iyer is giving a speech.”
Now observe:
Jethalal is watching Babita ji’s reaction
Bapuji is checking for moral correctness
Bhide is scanning for rule violations
Sodhi is analyzing the emotional intensity
Everyone hears the same words — but each person focuses on a different aspect of the situation.
This is exactly what happens in Transformers. And we call this powerful concept Multi-Head Attention.
🧠 What is Multi-Head Attention?
Instead of using just one self-attention mechanism, the Transformer uses multiple parallel attention heads.
Each head:
Calculates its own Query (Q), Key (K), and Value (V) matrices
Performs self-attention independently
Focuses on a different kind of relationship between tokens
Then, all these heads are concatenated (joined) and passed to the next layer — giving the model a richer understanding of the input.
📌 Why is this powerful?
Each head captures a unique perspective. For example, given the sentence:
"Popatlal is not married, yet hopeful."
Here’s how different heads might behave:
Head 1: Popatlal → not → married (factual negation)
Head 2: yet → hopeful (emotional optimism)
Head 3: pays attention to punctuation (tone of the sentence)
Head 4: picks up on sarcasm or social context
It’s like the whole Gokuldham society reading the same news headline — and each one forming their opinion based on what they care about.
This layered, parallel analysis is what allows GPT to understand complex meanings, hidden tones, and nuanced context — all in one go.
Taarak smiles and says:
“Self-attention was powerful. But multi-head attention? That’s like giving GPT the brains of Iyer, Jethalal, Bapuji, Bhide, and Sodhi — all working together, at the same time!”
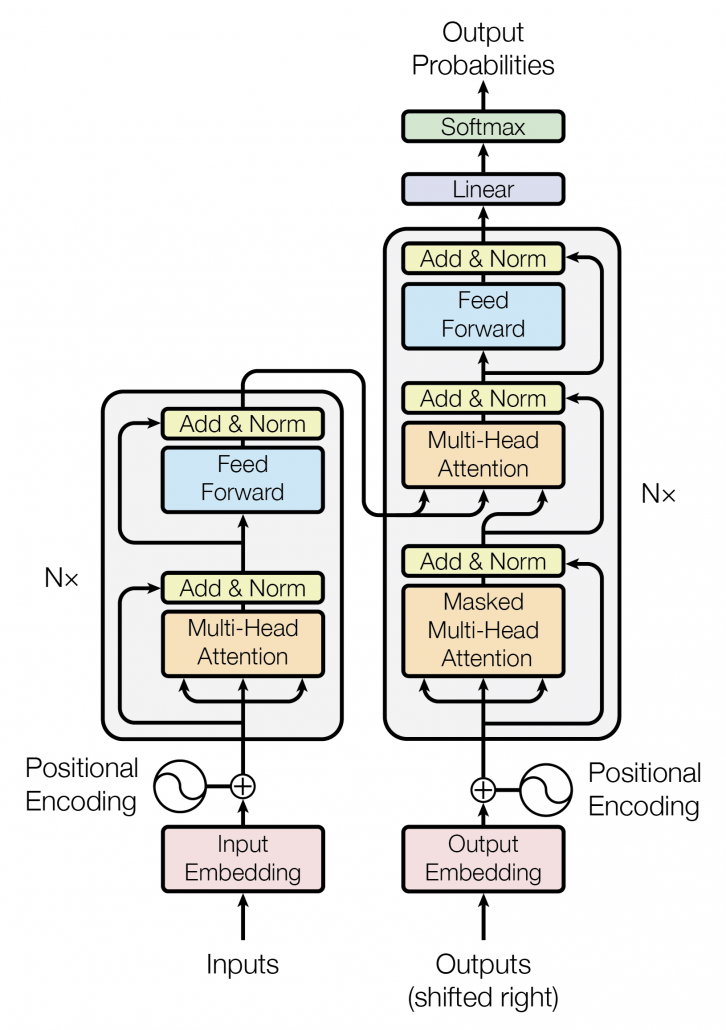
Transformer Block – Gokuldham Society Ka Control Room
Taarak now gathers everyone at the society clubhouse whiteboard and begins to connect all the dots.
He draws the entire flow of a Transformer block:
Input Tokens →
Embedding Layer →
Positional Encoding →
Multi-Head Attention →
Feed Forward Network →
Layer Normalization →
Output →
(Repeat for N layers)
He turns to Jethalal and explains:
“Jetha bhai, ek Transformer block mein sirf attention hi nahi hoti.
Uske baad aur bhi powerful steps hote hain — like Feed Forward Networks, Layer Normalization, and Residual Connections.”
Let’s break each part down technically.
🔹 Feed Forward Network (FFN)
After Multi-Head Attention, the output of each token goes through a small neural network made of two linear layers with an activation function (usually ReLU or GELU in modern LLMs).
Applied individually to each token.
Introduces non-linearity so that the model can capture more complex patterns.
🔹 Layer Normalization
Used to normalize outputs and keep the training stable.
Helps avoid exploding or vanishing gradients.
Ensures that each layer’s output stays within a consistent range.
It’s like how Bhide ensures that society meetings don’t go out of control — normalization keeps things calm and steady.
🔹 Residual Connections (a.k.a. Skip Connections)
These skip over a layer and add the original input directly to the output of that layer.
Prevents loss of original information.
Helps in learning deep networks efficiently.
Just like how Tapu Sena reports to both Bhide and Iyer — information flows from start to finish without being overwritten.
⚙️ Repeat for N Layers
All of the above — Attention, FFN, Layer Norm, and Residuals — are stacked together multiple times.
For example:
GPT-2 has 12 layers
GPT-3 has 96 layers
GPT-4 (unofficially) is even deeper
Each layer captures richer meaning, deeper context, and more abstract relationships — like society gossip going from Tapu Sena to Bapuji to Taarak and finally into absolute wisdom 😄
Jethalal finally says:
“So every sentence goes through multiple layers of Tapu Sena-style chhapan bhog analysis?”
Taarak nods with a smile:
“Exactly. That’s why GPT understands that ‘not married’ is different from ‘married’, especially when Popatlal is involved.”
🧪Training – When Tapu Sena Learns from Mistakes
Back at the clubhouse, Taarak takes a deep breath and starts explaining the training process of GPT.
He says:
“Before GPT could answer your questions, Jethalal… it had to learn, just like Tapu Sena learns from their daily mischief!”
He writes a simple sentence on the whiteboard:
"Popatlal wants to get married."
Now imagine how GPT learns:
It doesn’t see the whole sentence at once.
Instead, it learns to predict the next word (token) one by one.
🔁 Step-by-step Prediction:
Input:
"Popatlal"→ Output:"wants"Input:
"Popatlal wants"→ Output:"to"Input:
"Popatlal wants to"→ Output:"get"Input:
"Popatlal wants to get"→ Output:"married"
But in the early training days, GPT often gets it wrong. For example:
“Popatlal wants to get divorced.” 😬
That’s when the system steps in with a powerful tool called the Loss Function.
📉 What is Loss?
The loss function compares GPT’s prediction with the correct answer and calculates how wrong it was.
If the predicted word is far from the correct one → high loss
If it's accurate → low loss
This loss is the guiding signal used to improve the model.
🔁 Backpropagation: The Tapu Sena Lecture
Taarak continues:
“Every time Tapu Sena breaks a flower pot, Bhide scolds them and tells them where they went wrong. Slowly, they learn what not to do.”
Similarly, GPT uses backpropagation to adjust all its internal systems:
Attention weights
Embedding matrices
Layer outputs
With each mistake, GPT tweaks itself — getting smarter over time.
📚 Millions of Sentences = Smarter GPT
Over time, the model is trained on:
Books
Wikipedia
Forums like Stack Overflow
News articles
Social media posts
This training happens over millions (or billions) of sentences, helping GPT gradually learn:
Grammar
World knowledge
Sentence structure
Common sense logic
Taarak closes the board and says:
“So Jetha bhai, GPT didn’t become smart overnight.
Just like Tapu Sena matured (a little 😄) over years, GPT improved by learning from every mistake — reducing loss, round after round.”
🎭Inference – When GPT Performs Like Jethalal on Stage
Taarak claps his hands and announces:
“Training is over, doston!
Now comes the real drama — the Inference Phase.”
He walks to the board and gives an example:
You provide GPT with a prompt like:
"Once upon a time in Gokuldham..."
And GPT responds:
"...Jethalal was trying to install a transformer, but ended up calling Iyer instead."
Just like a TMKOC stage show — once the script starts, Jethalal performs based on all his prior rehearsals. He doesn’t learn anything new mid-act — he just tries to deliver the best possible performance.
🧠 What Happens During Inference?
At this stage:
No more training or updates
GPT doesn’t learn from new inputs
It generates the next best token, one step at a time
It works in an auto-regressive loop:
First word → predicts next → appends → predicts next → and so on...
🔁 Auto-Regressive Generation
Auto-regressive means GPT uses everything it has generated so far to decide what comes next.
Example:
Input:"Bhide found a bug in Tapu Sena’s..."
GPT might output:"...robot that was helping Madhavi with pickle labeling."
Then uses the entire new sentence to generate the next token.
This continues until:
A stopping condition is reached (like max length)
Or an end-of-sequence token appears
🎤 Analogy Time: Jethalal at a Stage Show
Inference is like Jethalal giving a speech at a Gokuldham function:
He has already rehearsed (i.e., model was trained)
Now, on stage, he performs (i.e., GPT generates responses)
He won’t stop midway to learn or check Wikipedia
He’ll simply continue, token by token, hoping not to mess up
Just like that, GPT performs — fluent, focused, and fast — based on everything it learned during training.
🕵️♂️ Tapu Sena Discovers the GPT Secret Vault
It’s late night in Gokuldham.
The street lights flicker. The society is silent. But... not for long.
Tapu Sena is on a secret mission.
Goli is munching chips, Sonu holds a torch, Gogi watches the surroundings, and Tapu leads the way with quiet confidence.
They tiptoe toward the society office, where a mysterious old door with a glowing digital keypad awaits them.
On the door, it says:
“Property of GPT — Access Denied Without Fine-Tuning”
Tapu whispers:
“Yeh GPT sirf baatein banata hai ya isme aur bhi kuch chhupa hai?”
They start guessing passwords:
1234Iyer123BabitaJiPopatlalShaadi2024
Nothing works.
Until... the door creaks open by itself.
Inside, they see something magical.
A large glowing screen showing a blueprint of a GPT model, but it’s labeled:
"Fine-Tuned on Gokuldham Society Private Data"
Their eyes widen.
What if GPT was trained only on Jethalal’s conversations?
What if it could answer in Bhide’s disciplined tone?
What if it could flirt like Natu Kaka?
Or give business advice like Bagha?
Tapu looks at the team and says:
“Yeh toh sirf shuruaat thi… ab asli khel shuru hoga!”
And with that, the mystery of fine-tuning begins.

🚀 What’s Next? Stay Curious…
In this blog, we uncovered how GPT:
Breaks down text into tokens
Understands context using self-attention
Thinks in parallel with multi-head attention
Learns from mistakes through backpropagation
And generates fluent responses like a storyteller
But friends...
This is just the beginning. We’ve barely scratched the surface of what makes Generative AI so powerful (and sometimes unpredictable).
In the next episode of this TMKOC x GenAI journey, we’ll dive deeper into:
🧠 Fine-Tuning – How you can train GPT on your own data and make it sound like your team, your brand, or even... Gokuldham Society!
🔧 Prompt Engineering – Tricks to make GPT behave exactly the way you want (no Babita ji distractions for Jethalal this time 😅)
🎲 Sampling, Temperature & Top-k – Why GPT sometimes gives smart answers, and sometimes... dreams like Popatlal
🕳️ Hallucinations & Limitations – When GPT makes up facts, and how to handle it wisely
🤖 How to Build Your Own GenAI App – A practical guide from a developer’s lens (just like Jethalal trying to create his own app!)
Stay tuned.
More mysteries from the GPT vault are coming soon.
And as Tapu Sena says: “Adventure toh abhi shuru hua hai!”
Subscribe to my newsletter
Read articles from Kunal Verma directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kunal Verma
Kunal Verma
Building apps by day, breaking down AI by night. I love mixing humor, storytelling, and tech