What Actually Happens When You Ask ChatGPT a Question?
 Aakashi Jaiswal
Aakashi Jaiswal
When you type a question into ChatGPT and hit send, a complex process unfolds in milliseconds to generate a human-like response. This process is powered by large language models (LLMs) like GPT-4, which use advanced machine learning techniques to understand your input and produce coherent, relevant answers.

1. Receiving Your Input
When you submit a question, ChatGPT receives your text as a string of characters. This could be anything from a simple greeting to a complex technical query. The system is designed to handle a wide range of topics and question formats, thanks to extensive training on diverse text data.
2. Tokenization: Breaking Down the Text
The first technical step is tokenization. The model doesn’t process your question as a whole sentence. Instead, it breaks the input into smaller units called tokens. Tokens are not always individual words; they can be subwords, characters, or even punctuation marks, depending on the language and the specific tokenizer used.
For example, the sentence “How does ChatGPT work?” might be split into tokens like “How”, “does”, “Chat”, “G”, “PT”, “work”, and “?”. This step is crucial because the model operates on these tokens, not raw text.
Tokenization allows the model to handle new words, typos, and various languages more flexibly. Each token is then mapped to a unique numerical value, which the model uses for further processing.
3. Embedding: Converting Tokens to Vectors
Once the input is tokenized, each token is converted into a high-dimensional vector, a process called embedding. These vectors capture semantic information about the tokens, meaning that similar words or phrases have similar vector representations.
Embedding is like translating words into a mathematical language the model can understand. This step is essential for the model to process and relate different tokens based on their meanings and context.
4. Positional Encoding: Understanding Order
Language is not just about words; the order matters. For example, “The cat chased the dog” means something different from “The dog chased the cat.” To help the model understand the sequence of tokens, positional encoding is added to the embeddings. This encoding provides information about the position of each token in the input sequence.
With positional encoding, the model can distinguish between “first,” “second,” and subsequent tokens, allowing it to maintain the correct order and context throughout the response generation.
5. Attention Mechanism: Focusing on What Matters
One of the key innovations in LLMs like ChatGPT is the attention mechanism, specifically self-attention. This allows the model to weigh the importance of each token relative to others in the sequence.
For example, in the question “What is the capital of France?”, the model needs to focus on “capital” and “France” to generate a relevant answer. Self-attention enables the model to consider the relationships between all tokens in the input, helping it understand context, resolve ambiguities, and maintain coherence.
The attention mechanism can capture long-range dependencies, meaning it can relate words that are far apart in the sentence, which is crucial for understanding complex queries and generating accurate responses.
6. Pattern Recognition and Contextual Understanding
As the model processes the input, it leverages patterns learned during training. LLMs like GPT-4 are trained on vast datasets containing books, articles, websites, and more. This training enables the model to recognize common phrases, idioms, and structures, as well as to infer meaning from context.
The model doesn’t just look at the immediate input; it also considers the broader conversation if there is one. This allows ChatGPT to maintain context over multiple exchanges, making the interaction feel more natural and coherent.
7. Prediction: Generating the Next Token
After processing the input and understanding the context, the model begins generating a response. This is done one token at a time in a process called autoregressive generation. At each step, the model predicts the most likely next token based on the input and the tokens it has already generated.
The model uses probability distributions to make these predictions. For every possible next token, it calculates the likelihood of that token being the correct choice. The token with the highest probability is selected, and the process repeats until the model generates a complete answer or reaches a predefined stopping point.
8. Output Ranking and Filtering
Before the final response is presented to you, the model may generate multiple possible continuations. These are ranked based on their likelihood and quality. Some systems also apply additional filters to remove unsafe, irrelevant, or nonsensical outputs.
Human feedback plays a role here as well. During training, human reviewers rank responses, helping the model learn which types of answers are preferred. This feedback loop improves the quality and reliability of the responses over time.
9. Decoding: Converting Tokens Back to Text
Once the model has generated a sequence of tokens for the response, these tokens are converted back into human-readable text. This process, called decoding, reverses the earlier tokenization and embedding steps.
The final output is a coherent, contextually appropriate answer to your question, presented in natural language.
10. Delivering the Response
The generated text is sent back to your interface—whether that’s a chat window, an app, or a website—almost instantly. The entire process, from receiving your question to delivering the answer, typically takes less than a second.
Why Does ChatGPT Sometimes Give Different Answers to the Same Question?

ChatGPT’s responses are influenced by several factors:
Input phrasing: Small changes in how you word your question can lead the model to focus on different aspects, resulting in different answers.
Randomness: Some degree of randomness is built into the generation process to make responses less repetitive and more natural.
Context: If you’re having a multi-turn conversation, previous exchanges can influence the current response.
How ChatGPT Maintains Context
ChatGPT uses the attention mechanism to keep track of context throughout a conversation. It can consider previous interactions within the same session to generate coherent and contextually appropriate responses. However, it doesn’t retain memory between sessions unless specifically designed to do so.
Handling Ambiguity
The model is designed to handle ambiguous queries using context clues and probabilistic reasoning to infer the most likely intent behind a question. While it performs well in many cases, highly ambiguous queries may still pose a challenge.
Ensuring Accuracy
ChatGPT’s responses are based on patterns and information learned during training on a diverse dataset. While it strives for accuracy, it can sometimes generate incorrect or misleading information. Continuous training and human feedback aim to improve the accuracy and reliability of the responses.
The Role of Human Feedback
Human trainers provide conversations and rank responses during the training process. These reward models help determine the best answers and guide the model’s learning. Users can also provide feedback by upvoting or downvoting responses, which helps fine-tune future dialogue.
The Transformer Architecture: The Backbone of ChatGPT
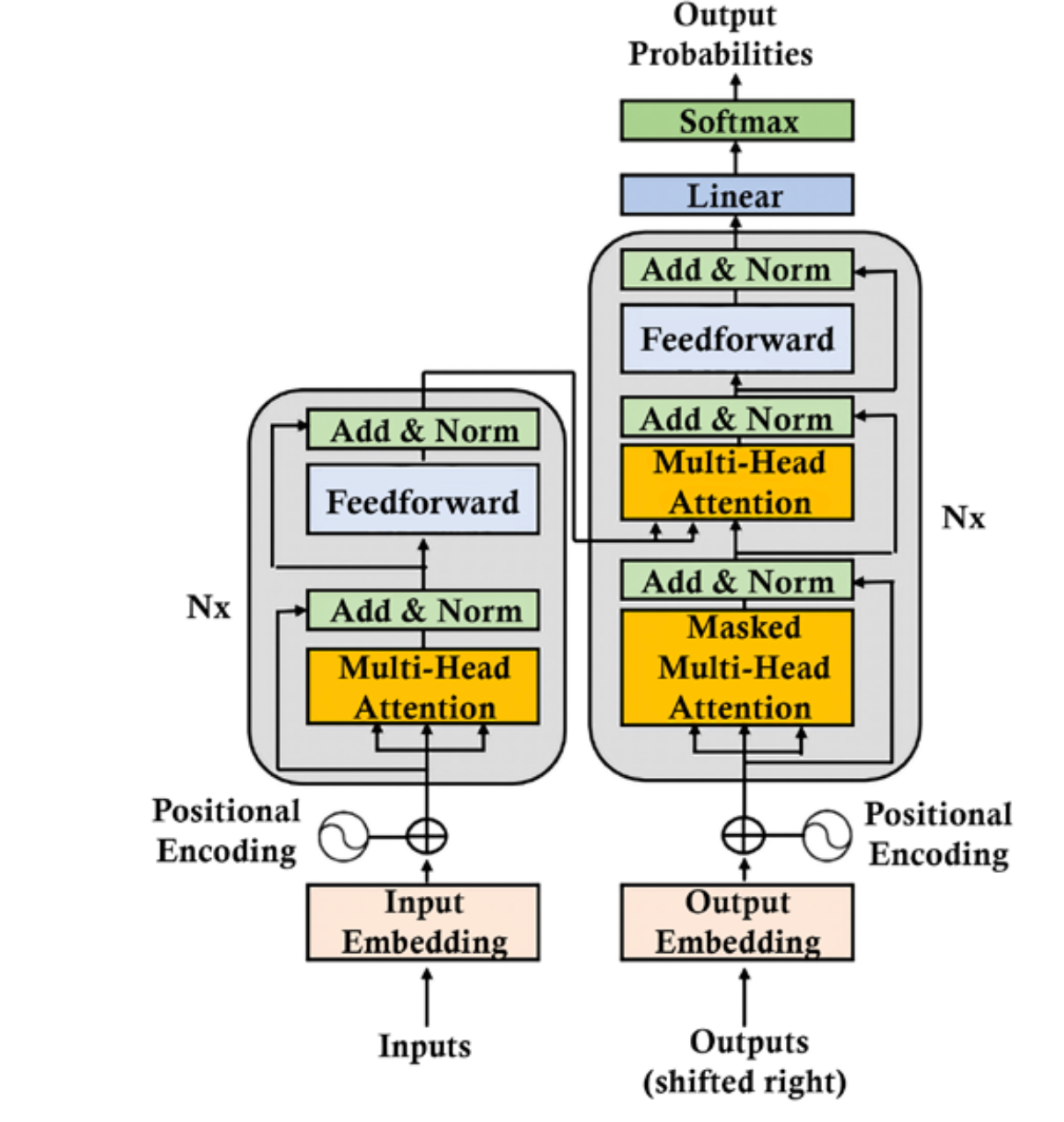
The underlying architecture of ChatGPT is called the Transformer. This neural network design is particularly well-suited for processing sequences of data, like text. The Transformer uses multiple layers of attention and feedforward networks to process input tokens, capture context, and generate output.
The self-attention mechanism within the Transformer allows the model to consider the entire input sequence at once, rather than processing it word by word. This enables ChatGPT to generate more coherent and contextually relevant responses.
Autoregressive Generation: Building Responses Step by Step
ChatGPT employs an autoregressive approach, generating one token at a time and feeding it back into the model to predict the next token. This process continues until the model generates a complete response.
The model’s predictions are influenced by the probability distributions learned during training, which guide it in selecting the most likely next token based on the input and the context.
Combining Tokens into a Final Response
The generated tokens are combined to form the final response. This response is converted from token embeddings to text, providing the user with a coherent and contextually appropriate reply.
Applications Beyond Text: Images, Audio, and More
While the primary function of ChatGPT is to generate text, recent models can also process images, audio, and other types of data. For example, GPT-4o can generate images, respond to voice queries in real time, and even search the web to summarize information.
This flexibility makes ChatGPT a powerful tool for a wide range of applications, from customer service to education, content creation, and beyond.
Limitations and Challenges
Despite its impressive capabilities, ChatGPT has some limitations:
Lack of true understanding: The model doesn’t “understand” language in the way humans do. It predicts likely responses based on patterns in data.
Potential for errors: ChatGPT can sometimes generate incorrect or nonsensical answers, especially on topics it wasn’t well trained on.
Biases: The model can reflect biases present in its training data.
No persistent memory: ChatGPT doesn’t remember past conversations unless specifically designed to do so.
Continuous Improvement
ChatGPT is continuously updated and improved based on user feedback, advances in machine learning, and new training data. This ongoing process helps the model become more accurate, reliable, and useful over time.
When you interact with ChatGPT, you’re engaging with one of the most advanced language models ever created. The process involves breaking down your question into tokens, understanding context through attention mechanisms, predicting responses one token at a time, and delivering a coherent answer-all in the blink of an eye.
The technology behind ChatGPT is complex, but its goal is simple: to make conversations with machines feel as natural and helpful as possible. As these models continue to evolve, they will become even more capable, opening up new possibilities for how we interact with technology in daily life.
Subscribe to my newsletter
Read articles from Aakashi Jaiswal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aakashi Jaiswal
Aakashi Jaiswal
Coder | Winter of Blockchain 2024❄️ | Web-Developer | App-Developer | UI/UX | DSA | GSSoc 2024| Freelancer | Building a Startup | Helping People learn Technology | Dancer | MERN stack developer