Architecting a Serverless Google Drive Proxy on AWS
 Ishaq Bux
Ishaq BuxTable of contents
- Requirements and Constraints
- Solutions That Look Obvious (But Aren’t Good Enough)
- The Practical Solution: Asynchronous Syncing Architecture
- Folder Syncing: Deep Dive into Upload Folder Lambda
- Google Workspace Files
- Handling Concurrent Requests
- DynamoDB Record Design
- Bonus: Google Drive-like Directory Listing
- Optimizations
- Final Thoughts
In many corporate or secure environments, there's a common challenge: public-facing domains, including Google Drive, are often blocked for security reasons. This poses a significant problem if your team relies heavily on Google Drive for resources. What do you do when your application needs to serve templates, images, or large files to users, but the source is in a blocked domain?
We are going to architect an interesting solution: a serverless Google Drive proxy using AWS. This will allow our content team to continue using the familiar Google Drive interface while our application can reliably serve those resources to users, even in restricted networks.
Requirements and Constraints
Before we dive into the architecture, let's outline the precise conditions for our solution:
Serverless First: The entire solution must be built using AWS serverless services (like Lambda, API Gateway, S3, and DynamoDB) to minimize operational overhead and scale effectively.
Template-Centric: Our current workload is around 100 templates with downloadable resources. We are targeting scale to 200–400 templates, each with a unique combination of files, folders, and nested resources.
Diverse File Types: The proxy must support video files, documents, images, zipped folders, and especially Google Workspace files (Docs, Sheets, Slides) that need to be exported to standard formats.
Shortcut Support: Google Drive shortcuts (pointers to other files/folders) must be resolved intelligently, and infinite loops must be avoided during recursive traversals.
Large Files: The system should support resources ranging from 600–800MB up to 1GB+ without breaking.
Live Sync: Editors will continue updating content in Google Drive. Workspace files don’t change their file IDs even when their content changes—so our proxy must still detect these changes and re-sync appropriately.
Blocked Domains: Users in some corporate networks won’t be able to access Google Drive, so all downloads must go through this proxy.
Solutions That Look Obvious (But Aren’t Good Enough)
1. Google Apps Script Sync to S3
Using Google Apps Script to detect changes and sync files to S3 seems simple, but has critical limitations:
Trigger Unreliability: The onChange event is not always dependable. Bulk updates can trigger throttling or missed events.
Execution Limits: Apps Script has tight runtime and memory limits (6 minutes), making it unusable for large folders or files.
Poor for Folders: Zipping folders or recursively syncing deeply nested structures is infeasible due to time and memory constraints.
✅ Bottom line: Not production-ready for large files or real-time sync.
2. Lambda Streaming Direct from Google Drive
AWS Lambda now supports streaming responses. One idea is to stream files directly from Google Drive through Lambda to the client via CloudFront. This hits several major challenges:
API Gateway Timeout: Lambda supports 15-minute runs, but API Gateway enforces a hard 29-second timeout. This leads to 504 Gateway Timeout errors for large downloads.
Folder Zipping in Memory: To serve a folder, we’d have to zip it entirely in-memory inside Lambda and then serve it.
Authorization: In this case, the user must send an authorization token, which will be verified by Lambda@Edge. If the requested resource is not found in the CloudFront cache, the request is then forwarded to the streaming API.
Fragile Flow: Any hiccup during the stream between Drive and Lambda or Lambda and the client breaks the whole process.
✅ Bottom line: Interesting but unreliable and not scalable.
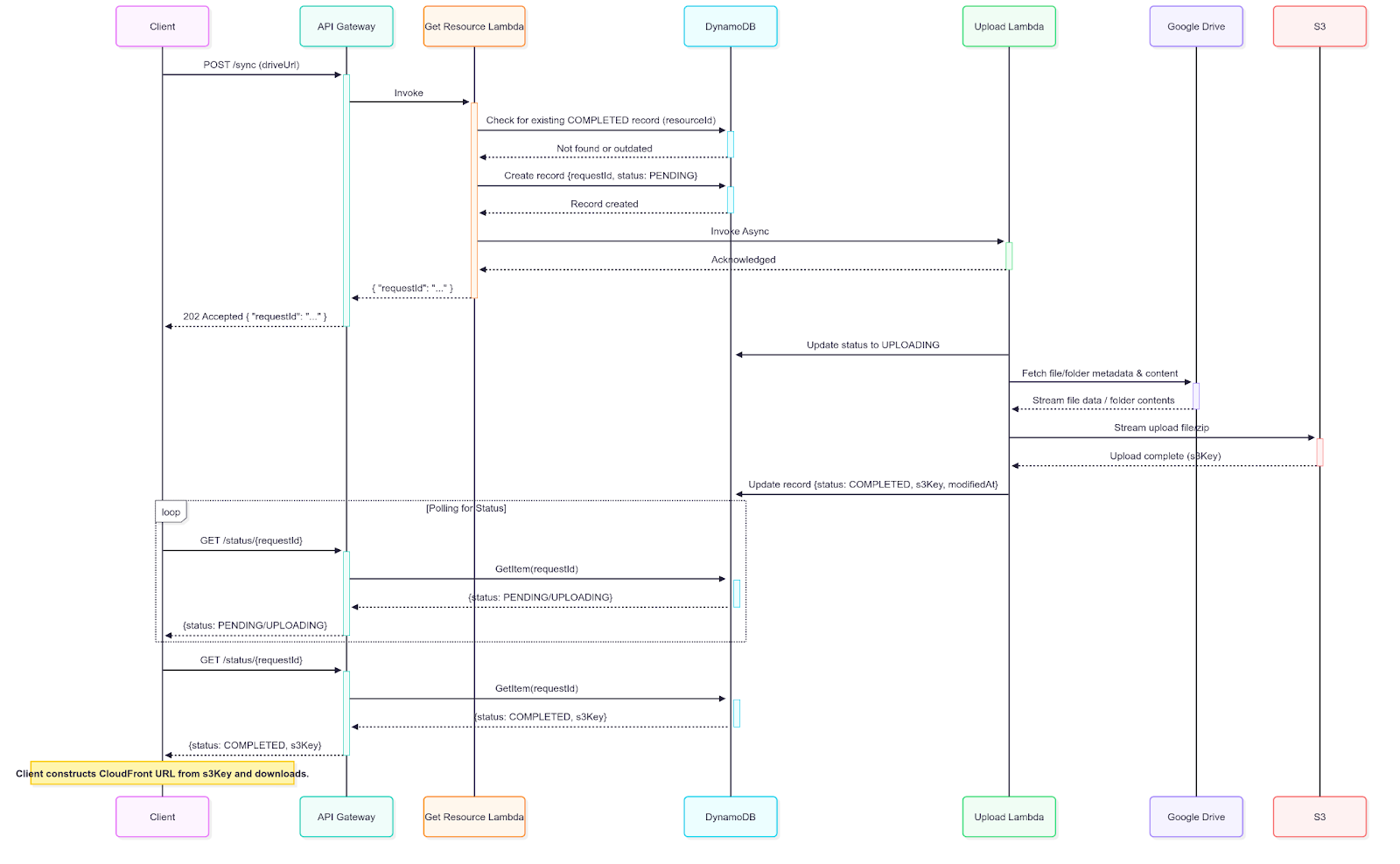
The Practical Solution: Asynchronous Syncing Architecture
Instead of live streaming, we sync Google Drive resources to S3 asynchronously. This allows us to decouple the client’s download from the Google Drive fetch and serve the resource quickly from a CDN like CloudFront.
Core Components
API Gateway: Single secure entry point for requests, protected by Amazon Cognito.
DynamoDB Table: Stores the status (PENDING, UPLOADING, COMPLETED, ERROR) of each sync job.
Lambda Functions:
Get Resource: Client-facing. Orchestrates the request and decides whether to serve from cache or trigger a new sync.
Get Status: Client-facing. Allows polling with requestId.
Upload File: Internal. Streams a single file from Drive to S3.
Upload Folder: Internal. Recursively zips and streams a folder to S3.
Flow: How It Works
Client Request: User hits a POST endpoint with a Google Drive URL.
Orchestration: Get Resource Lambda extracts the file/folder ID and checks DynamoDB.
Cache Check:
If a valid, up-to-date S3 version exists compared to Google Drive modifiedDate, it returns the s3Key.
If not, it:
Creates a requestId in DynamoDB (resourceId + timestamp) with status PENDING.
Triggers the appropriate Upload Lambda (file or folder).
Returns the requestId immediately to the client.
Polling: The client polls the Get Status endpoint with requestId.
Background Processing:
The Upload Lambda streams the resource to S3.
Updates the DynamoDB record with final status, S3 key, and modifiedDate metadata.
If an error occurs, sets status to ERROR and sent it to client , and users can retry the request without residual corruption.
Completion: When polling sees COMPLETED, client constructs CloudFront URL and starts the download.
Folder Syncing: Deep Dive into Upload Folder Lambda
When a user requests a folder via the POST API, the Upload Folder Lambda handles the following advanced logic:
1. Manifest Generation (Nested Modified Date Tracking)
Google Drive does not update a parent folder's modifiedTime if a nested file or subfolder is changed. To handle this:
The Lambda performs a Breadth-First Search (BFS) to traverse the folder tree using a queue (stack is used for DFS).
For each folder level:
It fetches children (files and folders) using batched Promise.all calls to avoid serial delays.
It constructs a nested manifest JSON object:
JSON
{
"folderId": "xyz",
"modifiedDate": "2024-06-01T10:00:00Z",
"children": [
{
"type": "file",
"id": "abc",
"name": "image.png",
"modifiedDate": "2024-06-01T09:00:00Z"
},
{
"type": "folder",
"id": "def",
"name": "subfolder",
"children": [...]
}
]
}
The manifest is stored in DynamoDB with the S3 zip reference, and used in future requests to detect if any part of the folder tree has changed.
2. Shortcut Handling and Infinite Loop Protection
Google Drive allows shortcuts (pointers) to other folders or files.
A global visitedIds set is maintained to avoid re-traversing folders/files already visited (which could otherwise cause infinite loops).
If a shortcut is detected:
It is resolved using file.shortcutDetails.targetId.
Only unique and unvisited target IDs are followed.
3. Zipping and Uploading
Once traversal completes, the Lambda uses a streaming zip library (like archiver) to:
Stream file content from Drive API directly.
Pipe content into a ZIP stream.
Upload ZIP to S3 via a write stream, without needing full in-memory processing.
4. Updating DynamoDB
The record is updated with:
status: COMPLETED
s3Key: /resources/folder_xyz.zip
The generated manifest
lastSynced: timestamp
Google Workspace Files
Google Docs, Sheets, and Slides don’t support direct download. The Upload File Lambda uses Google Drive’s export functionality to convert them (e.g., .docx, .xlsx, .pdf) before uploading to S3. This ensures compatibility and usability on the client’s local machine.
Handling Concurrent Requests
If a second client requests the same resource while the first upload is in progress:
Get Resource Lambda checks for any existing record with PENDING or UPLOADING status.
It reuses the same requestId and returns that to the client.
Clients polling with the same ID will all benefit from the same background processing.
DynamoDB Record Design
Each resource is tracked in a DynamoDB table with this schema:
Field | Type | Description |
requestId | String | Primary Key: ${resourceId}_${timestamp} |
resourceId | String | Google Drive ID of file/folder |
type | String | file or folder |
status | String | One of PENDING, UPLOADING, COMPLETED, ERROR |
s3Key | String | Final S3 key to access resource |
modifiedAt | ISO Date | Last known Drive modification time or manifest hash |
manifest | JSON | For folders – deeply nested structure of children |
ttl | Number | TTL in epoch seconds for cleanup |
Bonus: Google Drive-like Directory Listing
To mirror Google Drive’s interface in your app:
Add a Lambda to fetch the metadata for a given folder.
Return file/folder names, sizes, types.
Frontend renders this as a directory structure.
Enable navigation, breadcrumbs, pagination using Google Drive APIs.
Optimizations
S3 Lifecycle Rules: Auto-delete unused or stale resources after X days.
Smart Polling: Use exponential backoff to reduce DynamoDB and API Gateway load.
Avoiding Pub/Sub Triggers: Since the number of templates is bounded and manageable, we’ve consciously avoided complex push-based sync.
Handling Shortcuts: Track visited file/folder IDs to avoid infinite traversal loops.
Final Thoughts
This architecture provides a reliable and scalable way to proxy Google Drive resources securely—even when Drive itself is inaccessible.
Integrating it into production? You’ll want to add wrappers for:
Logging and observability (CloudWatch, OpenTelemetry)
Download analytics
Alerts for failed uploads
User behavior monitoring
But the core functionality described above gives your team a powerful proxy that keeps content creators on Google Drive and users fully served—no matter what network they’re on.
Let me know if you’d like a visual architecture diagram, frontend integration plan, or code sample for the Lambdas.
Subscribe to my newsletter
Read articles from Ishaq Bux directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by