I Asked My Brain “What Even Is RAG?” — and 10 Google Tabs Later, I Think I Know~
 Gazal Arora
Gazal AroraTable of contents
- ☕ But first, what’s RAG?
- 🧠 But how do you actually implement it?
- 1. 🖥️ OpenWebUI + Ollama (The Clean UI + Local Model Vibes)
- 2. 🧱 LangChain
- 3. 📚 LlamaIndex (fka GPT Index — a.k.a. the Document Nerd)
- 4. 🧰 Haystack (The RAG Engineer’s Power Drill)
- 5. 🧬 HuggingFace Transformers + FAISS (The DIY RAG Lab Setup)
- 🤯 The Big Question : Which One Should You Use?
- 🧵 Wrapping it all up
Welcome back to my digital thought bubble — where tech meets “what am I doing again?” and somehow it all turns into a blog post.
So here’s the deal: I’m currently interning (woohoo, real-world chaos unlocked), and my mentor gave me a task that sounded so harmless at first — “Hey, just study different ways of implementing RAG and document them while you do it.”
That’s it.
Simple? No.
Terrifyingly open-ended? Absolutely.
And thus began the Great RAG Rabbit Hole️.
Because the deeper I went, the more RAG felt like this secret society of frameworks, vector databases, embeddings, LLMs, and mysterious chains that all somehow talk to each other.
And me? I was just vibing with a blank Notion page and 10+ open tabs, praying that I didn’t end up accidentally training a model on my Spotify Wrapped.
But I made it.
And now, you’re getting the post that future-you can refer to when RAG inevitably comes up in your ML/AI journey.
☕ But first, what’s RAG?
RAG = Retrieval-Augmented Generation.
Translation: You make your Large Language Model (LLM) slightly less of a hallucinating storyteller and a bit more of a fact-respecting librarian.
It’s like giving your AI a cheat sheet. Instead of making things up from its training data circa 2023 BC (Before ChatGPT), it retrieves real info from a knowledge base and generates responses based on that.
Retrieval.
Augmentation.
Generation.
(Basically, give it notes → it writes the essay.)
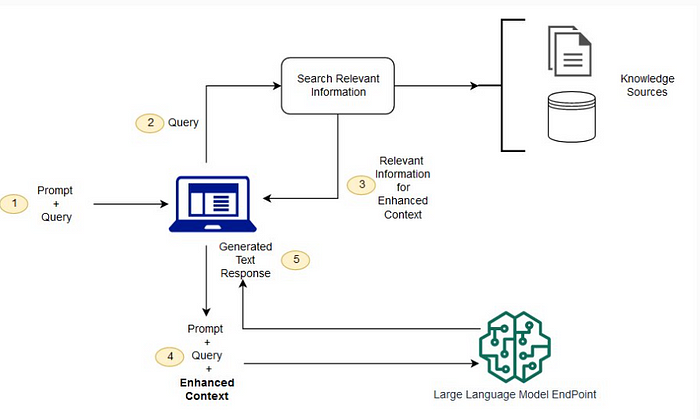
In plain English?
Step 1: You give the AI a question.
Step 2: It searches a knowledge base (documents, PDFs, databases, etc.) for relevant info.
Step 3: It uses that retrieved context to generate a more accurate answer.
Boom. Now your LLM isn’t hallucinating — it’s doing open-book tests.
🧠 But how do you actually implement it?
There are several ways to set up a RAG system — ranging from drag-and-drop UIs to fully programmable frameworks. Here’s a breakdown of the best ones, organized from easiest to most flexible.
1. 🖥️ OpenWebUI + Ollama (The Clean UI + Local Model Vibes)
This one’s for those who want RAG without writing a single line of code to get started.
What it is:
OpenWebUI is a beautiful local web interface that connects with LLMs through Ollama (which lets you run models like LLaMA or Mistral on your machine).
How RAG works here:
Upload your files → It indexes them → Ask a question → It retrieves relevant chunks → Sends both to the model → You get a context-aware answer.
Why it’s cool:
No API keys or cloud dependencies
Entirely local = no data leaves your machine
Quick and intuitive setup (especially using Docker)
Why it’s limited:
Constrained by local resources (RAM, GPU)
Limited to local models unless configured externally
2. 🧱 LangChain
This is where you go from “I’m exploring RAG” to “I’m building my own RAG stack from scratch, baby.” If you’re a control freak and want control, modularity, and flexibility, this one, is for you!
What is it?
LangChain is a Python/JavaScript framework designed to build chains of LLM operations — like retrieval, parsing, and generation.
How RAG works here:
You use RetrievalQA chains to combine a retriever (like FAISS or Chroma) with a language model. You can choose your embedding model, chunking strategy, and even post-processing logic.
Why it’s powerful:
Supports tons of components: OpenAI, Cohere, HuggingFace models, Pinecone, FAISS, ChromaDB, etc.
Has a special concept called “Retrievers” that you can plug into any chain
Includes tools like LCEL (LangChain Expression Language) for declarative pipelines
Typical RAG setup:
Load documents
Embed them (e.g., using OpenAI or Sentence Transformers)
Store in a vector DB (FAISS, Chroma, Pinecone)
Use a retriever
Pass results to the LLM for generation
Pro tip: Use ConversationalRetrievalChain for chatbot-like RAG systems.
3. 📚 LlamaIndex (fka GPT Index — a.k.a. the Document Nerd)
This tool thrives on messy data: PDFs, Notion dumps, HTML blobs, SQL tables — if it looks unstructured, LlamaIndex eats it for breakfast.
What is it?
A framework that bridges your external data (structured or not) with LLMs. It handles document loading, chunking, indexing, and querying — making your data actually usable in prompts.
How RAG works here:
Load documents from sources like PDFs, HTML, Notion, SQL, Google Docs, APIs.
Chunk them intelligently (semantic splitting, adjustable size/overlap).
Index using vector DBs (FAISS, Chroma, etc.) or keyword tables.
Query: LlamaIndex retrieves relevant chunks → sends them to your LLM → returns grounded answers.
Cool Features:
Supports FAISS, Chroma, Weaviate, Pinecone, Qdrant, etc.
Handles PDFs, markdown, Notion, HTML, SQL, APIs — even mixed-source pipelines.
Composable indexes: build multi-hop or hierarchical retrieval flows.
Agent + LangChain integration out of the box.
Streaming + callback support for real-time apps.
Persistent index storage for production deployment.
Use it when:
You’ve got loads of content (legal docs, wikis, reports) and want retrieval to just work.
You need a chatbot, search assistant, or RAG pipeline that understands your data.
You want flexibility without building everything from scratch.
4. 🧰 Haystack (The RAG Engineer’s Power Drill)
If LangChain is your playground, Haystack is your workshop. Built by deepset, it’s an open-source framework to help you build production-grade RAG apps, fast.
What is it?
Haystack is a Python framework that lets you connect LLMs with data pipelines using modular components like retrievers, converters, prompt builders, and generators. Think of it as LEGO blocks for LLM-powered search and Q&A systems.
How RAG works here:
Ingest documents → preprocess and split → embed and store → retrieve based on query → pass to LLM → generate grounded, accurate responses.
Why it’s cool:
Component-based pipelines you can wire and visualize
Supports OpenAI, Cohere, Hugging Face, and more
Handles everything from PDFs to HTML and APIs
Works with vector stores like FAISS, Weaviate, Elasticsearch
Easy to convert into REST APIs for production
Why it’s worth trying:
You want something cleaner and more focused than LangChain, with great support for real-world deployments and full control over your data flow. Perfect if you’re serious about building an actual product — not just testing the waters.
Pro tip: Use InMemoryDocumentStore for fast prototyping, then switch to FAISS or Weaviate when you're ready to scale.
5. 🧬 HuggingFace Transformers + FAISS (The DIY RAG Lab Setup)
This is for the “I want to learn it all by hand” crowd. for the open-source purists. No middleware, no magic — just raw power and total control.
What is it?
Use the HuggingFace Transformers library to pick your embedding model (like sentence-transformers) and generation model (like T5, GPT2, or Mistral). Pair it with FAISS for fast, efficient vector similarity search.
How RAG works here:
Split your docs → embed chunks → store vectors in FAISS → embed the query → retrieve top-N similar chunks → pass context + query to the LLM → generate answer.
Why it’s cool:
Zero APIs = completely offline-capable
Choose any open-source embedding or generation model
Maximum control over every step: chunking, indexing, retrieval, prompting
Scalable and production-ready if you set it up right
Why it’s not for everyone:
No handholding or plug-and-play tools
You’ll need to build your own pipelines, memory management, and prompting logic
Pro tip: Combine InstructorEmbedding models for smarter semantic search and lightweight decoder models (like flan-t5-small) for fast, local generation.
🤯 The Big Question : Which One Should You Use?
That depends on your life priorities:
Want fast UI? OpenWebUI
Love building workflows? LangChain
Drowning in PDFs? LlamaIndex
Need APIs & deployment? Haystack
Want full control? HuggingFace Transformers + FAISS
And if you’re me? You try a bit of all and cry a little on the inside because wow — RAG is deep, chaotic, and kind of magical.
🧵 Wrapping it all up
So yeah — that’s RAG. Or rather, RAG in all these different flavors, from low-code playgrounds to full-stack production monsters.
It’s honestly kind of beautiful how many ways there are to make your LLM smarter, more grounded, and less likely to say “the capital of Canada is maple syrup.” 🍁
Whether you’re building a chatbot, a knowledge assistant, or just trying to stop your AI from hallucinating 24/7 — RAG is the way.
With confusion turned curiosity,
and caffeine turned comprehension,
Ava ☕
Subscribe to my newsletter
Read articles from Gazal Arora directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by