Fear, Hype, Hope: Unpacking GenAI for Builders — The Real Story Behind the Magic ✨
 Rajesh Kumar
Rajesh Kumar
Is GenAI just a fancy new name for AI, or is it a game-changer? We’ll see what makes it special, how it quietly does its job, and how you can use it to build cool stuff. With zero hype, and lots of real-world clarity.
Remember our pizza story? If not, I highly recommend checking out that foundational piece first — we broke down all the hyped AI jargons (like ML, Data Science, NLP, and Deep Learning) using pizza, sci-fi, and a lot of fun.
We watched our pizza AI evolve — from simply recommending a “Farmhouse Special” to actually inventing something new like Monsoon Masala Pizza 🌧️🍕.
But now you’re probably wondering:
🤔 “How did it actually create that recipe?”
🤔 “Is it thinking like a real human chef?”
🤔 “Should I be worried it’ll replace pizza chefs?”
🤔 “Wait… if it can create code too, should I be worried as a developer?”
🤔 “Do I need to master ML or Data Science to even build things with this?”
🚫 You Don’t Need to Be a Scientist to Build with GenAI
Think about being a frontend developer. You use React, Material UI, Redux — but do you need to understand every tiny detail of how React works inside, or how Material UI designs its parts deep down?
ANSWER — Not really.
Maybe a little bit of internal understanding helps for fixing problems or making things faster (about 10% of your time). But most of your time (90%) is spent building real things that solve real problems for users.
Now, let’s flip that coin. There are teams of developers and researchers whose job is to build React, Material UI, or Redux. They spend 90% of their time building the tools, and only 10% thinking about how people use them.
So here’s the key idea:
🔧 Tool Builders (Engineers, Researchers) create the powerful engines
🛠️ Tool Users (Developers, Builders like you) use those engines to create amazing products
Now Translate That to the World of AI:
🧠 ML, Data Science, NLP, and Transformers are like the car’s engine. Transformers are the big invention, like when cars got powerful engines that changed everything.
🚗 GPT-4, Claude 3, Gemini, LLaMA are like different car models that all use the same amazing engine tech (Transformers).
🧑💻 ChatGPT, Claude AI, Google Gemini app are like the car’s dashboard/interface and steering wheel — what you use to actually drive the AI.
🧩 So What Does This Mean for You?
No — you don’t need to master complex AI science (ML, NLP, Data Science) to build with GenAI. Just like you don’t need to build React to use it effectively.
What you do need is the builder mindset:
✅ Learn how to use GenAI tools well
✅ Focus on solving real user problems
✅ Understand the surface-level mechanics enough to debug and optimize
✅ Leave the engine-building to the teams who specialize in that
⚠️ Side Note*:* Knowing both the engine and the tools is a superpower 🦄 — but not mandatory.
🎭 The Great AI Magic Trick Revealed
Let’s go back to that moment when you asked your pizza AI:
“Create a pizza inspired by monsoon season. It should feel cozy, warm, and a little spicy — just like chai on a rainy day.”
And it responded:
“Try the Monsoon Masala Pizza: A base of smoky tandoori sauce, mozzarella, masala corn, and a hint of chai-spiced caramelized onions. Served with mint chutney drizzle.”
Your first thought probably was:
“Whoa! It UNDERSTOOD monsoon vibes!”
“It CREATED a recipe that never existed!”
“It’s thinking like a creative chef!”
“Will it replace human chefs?!”
But here’s the reality:
Your AI didn’t understand monsoons. It didn’t imagine. It didn’t think like a chef.
What it actually did?
It played a very sophisticated word prediction game using something called a Transformer.
🧐 Wait — So What Exactly Is GenAI?
GenAI = Generative AI
It’s a type of AI that can generate new things:
Text (like ChatGPT or Claude)
Images (like DALL·E or Midjourney)
Code (like GitHub Copilot or CodeWhisperer)
Videos, music, designs, and more
In simple terms: It’s an AI system trained on massive amounts of data that can produce human-like outputs based on prompts — just like your pizza AI inventing Monsoon Masala Pizza from scratch.
At this point, we’ve talked about engines (Transformers), models (like GPT-4), and tools (like ChatGPT).
Let’s try to understand this with a simple comparison of building a website vs. building with AI.
Think about building a website: You don’t build everything from scratch. You use tools like React, Material UI, and APIs to create clean, interactive user experiences. You pass in some data, write some code, get information from other places — and boom, your app responds to users in real time.
Now imagine this: Instead of building a website, you’re building something that can write, design, or code — just from your instructions.
That’s Generative AI (GenAI)*. It’s like a frontend layer for **creative output**\.*
And just like building a website, GenAI has layers:
📊 React vs GenAI — A Developer’s Mental Model

So far, we understand what AI and GenAI are. As builders, we always think: “What do I want to build?” and “How should I think about this to solve this problem?”
Now it’s time to understand the core engine behind it: the Transformer.
🧪 Let’s Pull Back the Curtain on the Magic Trick
Since most of you know ChatGPT, let’s use it to understand how this “magic” works.
👥 Who’s Behind All This?
Let’s meet some of the key minds who helped spark this AI revolution:
Sam Altman — CEO of OpenAI
Ilya Sutskever — Co-founder & Former Chief Scientist at OpenAI (departed in May 2024 to start Safe Superintelligence Inc.)
Jakub Pachocki — Current Chief Scientist at OpenAI (replaced Sutskever)
Together with teams of researchers and engineers, they created the engine that powers ChatGPT — called GPT.
GPT stands for:
G — Generative
P — Pre-trained
T — Transformer
When you hear names like ChatGPT, Claude, Gemini, GitHub Copilot, or DeepSeek, they all run on this Transformer engine architecture.
🎯 Key Concepts You Should Know as a Builder
Before we get into how Transformers actually work under the hood, it’s important to pause and understand something foundational — because this is where a lot of confusion starts for developers new to GenAI.
You might hear about “training” or “fine-tuning” or “model updates.” But when you’re using ChatGPT, GitHub Copilot, or any GenAI app — what’s really happening? Let’s clear that up.
🎨 Training vs. Inference — The Two Phases of Any AI Model
Training = The learning phase. This is when the AI model is fed massive amounts of data (like books, websites, code, conversations) and slowly adjusts itself to learn patterns and relationships.
🧠 Think of it as the “education” phase.
It takes months, costs millions (sometimes hundreds of millions!), and happens only once per version (like GPT-4, Claude 3, etc.)
Requires thousands of specialized GPUs running 24/7
Uses carefully curated datasets — not just random internet text, but quality-filtered content
But here’s where it gets interesting: after this basic training, there’s often another crucial step…
Fine-tuning & RLHF — Remember how ChatGPT feels more helpful and conversational than just predicting random internet text? That’s because after the basic training, it goes through additional refinement:
Fine-tuning on specific tasks (like following instructions)
RLHF (Reinforcement Learning from Human Feedback) — where human trainers rate responses as helpful/unhelpful, and the model learns from these preferences
Think of it like this: basic training teaches the model language patterns, but fine-tuning teaches it how to be a helpful assistant.
Inference = The usage phase. This is what happens when you interact with a trained model — like typing into ChatGPT. The model isn’t learning anymore — it’s just using what it already learned to create a response.
⚡ Then, Inference is like that student taking a quick test or answering a question. It’s fast and cheap because they’ve already learned everything.
It happens millions of times a day.
Each response costs fractions of a penny, while training costs millions
🤖 Enter: The Transformer
Many of you recently heard these fancy words “OpenAI” or “ChatGPT” around 2022–2023 and thought this was brand new technology. But here’s the truth: Transformers were already revolutionizing AI years before ChatGPT became a household name.
The foundation was laid much earlier. Google’s BERT (2018) was already using Transformers to understand search queries better. Facebook was using them for translation. Researchers worldwide were building on this architecture. ChatGPT didn’t invent the magic — it just made it accessible to everyone.
Let’s rewind to 2017. A team of researchers at Google published a paper titled “Attention Is All You Need”. This introduced the Transformer model — a new way for machines to understand language by focusing on how words relate to each other.
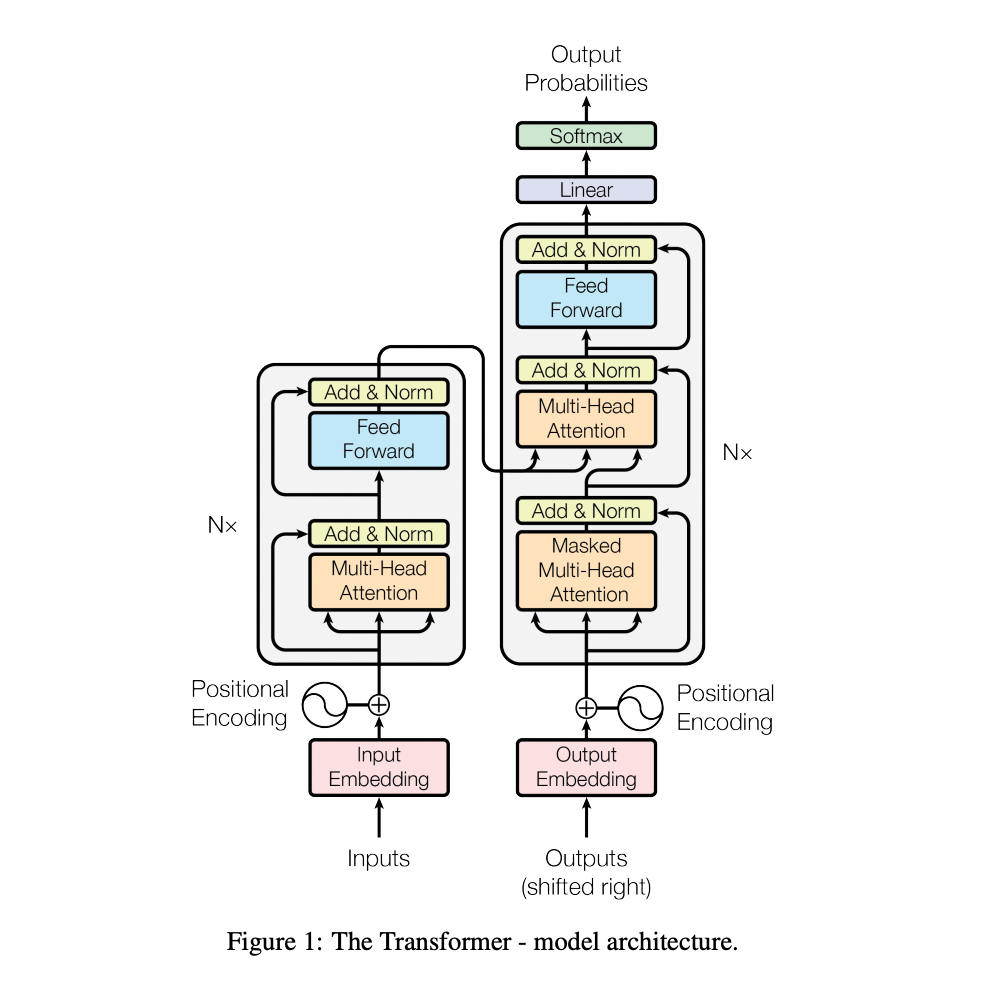
It was a game-changer. This architecture replaced older, slower models like RNNs and LSTMs, and became the foundation for powerful models like BERT and GPT —the brains behind tools like ChatGPT..
📌 Quick Note: GPT vs ChatGPT — Not the Same Thing
It’s easy to mix them up, but here’s the key difference:
🧠 GPT (like GPT-3 or GPT-4) is the model — the powerful brain built using the Transformer architecture. It’s what actually processes language and creates responses.
💬 ChatGPT is the app/interface — the chat program that lets you talk to the GPT model in a conversational way.
👉 So technically, ChatGPT is not a model itself. It’s a user-friendly wrapper around a model like GPT-4. It’s like how Google Search is the app you use, but there’s a complex system (algorithm) working behind it that you don’t see.
🧩 So… How Does a Transformer Actually Work?
Let’s use a real ChatGPT example.
🧑💻 You say: “Hey ChatGPT, how are you?”
Seems casual, right? Let’s walk through how this tiny message triggers one of the most powerful AI systems in the world.
Your Input Text → Transformer Model → Generated Output
Let’s break that into steps:
1. 🧱 Tokenization: Breaking Down Your Input
AI doesn’t process sentences the way we do. It first breaks text into tokens — chunks of text like words, subwords, or characters (depending on the model).
Your input: “Hey ChatGPT, how are you?”
Becomes: ["Hey", "Chat", "GPT", ",", "how", "are", "you", "?"]
In other models it can tokenize different way. Maybe like
["He","y", "C","hat", "GP", "T","how", "are", "y", "o", u", "?"]
These tokens are mapped to numbers(I’m just using random numbers) using a vocabulary dictionary:
[15496, 24704, 99945, 11, 1268, 527, 499, 30]
Each token gets a unique ID number that the model can work with.
Want to see your own text broken down? You can visualize how tokens are created using tools like Tiktokenizer here.
These tokens are mapped to numbers using a vocabulary dictionary, often containing tens of thousands of entries.Think of this as creating a unique ID for each piece of text.
💡 Why Tokens Matter for You as a Builder
Tokens aren’t just a technical detail; they directly affect how your AI applications behave and, importantly, how much they cost!
💰 Cost: AI services usually charge you based on the number of tokens you use in your prompts and the responses you get back. A simple English sentence might be 10–20 tokens, but longer messages or detailed answers quickly add up. Being smart about token count means you save money!
⚡ Speed: More tokens mean the AI has more data to process, which can make your app feel slower. If responses are dragging, a very long prompt might be the reason
🧠 Meaning & Accuracy: The way your words are broken into tokens can subtly change how the AI “understands” your input. If a crucial word or phrase gets split awkwardly, it might confuse the model. This is especially true for specific formats like JSON data or programming code, where precision is key.
👉 Think of tokens like bundle size in frontend apps: the smaller and cleaner it is, the faster and cheaper everything runs.
→ But numbers alone don’t carry meaning. That’s where embeddings come in…
2. 📊 Embeddings: Giving Numbers Meaning
So, your words have been broken down into tiny pieces called tokens, and each token got its own unique ID number. That’s a great start, but those numbers alone don’t tell the AI much about what the words actually mean or how they relate to each other. Think of it like this: if you see the number “7” and the number “8,” you know they’re different, but you don’t know if they’re talking about apples, cars, or feelings.
This is where the real magic of embeddings comes in.
Instead of just a simple ID number, the AI transforms each token’s ID into a special kind of “numeric fingerprint” called a vector. Imagine a vector as a long list of hundreds, or even thousands, of numbers (like [0.23, -0.45, 0.67, 1.89, …]).
So, what’s so special about these “numeric fingerprints”?
These embeddings are incredibly clever because they capture the meaning of the token. Here’s how:
Words that mean similar things get similar fingerprints. For example, the word “king” and the word “queen” will have very similar lists of numbers because they both relate to royalty. The word “apple” and “banana” will also have similar fingerprints because they’re both fruits.
Words that are often used in similar contexts also get similar fingerprints. The AI learns this by analyzing billions of sentences during its training. If “happy” and “joyful” appear in similar sentences, their embeddings will be close.
Think of it like a smart map of words:
Imagine a vast, multi-dimensional space (don’t worry too much about “multi-dimensional” — just think of it as a very, very big canvas). Every word is placed on this canvas not just randomly, but based on its meaning.
Words like “cat,” “dog,” and “lion” would cluster together because they’re all animals.
Words like “run,” “walk,” and “jump” would form another cluster because they’re actions.
The distance between words on this map indicates how similar their meanings are. “King” would be very close to “queen,” but very far from “pizza.”
So, when the AI sees the embedding (the numeric fingerprint) for “king,” it instantly “knows” it’s related to royalty, leadership, and potentially “queen” or “throne,” without anyone explicitly telling it. These embeddings are the AI’s internal, rich dictionary of meaning, allowing it to understand the nuances of language in a way simple ID numbers never could.
However, at this stage, the AI still doesn’t inherently understand the order of the words. “How are you” and “You are how” would still look the same if only their individual token meanings were considered. That’s the next step!
3. ⏳ Positional Encoding: Teaching Order Matters — The AI Learns Sentence Flow
You’ve given the AI each word’s “numeric fingerprint” (embedding), which tells it what the word means. That’s great! But imagine if I just threw a pile of ingredient cards at you — “flour,” “eggs,” “sugar” — you’d know what each one is, but you wouldn’t know if I’m making a cake or an omelet without the order.
Machines are similar. They don’t naturally understand word order the way our brains do. For an AI, “Dog bites man” and “Man bites dog” might look almost identical if it only considers individual word meanings. This is a big problem, right?
That’s where Positional Encoding steps in.
The AI adds special mathematical patterns to each token’s embedding. Think of these patterns as a unique “time-stamp” or “positional marker” for every word in the sentence. It’s like giving each ingredient card a number: “1. Flour,” “2. Eggs,” “3. Sugar.” Now, the AI knows not just what the word means, but where it sits in the sentence relative to every other word.
This clever step helps the model clearly tell the difference between:
“Hey ChatGPT, how are you?” (a proper greeting with a question)
“You are how, ChatGPT hey?” (which is jumbled and doesn’t make sense)
With positional encoding, each token now carries vital information about its meaning and its exact position in the sentence. It’s like equipping the AI with a full understanding of grammar and sentence structure.
Want to visualize how these meaningful “numeric fingerprints” (embeddings) and their positions are encoded? Explore a fascinating interactive tool like the TensorFlow Projector here.
→ Now that the AI understands both the meaning of each word and its place in the sentence, it’s ready for the real magic: attention*!*
4. 🧠 Self-Attention: The Context Detective — The AI Connects the Dots
This is where the AI starts to “think” about how words relate to each other to truly grasp the sentence’s overall meaning.
Instead of just processing words one by one, the AI uses something called self-attention. This means every single word in your message actively “looks at” and calculates how important every other word in that same sentence is to its own meaning. It’s like a highly intelligent detective analyzing a complex case, connecting every clue.
Let’s get a bit more detail on how this “attention” works:
Single-Head Attention: The Foundation
Imagine you’re at a restaurant, trying to understand a new menu::
Queries are like you asking, “What should I pay attention to on this menu based on what I’m looking for?”
Keys are like each menu item announcing, “Here’s what I can offer or how I relate to your request.”
Values are the actual information or description of those menu items that you ultimately care about.
Here’s a step-by-step idea of what happens:
Every word (token) in your input message creates three versions of itself: a Query (Q), a Key (K), and a Value (V).
The Query (Q) from each word asks: “Which other words in this sentence are crucial for me to fully understand my context?”
The Keys (K) from all the other words respond: “Here’s how relevant I am to your query.”
The AI then calculates attention scores by comparing each Query with every Key. This score tells it precisely how much one word should “pay attention” to another.
Finally, the AI combines the Values (V) from all the other words, weighting them based on those attention scores. So, if a word is highly relevant, its Value contributes more to the overall understanding of the current word.
Let’s use our greeting: “Hey ChatGPT, how are you?”
When the AI is processing the token “ChatGPT”:
Its Query asks: “Which words around me are most important for my meaning here?”
The “Hey” token’s Key strongly responds: “I’m a greeting directly aimed at you!” (This gets a high attention score).
The “how,” “are,” and “you” tokens’ Keys respond: “We’re asking about your state or well-being!” (These get medium attention scores).
The “?” token’s Key responds: “I show this is a question!” (Also a medium attention score).
So, “ChatGPT” ends up paying most attention to “Hey” and moderately to the question words. This single attention mechanism gives one perspective. But what if we want multiple viewpoints for a richer understanding?
⚡ Multi-Head Attention: Multiple Perspectives
This is where it gets really powerful! The model doesn’t just run one attention mechanism; it runs multiple attention “heads” at the same time. Each “head” is like a specialized expert, learning to focus on different aspects or relationships in the text simultaneously.
For our greeting “Hey ChatGPT, how are you?”:
Head 1: Might focus on the greeting aspect (“Hey” relates strongly to “ChatGPT”).
Head 2: Might identify the question structure (“how are you?” as a complete phrase).
Head 3: Might detect the casual, friendly tone.
Head 4: Might recognize the direct address pattern (“ChatGPT” is being spoken to).
And so on… (Large models like GPT can have 12 to 96 of these “heads” in each layer!)
Each head specializes during training:
Some become experts in grammar and sentence structure.
Others focus on the deeper meaning and semantic relationships between words.
Some capture very long-range connections across the entire text.
Others handle very local word patterns.
This multi-faceted attention mechanism helps the model truly understand that your message is a casual, friendly greeting asking about well-being — not a technical inquiry about AI architecture.
Think of it like this: Instead of having just one expert analyze your message, you have a whole team of experts analyzing it simultaneously, each with their own specialty. Then, all their individual insights are combined to create a much richer and more complete understanding of what you’re trying to say.
→ After all this deep attention analysis, the data needs further processing…
5. 🧮 Feedforward & Layer Stack: Refining Understanding — The AI’s Deep Thinking Floors
So, our “Super Detective” (Self-Attention) just finished a big job. It looked at all the words in your message, “Hey ChatGPT, how are you?”, and figured out how they connect. It knows “Hey” goes with “ChatGPT,” and “how are you” is a question. It’s built a big map of all these connections.
But here’s why that’s not quite enough: Self-Attention is great at finding connections, but it gives us lots of raw, linked information. It’s like getting many different reports from different detectives. We have all the clues, but we haven’t put them all together to form one clear, big picture. We need to think deeper about these clues to truly understand.
That’s why the information doesn’t stop there. It moves to the next important part: the Feedforward & Layer Stack.
Imagine the AI’s “brain” as a tall, smart office building. Each floor is a “layer.” On each floor, there’s a special team of “mini-brains” called feedforward neural networks. Their job is to take the findings from the “Super Detective” (Self-Attention) and make them even clearer, combine them, and find deeper, more hidden patterns.
Here’s how it works, like a busy office:
# The Data Elevator: Delivering the Detective’s Findings: —
The “Super Detective” (our Self-Attention) has carefully checked your message, “Hey ChatGPT, how are you?”. It found all the ways words link up — like “Hey” linking to “ChatGPT,” and “how,” “are,” and “you” forming a question. It gathered all these important clues and connections.
Now, picture these clues, these detailed maps of word links, being put into a special “report.” This report then gets on an invisible Data Elevator. This elevator smoothly carries all that important information up to the first “floor” (or layer) of our AI’s big “thinking building.”
This isn’t just raw data. It’s the already-found connections and understandings that the attention system just uncovered. This “first report” is all about: How do these words connect to each other in the sentence? What meaning do they build together? This is the base for the deeper layers to start their more complex thinking.
# Processing on Each Floor: Deeper Analysis: —
On each floor, the feedforward neural networks (those mini-brains) get to work. They are like expert thinkers. They take the information they got from the attention part and process it more. They look for even more complex patterns and make smarter judgments. Think of them sorting, organizing, and deeply analyzing everything.
For our example, “Hey ChatGPT, how are you?”:
An early floor might confirm that “Hey ChatGPT” is a direct greeting.
A middle floor might recognize “how are you?” as a common, polite question, understanding how it’s normally used and what kind of answer to expect.
A higher floor might combine all this to figure out the full purpose of your message: a friendly, casual check-in specifically for the AI, asking about its state. This kind of deep understanding goes beyond just simple word links.
# Building Deeper Understanding, Layer by Layer: —
The main point is that this isn’t just one floor. The AI’s “building” has many, many layers stacked deep — often 12, 24, or even a huge 96 layers in the most advanced AIs!
Lower Floors (Early Layers): These are like junior workers. They focus on easier jobs, like checking basic word meanings or finding very short phrases. They take the first “attention” signals and start to make sense of small patterns.
Middle Floors: These teams are a bit more experienced. They start to understand grammar rules, sentence structures, and maybe find the main subjects and verbs in short sentences. They build on the first connections.
Higher Floors (Deeper Layers): These are the senior leaders. They take all the refined information from the lower floors and grasp the full context, the overall meaning, subtle jokes, sarcasm, or complex ideas in your message. For “Hey ChatGPT, how are you?”, these layers strongly confirm it’s a friendly, informal question, preparing the AI to give a similarly friendly reply. They are making connections across the whole conversation, not just single sentences.
# Keeping Things Flowing Smoothly: Quality Checks & Shortcuts: —
With so many layers, information could get lost or mixed up. To stop this, the AI uses smart methods:
Layer Normalization: This is like a quality check on each floor. It makes sure the information stays clean and consistent as it moves up, so nothing gets twisted.
Residual Connections: These are like special “fast lanes” or “shortcuts.” They let important information from earlier floors jump directly to later floors if needed. This makes sure important details don’t get stuck or watered down as they go through many steps. It’s key for keeping things clear and avoiding “information jams,” making sure the deep layers still have access to the basic, key facts.
So, this Feedforward & Layer Stack is where the AI truly builds its smart understanding of your message. It changes the first attention clues into deep, meaningful, and useful insights. It’s the AI’s engine for complex thinking, reasoning, and finally, giving you a good answer.
6. 🔁 Output Token Prediction: The Grand Finale — The AI’s Word-by-Word Reveal
So, the AI has done all its hard work: it’s broken down your message into tokens, understood their meanings, figured out their order, and analyzed all their complex relationships through many layers of deep thinking. Now, it’s time for the AI to respond to you!
But here’s a fascinating detail: the AI doesn’t just magically write out the entire answer all at once. Instead, it plays a very smart, high-speed “guess the next word” game, one tiny piece at a time.
Imagine the AI standing on the highest floor of its “thinking building,” looking out at all the knowledge it has. Its final task is to predict the most likely token that should come next in the conversation, based on everything it has just processed and the millions of conversations it learned from during its training.
Here’s how this amazing “word-by-word reveal” works:
First Guess: Based on your input (like “Hey ChatGPT, how are you?”), the AI thinks, “What’s the most probable first token for a polite and relevant answer?” It calculates thousands of possibilities. Let’s say it determines that “I’m” is the most likely first token (with a certain probability).
Adding to the Conversation: The AI then “types” “I’m” and immediately adds it to the conversation so far.
New Context, Next Guess: Now, the AI doesn’t just forget “I’m”. It takes your original question plus the newly predicted “I’m” as its new, updated context. It then runs its entire complex process (from tokenization to self-attention to deep layers) all over again, but this time with this longer, updated input.
Predicting the Next Word: Based on this fresh understanding, it asks itself: “Given ‘Hey ChatGPT, how are you? I’m’, what’s the next most likely token?” It might then predict “doing”.
The Loop Continues: This “predict and add” loop continues, token by token:
Predicts “well”
Predicts “thank”
Predicts “you”
…and so on, until it generates a complete, natural-sounding sentence like: “I’m doing well, thank you for asking!”
This autoregressive process — where each predicted token becomes a vital part of the input for predicting the next token — is why you often see AI chatbots “typing” their responses word by word on your screen. It’s a beautiful, continuous dance of understanding and creation that makes the AI’s replies feel remarkably human-like and responsive.
🚀 So… You Understand the Engine. Now Let’s Learn to Drive It.
We’ve peeked under the hood. We’ve demystified the engine — Transformers, tokens, embeddings, attention, GPTs.
Now you’re probably thinking:
“Cool. But what does this mean for me?”
“How do I actually build with this?”
Just like frontend developers organize UIs using components and state, GenAI builders organize apps using:
📌 Prompts (your instructions to the AI)
🧠 Context windows (how much info the AI “remembers”)
🧰 Memory + tools (giving the AI external info and abilities)
🌐 APIs etc (ways to connect your code to the AI)
— Frontend has design systems,logic, routing, and how elements show on screen.
— GenAI has prompt engineering, getting information from other places (RAG), AI assistants (agents), and linking different AI actions (chaining).
Different layers. Same mindset:
→ Understand the abstraction.
→ Build on top of it.
→ Focus on the user problem.
🛠️ Coming Up Next: Prompt Engineering — Talking to the Engine
In the next article, we’ll go deeper into the most important tool in your GenAI toolbox: Prompting. How do you talk to these models in a way that’s effective, reliable, and repeatable?
We’ll explore:
🔤 How to write great prompts (and what not to do)
🧱 Prompt templates, roles, and structured output
🧠 Giving your app memory, tools, and personality
🧪Testing prompts like you test website components.
🌍 The Future Is Being Built — Right Now
We’re still in the early days of this tech.
The engines are getting more powerful.
APIs are getting easier.
Costs are dropping.
Creative possibilities are exploding
The real magic isn’t in building “the next ChatGPT.” It’s in using these tools to solve real problems — in ways that combine human instinct with machine intelligence.
🧠 This Isn’t the Time to Fear — It’s Time to Build
Yes, it’s fast-moving. Yes, it can feel overwhelming. But you’re a builder. And builders don’t freeze when things change — they adapt, learn, and get to work.
You don’t need to master every math equation behind a Transformer. You need to know just enough to use the tools well — to make something real, something useful, something human.
The same mindset that helped you learn JavaScript, design systems, or API integration? That’s the same mindset that will help you build with GenAI..
This isn’t the end of developers. It’s the beginning of a new kind of development.
🙏 Found this helpful? Tap the 👏 below to show some love! 💬 Got questions, thoughts, feedback or wild AI ideas? Drop them in the comments — I’d love to hear from you.
Stay curious — the AI journey’s just beginning. ✨
Subscribe to my newsletter
Read articles from Rajesh Kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by