#8 - Advanced RAG: Knowledge Graph
 Mishal Alexander
Mishal Alexander
INTRODUCTION
As discussed in previous articles, a Retrieval Augmented Generator (RAG) has three main phases: indexing, retrieval, and generation. We've explored how injecting an entire data source, like a PDF, can work for small files but isn't practical for larger ones, and how chunking and vector databases can address this. However, chunking a data source doesn't preserve the relationships between entities within the content, which is problematic when dealing with personal data, stories, or understanding the context of a chat conversation. Knowledge graphs can help solve this issue. In this article, we will understand how.
KNOWLEDGE GRAPH
A knowledge graph organizes complex information as a network of interconnected entities, called 'nodes,' and their relationships, known as 'edges.' Think of entities as characters in a story, where understanding them involves knowing their relationships, like being a parent or friend, and their traits, such as liking ice cream or soccer. This is similar to how we understand people through their interactions and characteristics. In a knowledge graph, information is shown as nodes and edges, giving a complete view of the data. Working with knowledge graphs involves two main tasks: building the graph and extracting information. Building the graph involves organizing data into a connected format, accurately representing relationships and attributes. Then, you extract information by querying the graph to find patterns or insights relevant to the task, allowing for a deeper understanding of the data.
STORING THE GRAPH DATA
A question might arise -
Why can’t we store graphs in SQL or NoSQL databases like Postgres or MongoDB?
Technically, we can, but they are not optimized for graph data storage, and therefore we will have to ‘simulate’ the graph structure in accordance with the database schema. There are specialized graph databases specifically built for graph storage. One of the prominent databases for graph storage is Neo4j. It is a high-performance, mature, and robust graph store that can store graphs as nodes and relationships.
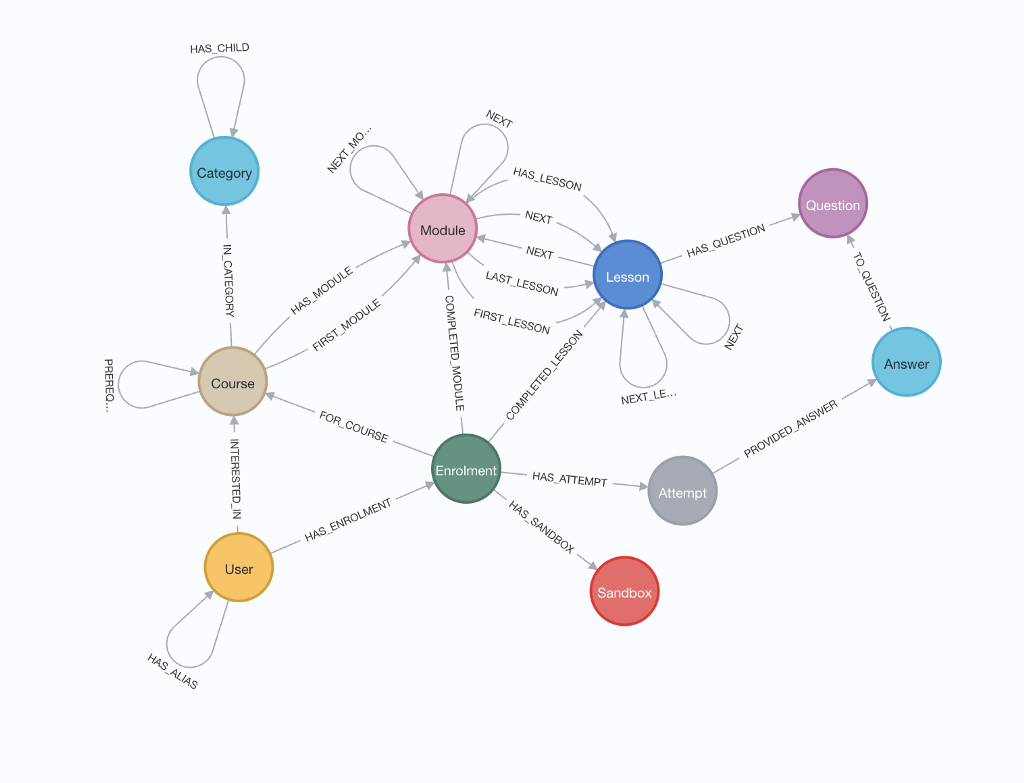
Neo4j is available both as an open-source standalone server or as an embeddable component for individual or enterprise usage. We will understand graph storage using Neo4j in this article, but the concepts can be applied to other graphs as well.
RETRIEVING DATA FROM GRAPH
To retrieve data from a graph, we need a starting point—something to act as an anchor upon which we can query for their relations and related nodes.
How do we get to this starting point?
This is an interesting question. Most likely, we might have to implement a knowledge graph in a RAG application, which has a vector database that stores vector embeddings. One approach is to convert the nodes into vector embeddings and store them in the vector database. When we retrieve the chunks from it, we get the vector embeddings for the relevant nodes present in our graph, which we can use as a starting point to query from our graph. Like how we can use SQL to query from Postgres or MongoQL to query from MongoDB, Neo4J has its own custom, easy-to-understand query language called Cypher. Cypher is similar to SQL but optimized for graphs. This is the syntax of a Cypher query: “(:nodes)-[:ARE_CONNECTED_TO]->(:otherNodes)”. Once you get the hang of it, it is easy to handle. For example, a simple Cypher query to get people who like technology from Neo4J would look like this:
MATCH (p:Person)-[r:LIKES]->(t:Technology)
RETURN p,r,t
Neo4J allows storing nodes and relationships, with each node labeled for reference and properties assigned in a key-value format (JSON format). We can communicate with Neo4J using Cypher queries, which are simple enough that even ChatGPT can efficiently generate them based on requirements. Additionally, there are two other ways to communicate with Neo4J: via langchain libraries and the mem0 library.
GRAPH DATABASE AND LLM
ChatGPT has a feature called 'memory' that stores user information, such as what the user likes. Other LLMs like Gemini have this feature as well. This feature allows it to recall details and preferences from past conversations, enabling more personalized and relevant responses in future interactions. It can be toggled on or off and managed through the settings, allowing users to control what the AI remembers and for how long. This feature, as you might have guessed, is powered by knowledge graphs. Based on the interactions, the LLM extracts relevant nodes and relations from the chat and stores them in a graph database, retrieving them when needed. This helps to keep the context window size in check even if the conversation runs over the context limit.
CONCLUSION
A knowledge graph organizes complex information as a network of connected entities, called 'nodes,' and their relationships, known as 'edges.' Imagine entities as characters in a story, where understanding them means knowing their relationships, like being a parent or friend, and their traits, such as liking ice cream or soccer. This is similar to how we understand people through their interactions and characteristics. In a knowledge graph, information is shown as nodes and edges, providing a complete view of the data. Working with knowledge graphs involves two main tasks: building the graph and extracting information. Building the graph means organizing data into a connected network.
REFERENCE
Subscribe to my newsletter
Read articles from Mishal Alexander directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Mishal Alexander
Mishal Alexander
I'm passionate about continuous learning, keeping myself up to date with latest changes in the IT field. My interest is in the areas of Web Development (JavaScript/TypeScript), Blockchain and GenAI (focusing on creating and deploying memory aware AI-powered RAG applications using LangGraph, LangFuse, QdrantDB and Neo4J). I welcome professional connections to explore new ideas and collaborations.