Why High-Performance ML Matters in 2025: From GPUs to Reasoning Agents
 Gopala Krishna Abba
Gopala Krishna AbbaTable of contents
- AI Is Everywhere: The Purpose Behind This Blog Series on High-Performance ML
- AI Startup Landscape & Trends
- The Turning Point — When AI Became a Household Name
- From "Thinking Fast" to "Thinking Smart": Why Inference Performance Matters
- Breaking Through the Memory Wall: What's New in 2025?
- Explosive Growth Across Domains: AI Is Eating Software (and More)
- AI That Thinks Must Also Scale – From AlphaGo to Real-Time Agents (Latency Context)
- References

AI Is Everywhere: The Purpose Behind This Blog Series on High-Performance ML
It’s 2025, and AI has transcended hype. It's embedded in our phones, our homes, our productivity apps, even our artwork and creative expressions. Just think back to the viral Ghibli-style art trend of March 2025, when people spammed Studio Ghibli prompts into DALL·E 3 so relentlessly that OpenAI’s CEO Sam Altman joked they were "melting GPUs." That moment wasn’t just cute. It was proof that AI-generated art had hit the cultural mainstream and inference systems weren’t ready for it.

Image source: X.com - A tweet by Sam Altman CEO of OpenAI discusses the popularity of image features in ChatGPT and announcing temporary rate limits due to high GPU usage.
From ChatGPT to autonomous agents, recommendation engines to real-time video analytics, the capabilities of modern AI systems are breathtaking and growing exponentially.
Last semester, I took a course at NYU on High Performance Machine Learning, where I learned the details of how AI systems are scaled, optimized, and deployed in real-world settings. I received top grades in the course, but more importantly, I understood why performance matters—beyond just the theory. This blog series is my way of sharing that journey, covering topics like modern AI infrastructure, memory bottlenecks, distributed training, compiler optimizations, and more.
The AI landscape has drastically evolved over the last few years: the rise of large language models (LLMs), agentic workflows, AI copilots, and multimodal systems like GPT-4o have reshaped the field. This first article explores the motivation: Why study performance in AI, and why now?
Throughout the course, I discovered several compelling answers:
AI is no longer a niche—it's everywhere: language, vision, robotics, healthcare, finance, and beyond.
Inference cost and latency have become critical bottlenecks in real-world AI applications.
Even open-source models like LLaMA 3 and Mistral require heavy optimization (e.g., quantization, spec. decoding) for practical deployment.
Trends like quantization (e.g., GPTQ, AWQ – dominant quantization toolkits for 4-bit and 8-bit inference as of mid-2025), acceleration (vLLM, FasterTransformer – widely adopted for efficient transformer inference across research and production), and hardware innovation (NVIDIA Blackwell, AMD MI300X – 2024/25 flagships in data center-class AI compute) are reshaping AI performance engineering.

Image Source: Techniques like quantization (e.g. GPTQ, AWQ) and speculative decoding are essential for efficient inference of large open‑source models. J. Lee, S. Park, J. Kwon, J. Oh, and Y. Kwon, “Exploring the trade-offs: Quantization methods, task difficulty, and model size in large language models from edge to giant,” arXiv preprint arXiv:2409.11055, 2025. https://arxiv.org/pdf/2409.11055

Image Source: Serving LLMs on AMD MI300X: Best Practices. vLLM delivers outstanding performance on the AMD MI300X, achieving 1.5 times higher throughput and 1.7 times faster time-to-first-token (TTFT) compared to Text Generation Inference (TGI) for Llama 3.1 405B. It also achieves 1.8 times higher throughput and 5.1 times faster TTFT than TGI for Llama 3.1 70B. This guide covers 8 important vLLM settings to boost efficiency, showing you how to use the power of open-source LLM inference on AMD. Reference: https://blog.vllm.ai/2024/10/23/vllm-serving-amd.html

Image Source: NVIDIA Blackwell offers up to 2.6x better performance in MLPerf Training v5.0. Reference: https://developer.nvidia.com/blog/nvidia-blackwell-delivers-up-to-2-6x-higher-performance-in-mlperf-training-v5-0/
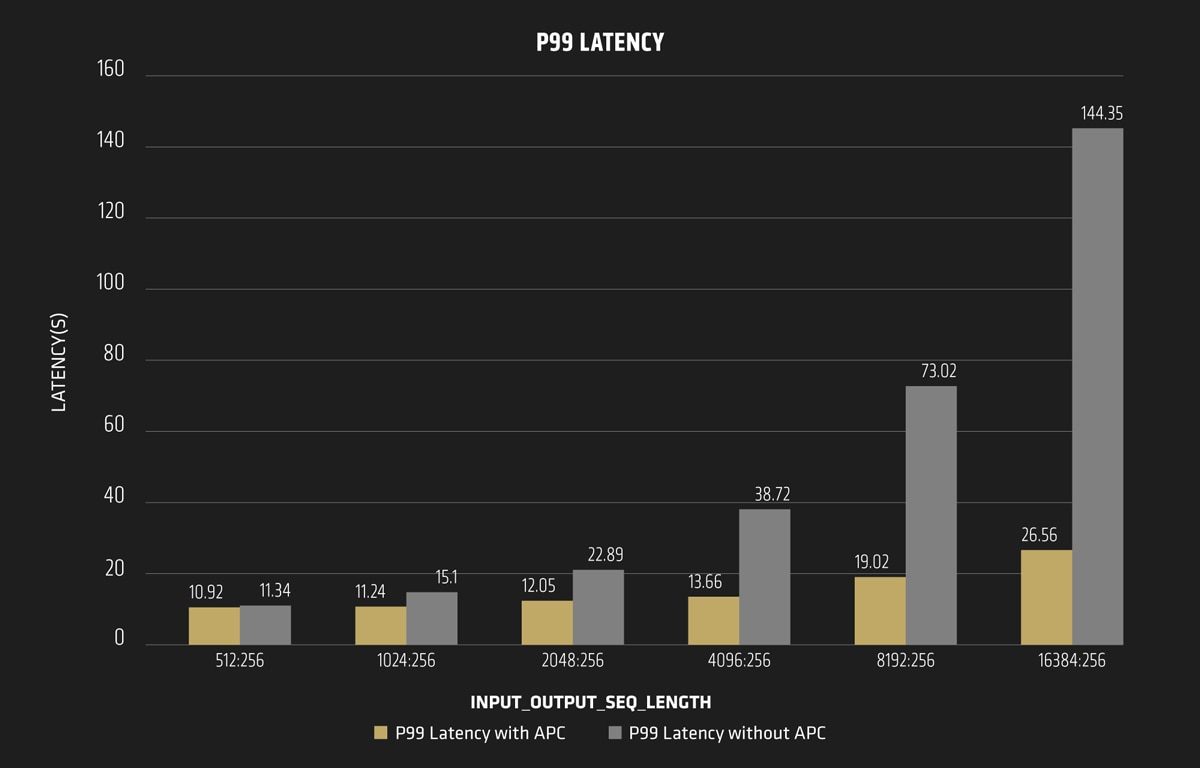
Image source: Llama3.1-70B, P99 Latency With/Without Automatic Prefix Caching (APC). 5X Speed Up: Significant Latency Reduction with Prefix Caching. Reference: https://www.amd.com/en/developer/resources/technical-articles/vllm-x-amd-highly-efficient-llm-inference-on-amd-instinct-mi300x-gpus.html?utm_source=chatgpt.com
HPML is essential for making AI practical, scalable, and ready for deployment, especially at the edge and in production environments.
AI Startup Landscape & Trends
The AI startup landscape has exploded in just 8 years. CB Insights and PitchBook reported more than 17,000 AI-related startups by mid-2025. AI funding topped $170B+ globally in 2024. What was once categorized into a few blocks of Computer Vision, NLP, and Recommendation Engines is now a universe of vertical and horizontal agents, RAG-powered copilots, foundation models, and domain-specific agents.

Image source: CB Insights AI 100 (2025): https://www.cbinsights.com/research/report/artificial-intelligence-top-startups-2025/ | Used under fair use for educational commentary.

Image source: Sequoia Capital Generative AI Market Map: https://www.sequoiacap.com/article/generative-ai-act-two/ | Credit: Sonya Huang, Pat Grady, Sequoia Capital. | Used under fair use for educational commentary.
| Theme | Insight from 2025 Reports |
| Explosion of AI startups | CB Insights tracked 17,000+ companies. AI funding surpassed $170B. |
| Rise of AI agents | More than 20 % of AI 100 winners focus on autonomous task completion (LangChain, Dropzone, BabyAGI) and these tools dominate GitHub and the open-source AI agent ecosystem. |
| Shift to verticalization | Companies like Eve (legal), Overjet (dental), and Lila (life sciences) show the trend. |
| Performance bottlenecks | Demand for GPUs is now the supply-side constraint, not user demand. This a known constraint verified by multiple sources like the AI Index Report 2025 and SemiAnalysis. |
| Agentic workflows need speed | Inference cost dropped 280× since GPT-3.5 (AI Index 2025). Optimized infra is the new frontier. |
| Generative AI fatigue | Only Median DAU/MAU ≈ 14% retention for most GenAI apps. Performance and real value matter now more than hype. |
Table 1: 2025 AI Landscape – Trends, Stats & Signals
In 2017, AI was still largely categorized into "smart robots," "gesture control," and "speech transcription" but the applications were narrow, and the infrastructure, even narrower. Fast forward to 2025, and the picture is drastically different. CB Insights’ latest AI 100 and Sequoia Capital’s updated market map show a rich ecosystem of vertical AI companies (like healthcare, legal, and manufacturing), autonomous agents, LLM observability platforms, and edge-optimized compute startups.
AI Index 2025 Report (Stanford HAI)
AI is no longer just a tool for research labs or tech giants. According to the AI Index 2025, 78% of organizations reported using AI in 2024, up from 55% in 2023. From AI copilots in Microsoft Office to legal assistants like Harvey and creative agents in Runway or Character.ai, it’s clear: AI is now part of everyday life.
Behind the scenes, performance demands are rapidly increasing. The same report shows that inference costs have decreased by 280 times since GPT-3.5, but the need for faster processing (like LangChain, vLLM, quantization, edge chips) is higher than ever, and demand has surpassed supply. GPU shortages, energy limitations, and model size have become the new bottlenecks.

Image Source: The 2025 AI Index Report | Stanford HAI
System 1 vs. System 2 AI (Sequoia Capital – "Generative AI's Act 01")
In 2024, we've entered what Sequoia calls the "Agentic Reasoning Era," marking a shift from pre-trained pattern matching (System 1) to deliberate inference-time reasoning (System 2). OpenAI's o1 model (formerly Q*) represents a significant advancement, introducing "inference-time compute" as a new frontier in model performance.
This means models don’t just respond quickly. They pause to simulate, reason, and sometimes even backtrack before answering. Think AlphaGo for reasoning: given more time, the model performs better. This is a dramatic shift in how AI systems are built, and it has deep implications for hardware, inference scaling, and agent architecture.
| Key Concept | Relationship to HPML |
| System 1 vs. System 2 Thinking | HPML is the fuel that powers deliberate, inference-time reasoning (System 2 AI). |
| Inference-Time Compute | A new scaling law focuses on performance, which depends on scheduling, batching, and optimizing latency. |
| Cognitive Architectures | Contrasts "vanilla LLMs" with structured agents (e.g., LangGraph) that require efficient pipelines. |
| Application Layer Opportunity | The application layer succeeds by focusing on task-specific performance, which includes speed and reliability. |
| Multi-Agent Reasoning | Multi-agent systems raise challenges in GPU memory allocation and prompt compression. |
| Strawberry / o1 Model and inference-time planning | Case study of modern inference-time reasoning vs. fast-response GPT-3.5-style models: OpenAI’s o1 and Anthropic’s Claude 3 implement more deliberate reasoning vs pure next-token generation. |
Table 2: How Inference-Time Reasoning Shapes Modern AI
(Insights in this section are drawn from Sequoia Capital’s “Generative AI’s Act 01” (2024) by Sonya Huang and Pat Grady: https://www.sequoiacap.com/article/generative-ais-act-o1/. All credit goes to the original authors)

Image Source: Generative AI's Act o1: The Reasoning Era Begins | Sequoia Capital
HPML is about these very pressures: how compute, memory bandwidth, and latency affect model scalability. Reading about cognitive architectures and agentic workflows in Sequoia’s report made me realize that High performance ML is no longer a nice-to-have, It’s essential to power these reasoning-era applications.
Meanwhile, CB Insights’ AI 100 (2025) highlights a new wave of startups: agentic systems, vertical AI for healthcare and finance, and AI security infrastructure. These players are solving high-stakes problems, and they all demand high-performance machine learning under the hood. This is the world where High Performance Machine Learning matters.
The Turning Point — When AI Became a Household Name
Until late 2022, large language models were mostly discussed within academic papers, research labs, and technical communities. That changed overnight with the public release of ChatGPT.
In just a few weeks, the model captured global attention. ChatGPT was no longer a technical demo. It became a cultural phenomenon, making headlines across The New York Times, Bloomberg, The Wall Street Journal, and The Washington Post. Schools banned it. Companies adopted it. Enterprises began integrating LLM APIs into tools and workflows in Q1–Q2 2023. Developers explored its APIs. Suddenly, AI wasn’t confined to models or metrics, it was everywhere, used by everyone. ChatGPT reached 100 million users in ~2 months, the fastest adoption in tech history at the time.

The release of ChatGPT wasn’t just the start of the generative AI era. It marked the beginning of a new reality:
AI was no longer judged just by its intelligence, but by its speed, reliability, and ability to scale.
Inference speed and response coherence became core UX expectations. Startups and enterprises began optimizing for latency, throughput, and cost-per-token. This moment shifted the public’s expectations for AI. People now assumed:
Responses would be fast and coherent.
Agents could complete complex tasks.
AI could be deployed safely in real-world applications.
Behind these assumptions lies a difficult truth: LLMs are expensive and computationally intensive to run, especially at scale.
LLMs need more than just accuracy, they need performance. Why is this important for high-performance ML? Because LLMs involve inference-heavy workloads, and real-world usage isn't just about getting an answer, it's about:
Latency (How fast you get a response: Models are expected to respond <1s for real-time UX)
Memory usage (can it fit in consumer GPUs? Whether a model fits on an A100, consumer GPU, or mobile device is crucial for edge/local deployment)
Inference cost (Every token costs compute: Serving GPT-4-class models in 2025 can cost $0.40–$8.00 per 1K output tokens, making inference the primary bottleneck at production scale [OpenAI API Pricing, 2025])

Image Source: The chart shows Nvidia's slowing revenue growth. Supply issues are limiting deliveries even as demand increases. Its triple-digit growth ended in the third fiscal quarter. Reference: https://www.reuters.com/technology/nvidias-supply-snags-hurting-deliveries-mask-booming-demand-2024-11-21/ | Used under fair use for educational commentary.
LLM inference (especially autoregressive decoding) is:
Sequential, limiting full GPU utilization.
Cost-intensive, especially for chat agents or multi-agent use cases.
Latency-sensitive, especially in consumer and enterprise-facing tools.
If you're using GPT-4 in a chatbot or developing an agent with a model like Mixtral (a Sparse Mixture of Experts model with about 12.9 billion active parameters out of 46.7 billion total) or Claude (which provides a 200K–1M token context, but where inference cost and memory usage are major concerns), then the model's performance during inference is just as crucial as its training quality. This is where the next frontier starts.
From "Thinking Fast" to "Thinking Smart": Why Inference Performance Matters
Sequoia Capital recently discussed the industry's shift from System 1 AI, which provides quick, instinctive responses, to System 2 AI, which involves models that can pause, think, and plan. [Note: The System 1/System 2 analogy is from Kahneman's Thinking, Fast and Slow]
| System 1 (GPT-3.5) | System 2 (GPT-4o, o1, Claude 3) |
| Fast, next-token decoding | Pauses, simulates, and reroutes logic |
| Shallow reasoning | Multi-step planning |
| Low latency, high cost | Slower but rich output |
Table 3: Comparing System 1 vs System 2 Reasoning in LLMs

Image Source: OpenAI o1 technical report | Used under fair use for educational commentary.
This new generation of "agentic" systems, like OpenAI's o1 (Strawberry), Anthropic's Claude 3, and Mistral's Mixtral, doesn't just provide quick answers. These models think. They explore possibilities, backtrack, evaluate outputs, and adjust logic paths, all during inference.
But that ability to think deeply comes with a cost:
Slower inference latency
Higher memory demands (Memory footprint)
Heavier GPU requirements
Complex scheduling, which can lead to overhead, and prompt compression trade-offs (such as in vLLM, DeepSeek-V2, or MoE models)
And this is exactly why High Performance Machine Learning matters more than ever. To manage these costs while improving capability, today's leading models, from Claude 3 to GPT-4o, rely on sophisticated techniques like Mixture of Experts (MoE) to activate only parts of the model for each query, and speculative decoding to reduce latency.
While foundational model pre-training has historically been the bottleneck, inference is now the front line for productized AI systems. If an AI agent takes 20 seconds to respond or can't run on a mobile device, users will leave, and companies will lose money. Even the latest models from Meta and OpenAI show longer processing times for reasoning-style outputs.
From ChatGPT’s global adoption to o1’s inference-time breakthroughs, all signs point to the same truth:
Performance is now a product feature.
This idea is central to modern LLM deployment:
Users care about response speed and quality.
Businesses care about serving costs, hardware requirements, and user churn.
Many enterprise buyers in 2025 explicitly benchmark LLMs on latency, J/accuracy, and time-to-first-token. This blog series is my way of breaking those concepts down and connecting them with what’s happening in the real world:
What makes inference slow?
Can batching or quantization reduce costs?
Why is GPU memory management a dealbreaker for multi-agent systems?
How do you actually serve a model that “thinks” in multiple steps?
What’s the cost of running open-source models in production?
Can quantization or batching save $1M in cloud bills?
How to manage VRAM for agent stacks?
These aren’t academic questions anymore. All of this aligns with real-world practices in 2025 at places like Hugging Face, MosaicML, Runway, Character.ai, and LangChain. They’re exactly what AI companies are grappling with in 2025. My goal is to explore them one by one, through a mix of research, real-world examples, and practical insights from my coursework.
If you're an AI builder, researcher, or recruiter looking for someone who understands both the math behind the model and the system that delivers it, I hope this series helps demonstrate that balance.
Breaking Through the Memory Wall: What's New in 2025?

Image source: Training FLOPs scaling vs. memory/interconnect growth, from Gholami et al. ‘AI and Memory Wall’ (arXiv Mar 2024) https://arxiv.org/pdf/2403.14123
The graph above shows the increase in training compute over time. The x-axis represents the years from 2012 to 2021, and the y-axis shows training compute in PetaFLOPs. Blue points represent non-transformer models like AlexNet, VGG, and ResNet, while red points represent transformer models like BERT, GPT-3, and Microsoft T-NLG. The graph highlights a steeper increase for transformers, noting "750x / 2 yrs" for transformers compared to "2x / 2 yrs" for Moore's Law.
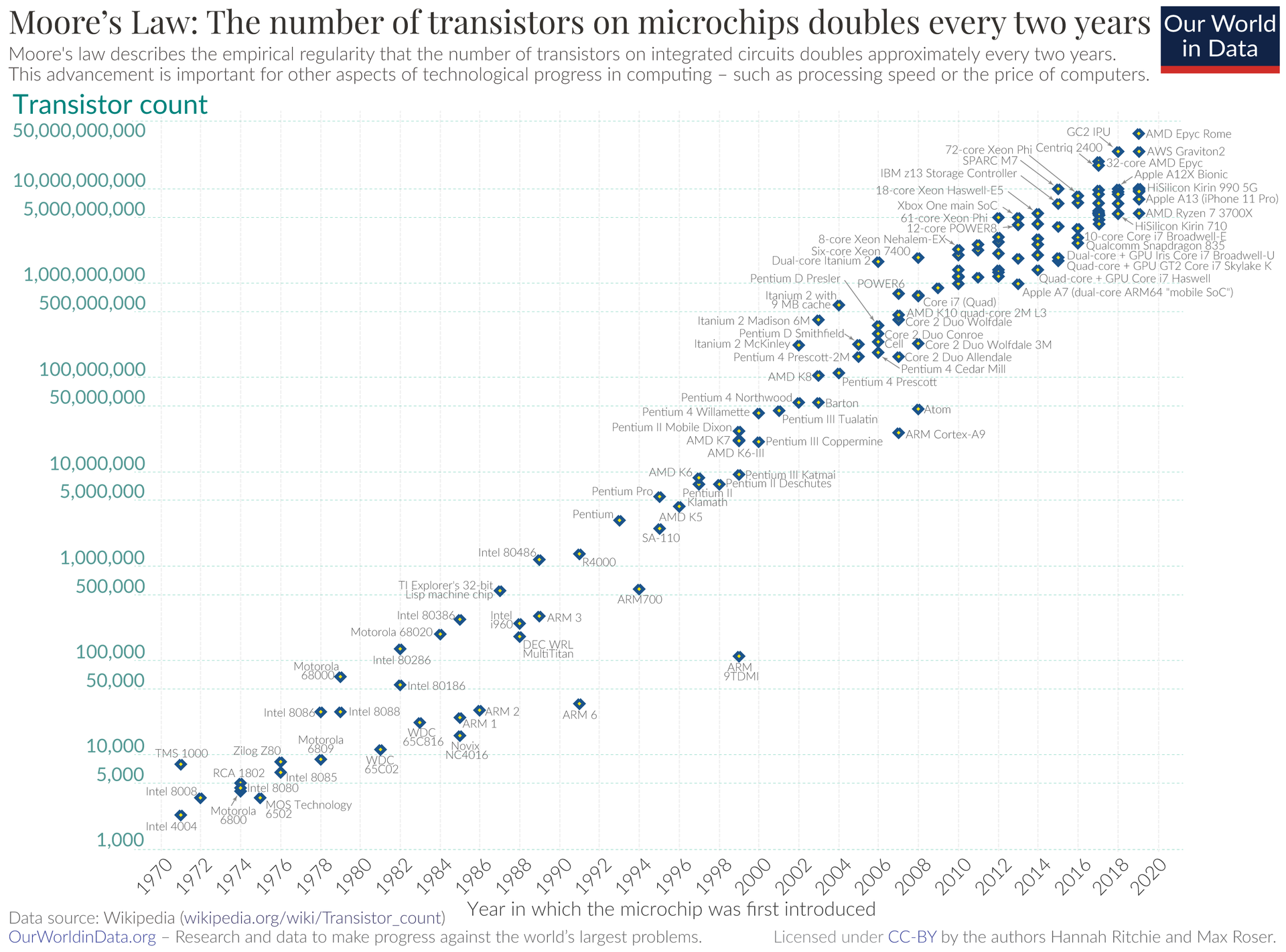
Image Source: wikipedia.org | Used under fair use for educational commentary.
There is a disparity between compute and memory bandwidth: Compute performance grew ~60,000× over 20 years, but DRAM and interconnect only ~100×/30×. This disparity shifts bottlenecks from compute to memory bandwidth, especially for decoder-based LLMs. The AI and the Memory Wall paper highlights that compute (FLOPs) has far outpaced memory subsystem improvements, which is especially problematic for LLMs.
This is important because while model size and computing power keep growing rapidly, memory systems are not advancing at the same rate. Recent papers confirm this. For example, 2025 studies show that inference remains limited by memory, even with large batches. Recasens et al. (Mar 2025) demonstrates that inference for LLMs is still memory-bound at scale and suggests memory-aware batching strategies.

Image Source: Recasens et al. (Mar 2025)
Performance versus arithmetic intensity of attention and matrix multiplication kernels for batch size 1 and the maximum batch size (MAX). While batching increases the arithmetic intensity of matrix multiplications, the arithmetic intensity of xFormers and FlashAttention attention kernels—two memory-optimized attention implementations—remains nearly constant, causing DRAM saturation. The data was collected using NVIDIA Nsight Compute from the last decode step of OPT-1.3B on an H100 GPU.
Emerging research from 2025 (Altayo et al., May 2025) proposes a three-tier on-chip memory system to ease this bottleneck. This involves a multi-level memory hierarchy to address bandwidth limits in data-parallel AI workloads.

Image Source: Altayo et al., May 2025: Memory hierarchy and interconnect of two implementation variants of the proposed architecture.
While the chart from Gholami et al. (2024) captures the explosive scaling of AI compute over the past decade, the real bottleneck isn’t just about FLOPs anymore, it’s about memory and data movement. As we step into 2025, new research is starting to redefine how we architect AI systems to push past this memory wall.
Hardware Innovation: A Smarter Memory Hierarchy
In May 2025, Altayó et al. introduced Provet, a vector processor architecture with a three-tier on-chip memory hierarchy: global SRAM, an ultra-wide register buffer (VWR), and local SIMD registers.
Instead of relying purely on high-bandwidth DRAM or systolic arrays, Provet optimizes on-chip data movement using:
A wide and shallow SRAM for scalable bandwidth,
A Very Wide Register (VWR) for intermediate reuse without address decoding overhead, and
Local SIMD registers for fast compute loops.
This architecture drastically reduces global memory accesses, particularly for irregular AI workloads like MobileNet, and improves latency and energy efficiency without relying on heavy data reuse.
Why it matters: As models scale, memory — not compute — becomes the bottleneck. FLOPs are irrelevant if your memory can’t feed the compute cores fast enough.
Memory is now a first-class design constraint, not an afterthought. FLOPs ≠ system performance if memory can't feed the compute cores in time.
Software: Smarter Batching for Inference – The Rise of Memory-Aware Inference Software
On the software side, the move towards lower precision formats is critical. Techniques like FP8 training, supported by NVIDIA's Hopper architecture, and widespread INT4 quantization for inference are no longer niche optimizations but standard practice for deploying large models.
Recasens et al. (March 2025) introduced a tool called the Batching Configuration Advisor (BCA) for smarter memory-aware inference. It adjusts batch sizes and activation schedules during inference to maximize memory reuse without exceeding device RAM, which is especially useful for handling multiple queries in LLM serving. This is part of a larger 2025 trend towards smarter orchestration and memory scheduling, similar to FlashAttention-2 and vLLM’s dynamic kernel fusion. They demonstrate that even with large batch sizes, memory bottlenecks (such as bandwidth and activation reuse) are more important than raw computing power.
Why it matters: BCA lets you serve larger, deeper models on commodity GPUs, and even improves throughput without needing to quantize or offload layers.

Image Source: Recasens et al. (March 2025): Percentage of warp cycles per instruction that are stalled or idle while waiting for data. The results are gathered for all tested models using both no-batch inference and the maximum batch size. We use the xFormers and FlashAttention backends for the attention mechanism, but note that the OPT-2.7B model is not compatible with FlashAttention. Each result is the average of the first 5 kernel executions from the last decode step.
Outlook: Memory-Centric AI is the Next Frontier
Together, these innovations suggest a significant change in AI system design:
From focusing on FLOP-heavy scaling to prioritizing bandwidth-optimized efficiency
From viewing memory as a simple storage to making memory architecture a key part of ML design
As LLMs advance into real-world reasoning and multi-agent systems, memory bandwidth, locality, and scheduling will become just as important as model size or pretraining data. The future of high-performance machine learning will be determined not just by GPU cycles, but by how efficiently we manage data movement.
Explosive Growth Across Domains: AI Is Eating Software (and More)
Since the launch of ChatGPT, generative AI has not only captured imaginations but also redefined expectations across every industry. From code generation (e.g., GitHub Copilot, Amazon CodeWhisperer)and drug discovery (e.g., NVIDIA BioNeMo) to game design (e.g., Convai, Inworld), supply chain optimization (e.g., NVIDIA cuOpt + LLM agents), and customer support (e.g., Intercom Fin, Cohere Command R+, GPT-4 in Zendesk), we are witnessing an AI arms race in real-time. Each field is adopting large language models (LLMs) and multimodal systems, not as novelties, but as core infrastructure. This isn't just "software is eating the world." This time, AI is automating the thinking parts of work.
But with scale comes friction. For example:
A model trained on 2 trillion tokens still struggles with long-context retrieval.
Multi-modal assistants like Gemini or GPT-4o require specialized hardware. They are resource-intensive, requiring custom hardware stacks (e.g., NVIDIA Blackwell — optimized for FP4, Hopper interconnects, TPUs — tightly integrated for Gemini and Meta's MTIA, Amazon Trainium, or ASICs used for inference-optimized stacks).
Agentic systems (e.g., LangGraph, Autogen, CrewAI) composed of multiple LLM calls run into latency bottlenecks i.e., incur multi-LLM-call latency bottlenecks, especially over API.
Quantized models save memory but often lose performance in edge cases.
As model quality improves, performance demands increase significantly. Enterprises no longer just ask, "Can it reason?" They now ask:
Can it do so in under 500ms?
Can it scale to 10,000 users concurrently?
Can we afford it at 1/10th the cost of OpenAI API calls? (especially compared to OpenAI API costs, which can range from $8 to $20 per million tokens)
This shift is why High Performance Machine Learning (HPML) is a foundational discipline in the 2025 AI stack. It has shifted from niche to necessary for every part of modern AI:
Inference memory layout
Pipeline scheduling
On-chip hierarchy design
Quantization & activation offloading
Prompt caching and batching
AI That Thinks Must Also Scale – From AlphaGo to Real-Time Agents (Latency Context)

Image Source: AlphaGo
Back in 2017, AlphaGo proved that an AI agent could reason its way through complex scenarios. But that reasoning was computationally immense, while it played within match time limits, each move was the product of thousands of Monte Carlo Tree Search simulations running on significant compute clusters (TPUs). The underlying model was trained for weeks. In 2025, companies need that same depth of thinking but at sub-second inference speeds, with real-time user feedback and production-grade reliability. For instance, agentic systems using frameworks like o1 or LangGraph must operate at real-time latency (<1 sec), especially in chat, task automation, or AR applications. It’s a real challenge at inference scale.
This is the heart of the motivation behind HPML:
How do we build AI systems that don’t just think but do so fast, affordably, and reliably across scale?
It’s not just about faster hardware. It’s about smarter batching, model distillation, multi-agent memory sharing, caching, context routing, and dozens of other hard engineering problems.
In short, we're at an inflection point. The models are powerful. The ideas are here. But we need new engineering paradigms to:
Make reasoning scalable
Serve users in real time
Deploy agentic architectures safely and affordably
That’s what High Performance Machine Learning (HPML) is all about. It’s not just a research topic anymore, it’s a job requirement for every AI engineer building the next generation of applications, platforms, or research tools. AI engineers must now understand system design:
Batching, context management, caching
Memory hierarchies
Parallel decoding
Quantization, distillation
This has become core to making models usable in production, especially for startups and infrastructure-focused companies.Whether you're building copilots or debugging token latency in production, I hope this series helps you understand how performance becomes a feature and why it’s now non-negotiable.
I realized that building the future of AI isn't just about understanding models. It's about making them run efficiently, safely, and at scale. This blog series is my deep dive into that performance layer, where systems engineering meets deep learning. From inference bottlenecks to memory hierarchies and model compression, I'll explore how performance engineering fits into the new world of AI agents and reasoning layers.
This series will explore the performance aspects of the AI boom, covering topics from data loading challenges to transformer acceleration techniques, based on my experience in HPML. Stay tuned if you're an engineer, researcher, or founder working with the new AI stack.
References
Altayo et al., Addressing memory bandwidth scalability in vector processors for streaming applications, arXiv May 2025
Recasens et al., Mind the Memory Gap: Unveiling GPU Bottlenecks in Large-Batch LLM Inference, arXiv Mar 2025
NYU’s High Performance Machine Learning coursework (Spring 2025)
This post brings together research and coursework from NYU’s High Performance Machine Learning class (Spring 2025), where I studied advanced AI systems design.
Disclaimer: All third-party images remain the property of their respective owners and are reproduced here solely for educational commentary. If you are a rights holder and prefer an image to be removed or replaced, please contact me at gopala.ai.ml@gmail.com.
Subscribe to my newsletter
Read articles from Gopala Krishna Abba directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by