Memory Access Demystified: How Virtual Memory, Caches, and DRAM Impact Performance
 Sachin Tolay
Sachin TolayModern software performance is deeply influenced by how efficiently memory is accessed. The full story of memory access latency involves multiple layers → from CPU caches to virtual memory translation, and finally to physical DRAM. This article explains the latency involved in different types of virtual memory accesses, and reveals how these latencies affect overall system performance.
If you haven’t already, I recommend reading my previous article on DRAM Internals: How Channels, Banks, and DRAM Access Patterns Impact Performance, which details the physical memory subsystem. This article builds upon that foundation and focuses on the virtual memory side.
What Is Virtual Memory?
Physical memory refers to the actual hardware (DRAM) where the data is actually stored.
Virtual memory is an abstraction that allows your applications to use a private, large, contiguous address space regardless of the underlying physical memory layout. The OS and hardware work together to translate virtual memory addresses (used by your applications) into physical memory addresses (used by DRAM) for data access.
Why Do We Need Virtual Memory ?
Virtual memory is crucial because it solves several key problems :-
- Process Isolation: It allows each process to operate in its own private virtual address space, preventing it from accidentally or maliciously accessing another process’s memory.
With virtual memory:
// Process A int *secret = malloc(4); *secret = 42; // Safe from Process BThe memory address of secret is a virtual address, which is relative to Process A’s private virtual address space (detailed in the upcoming sections).
Without virtual memory (hypothetical example):
// Process A int *shared = (int *) 0x1000; // Absolute physical address in DRAM *shared = 42; // Could overwrite memory used by Process BNote: Today, user-space code cannot directly access physical addresses like 0x1000 because virtual memory is already in place and enforced. Such access is typically restricted to kernel-mode or driver code. This example is purely hypothetical and illustrates what could go wrong without virtual memory and process isolation.
Simplified Memory Management: Virtual memory gives applications a clean, contiguous address space, even if physical memory is fragmented or limited. This simplifies programming and memory allocation.
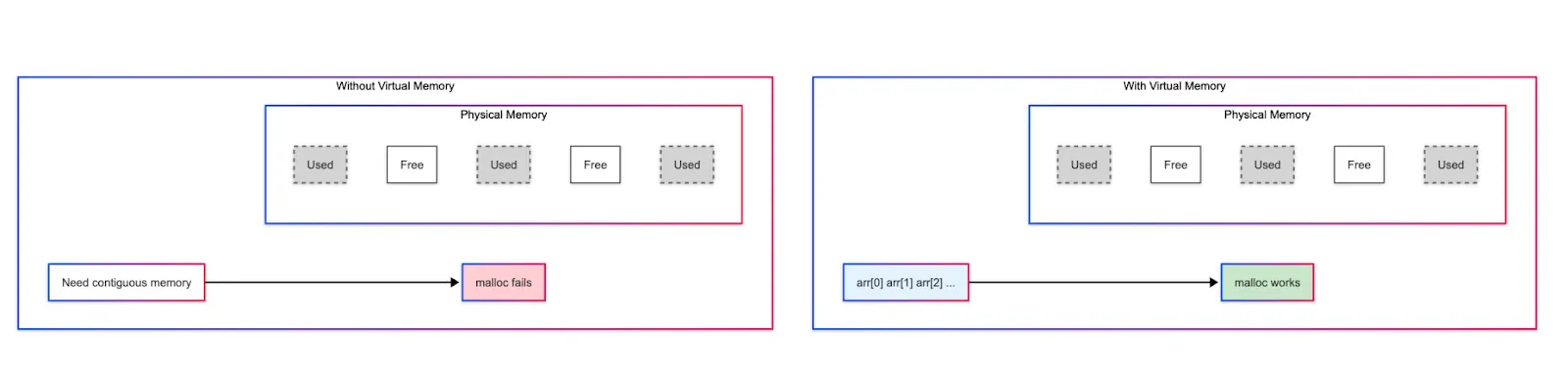
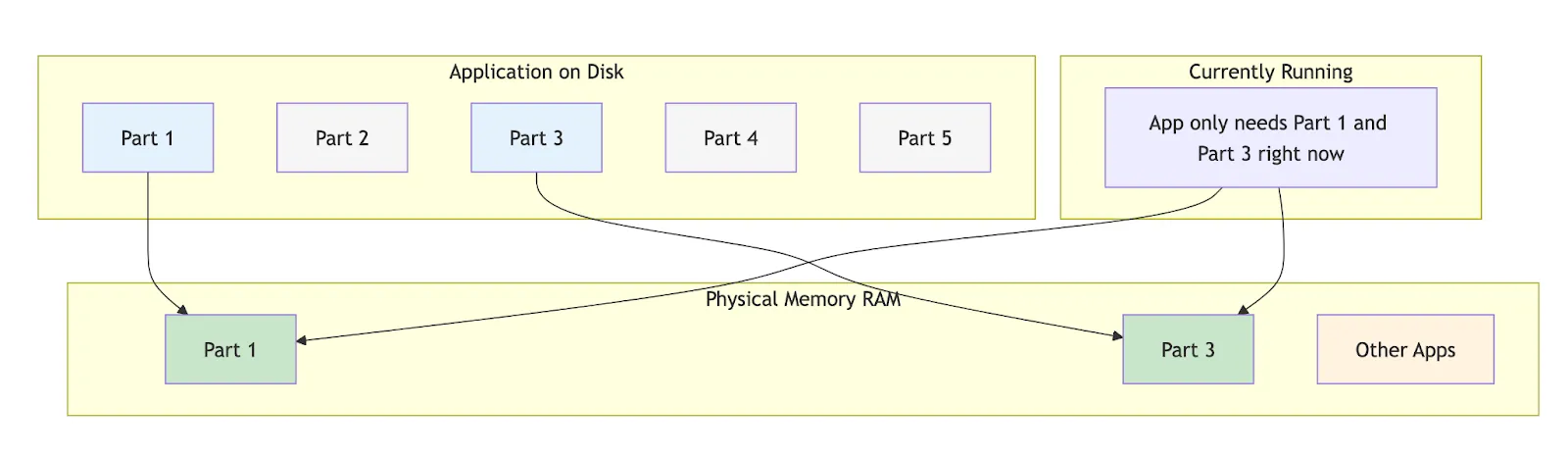
Efficient Use of Physical Memory: Only the required parts of an application or file are loaded into physical memory when needed, saving resources. This is called demand paging (more on this later).
Ability to Allocate More Than Available Memory: The system can promise more memory to applications than physically exists because many applications are either idle or only use a portion of their allocated memory at any given time.
int *big_array = malloc(10000000 * sizeof(int)); // Request large memory block
Without this ability to overcommit, such allocations would fail immediately even if the memory might not be fully used.
Virtual Memory Implementation: Representation and Address Translation
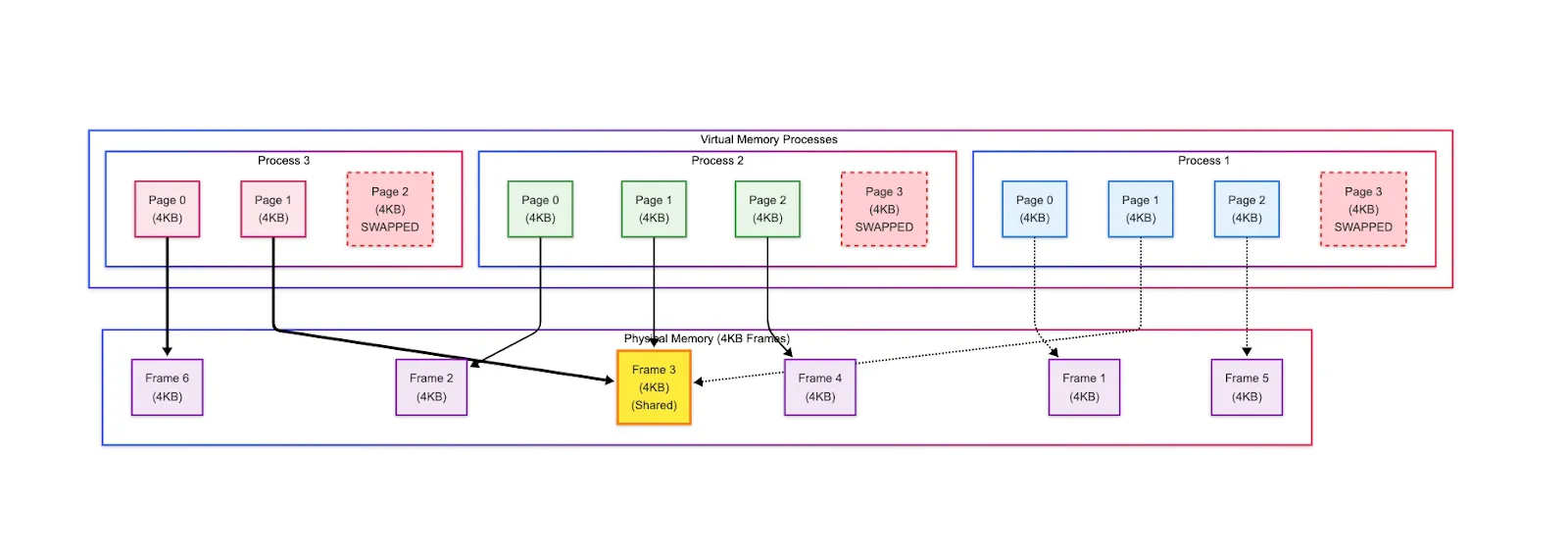
Paging
Virtual memory is divided into fixed-size pages of memory (typically 4 KB), which serve as the basic units of memory management and translation.
Physical memory (DRAM) is divided into frames of the same size.
Each process gets its own isolated 48-bit virtual address space (up to 2⁴⁸ bytes = 256 TB), even if actual available physical memory is far smaller.
Only the pages that an application actually uses are stored in DRAM(/disk). It allows the OS to manage memory far more efficiently than if it had to allocate physical memory for everything upfront.
Each virtual page maps to exactly one physical frame when loaded. This mapping mechanism is managed by the OS through a data structure called Page Table.
Page Table
Virtual memory uses a 4-level index-like data structure called Page Table to store the mapping between virtual pages (used by applications) and physical frames (actual locations in DRAM).
As shown in the diagram below, the Page Table is organized as a hierarchy of 4 levels, each representing a stage of address translation, finally leading to the Page Table Entry (PTE), which contains the actual mapping to the physical frame:
Level 1 → Page Map Level 4 (PML4) Table, contains entries pointing to Level 2 tables.
Level 2 → Page Directory Pointer Table (PDPT), contains entries pointing to Level 3 tables.
Level 3 → Page Directory Table (PD), contains entries pointing to Level 4 tables.
Level 4 → Page Table (PT), contains entries called Page Table Entries (PTEs) that point directly to physical frames.
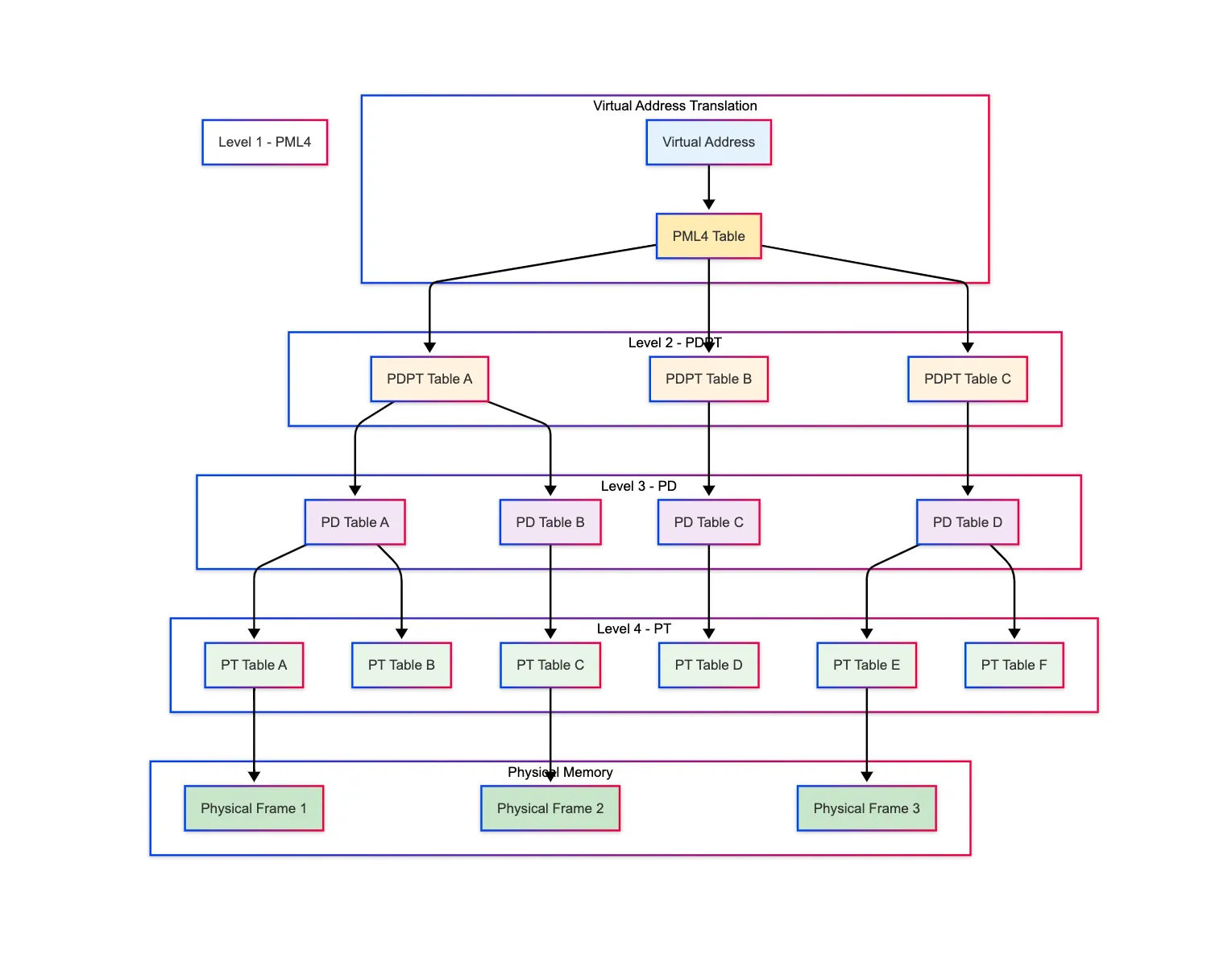
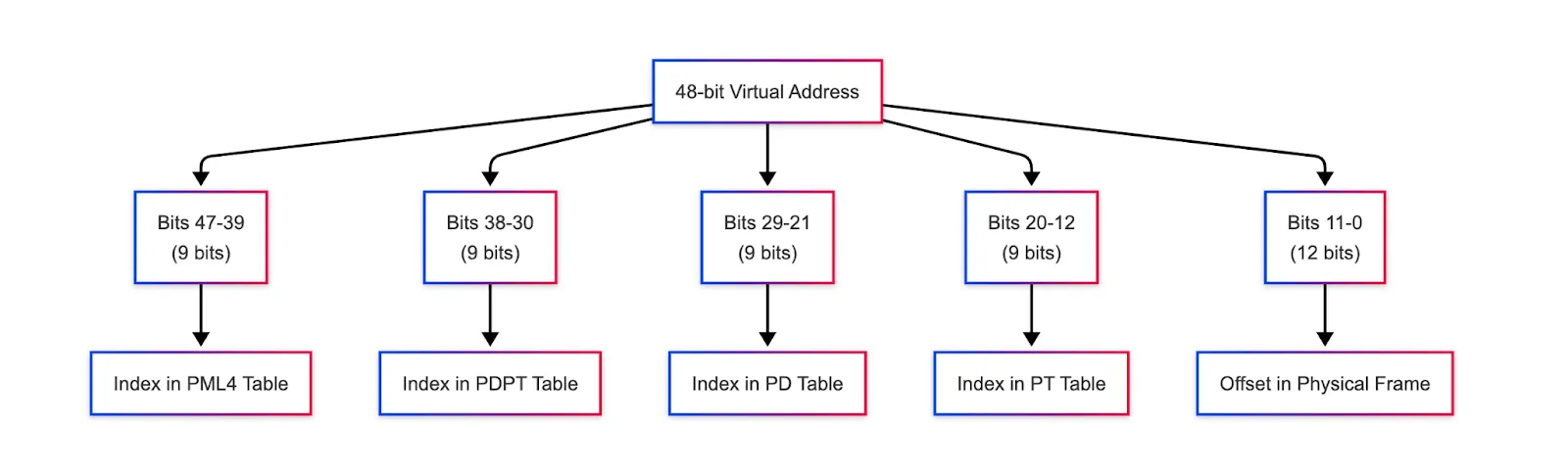
- As shown in the diagram below, the 48-bit virtual address is also divided into 5 parts that act as indexes into this layered data structure:
9 bits for each of the four levels (total = 9 * 4 = 36 bits)
Each level in the page table uses 9 bits of the virtual address to index into its table.
Since 9 bits can represent 2⁹ = 512 values, each table behaves like an array that contains 512 entries.
Final 12 bits for the page offset within the 4 KB page (2¹² = 4096 addresses in each page).
Page Walk
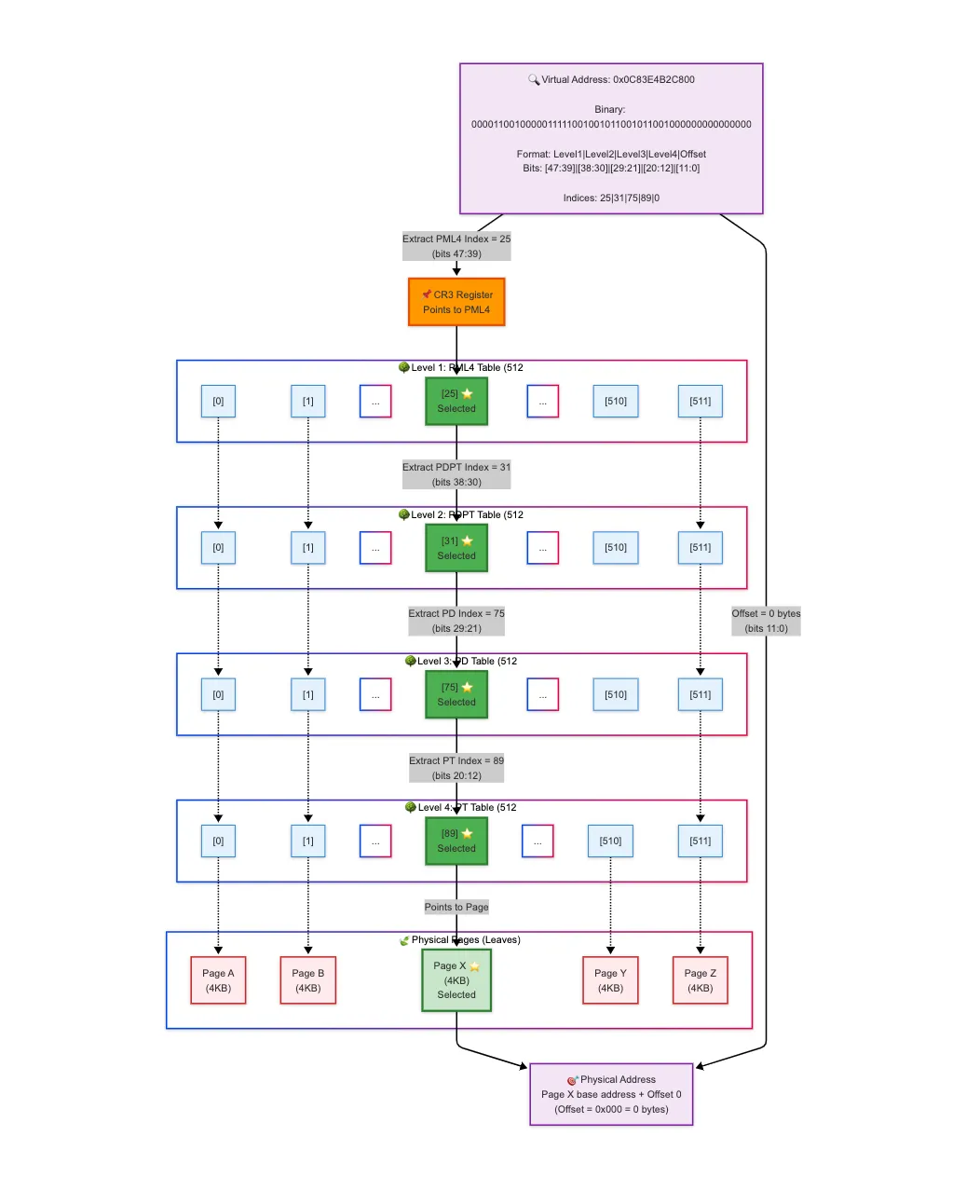
As shown in the diagram above, each 9-bit segment indexes into a table at that level. Starting from the PML4, the system walks through these tables until it reaches the actual physical frame. The 12-bit offset is then added to find the exact memory address within that 4 KB frame. This process is known as a page walk.
A full page walk may require 4 memory accesses just to translate the virtual address → one for each level of the page table hierarchy. After that, an additional memory access is needed to actually fetch the data from the physical frame. So in total, the cost may be up to 5 DRAM accesses per memory operation, which makes it expensive. To speed this up, CPUs use a special cache called the Translation Lookaside Buffer (TLB).
Translation Lookaside Buffer (TLB)
The TLB is a small, ultra-fast cache located inside the CPU that stores recent virtual-to-physical address translations → essentially caching Page Table Entries (PTEs).
TLB hit → If the translation is found, the physical address is returned almost instantly, typically within 1–2 CPU cycles (~0.3 ns for a 3 GHz CPU).
TLB miss → If the translation is not found, the CPU must perform a page walk (explained above), traversing all levels of the page table. The TLB is small, usually a few hundred to a few thousand entries, so it can only cache some virtual-to-physical mappings. On a TLB miss, the CPU must still do a full page walk, causing up to 5 slow DRAM accesses. How can it be solved ? Through Page Walk Cache.
Page Walk Cache
To speed up the TLB misses, CPUs use a Page Walk Cache that stores recently accessed intermediate page table entries from all levels (PML4, PDPT, PD, and PT) of the page table hierarchy, reducing the time needed for page walks.
By caching these intermediate entries, the CPU avoids repeatedly fetching them from DRAM during page walks, significantly reducing the number of slow memory accesses and speeding up virtual address translation.
Virtual Memory Overcommitment: Swapping, Demand Paging, and Page Faults
As mentioned earlier, each process in the operating system gets its own massive virtual address space, up to 256 TB on x86–64 systems, even though actual physical memory may only be a few gigabytes. How is that possible? Through Demand Paging and Swapping.
Demand Paging
As mentioned earlier, the OS doesn’t load all of an application’s memory into physical memory upfront.
Initially, most virtual pages are marked as not present in their PTEs in RAM.
Pages are loaded into memory only when the application actually accesses them.
If the application never touches certain parts of memory, they never get loaded, saving DRAM and speeding up program startup.
Swapping
Even with demand paging, physical memory can fill up as more pages are accessed. To handle this, the OS uses swapping → moving inactive or less frequently used pages from DRAM to a reserved space on disk called the swap area.
Swapping frees up DRAM for new pages that are actively needed. While accessing swapped-out pages is slower because it involves disk I/O, this process enables the system to overcommit memory → giving an illusion of a much larger DRAM by juggling pages between faster DRAM and slower disk storage.
Memory Management Unit (MMU): The Orchestrator of Virtual Memory
So far, we’ve explored many virtual memory concepts → page walks, TLB look ups, demand paging etc., but who actually orchestrates all of this? Is it the CPU? Not really. While the CPU issues memory accesses, it doesn’t handle the address translation itself, as it’s expensive and doing so would waste valuable CPU cycles.
In fact, whenever the CPU needs to interact with something outside its core chipset, like memory or I/O devices, it relies on dedicated controllers. Just as the Memory Controller manages DRAM access, the Memory Management Unit (MMU) manages virtual-to-physical address translation.
Memory Management Unit (MMU)
The MMU is a dedicated hardware component that handles virtual-to-physical address translation. Every time the CPU performs a memory access using a virtual address, it invokes the MMU to translate that address before the data can be fetched from physical memory.
The MMU handles TLB lookups, performs page walks on TLB misses, etc. By offloading this logic, the MMU enables efficient virtual memory translation without burdening the CPU.
Now, the memory access requests made by the CPU originate from the applications running in user-mode. However, operations like demand paging, swapping etc. are handled by the OS’s kernel, which runs in kernel-mode. So, how does the system switch from user-mode to kernel-mode when a memory access requires the OS’s intervention? Through Page Faults.
Page Faults
As mentioned earlier, when the CPU tries to access a virtual memory page in user-mode, the MMU performs the translation from virtual to physical address. If the MMU finds that the page is not currently present in physical memory (either because it hasn’t been loaded yet or was swapped out), it triggers a Page Fault.
When a page fault happens, the CPU interrupts the running program and transfers control to the OS to handle the fault. The OS then:
Loads the required page from disk (if swapped out) or allocates a new page (if this is the first access).
Updates the page table to mark the page as present in DRAM.
Resumes the program, allowing it to access the page normally.
The End to End Journey Of A Memory Access
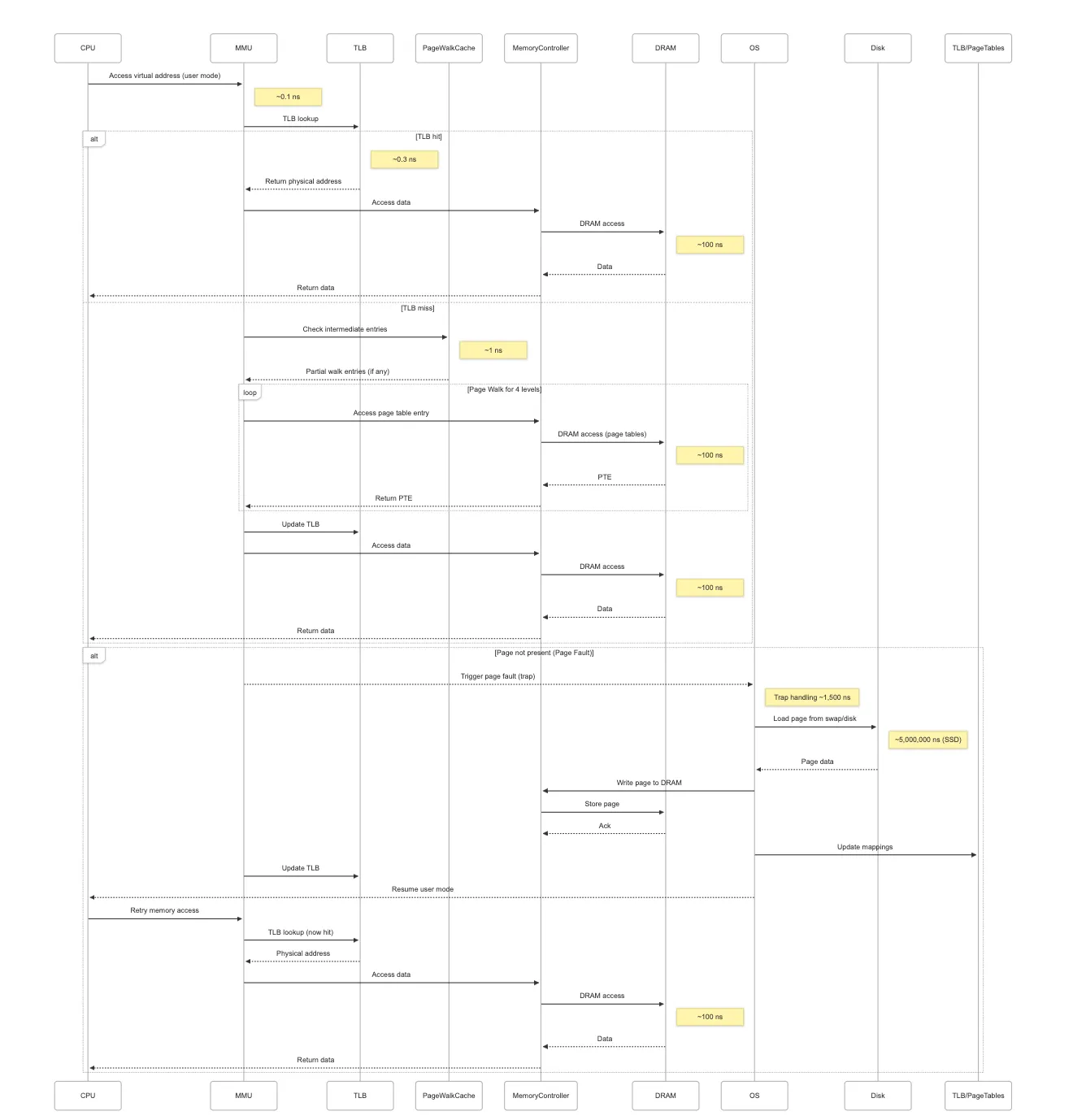
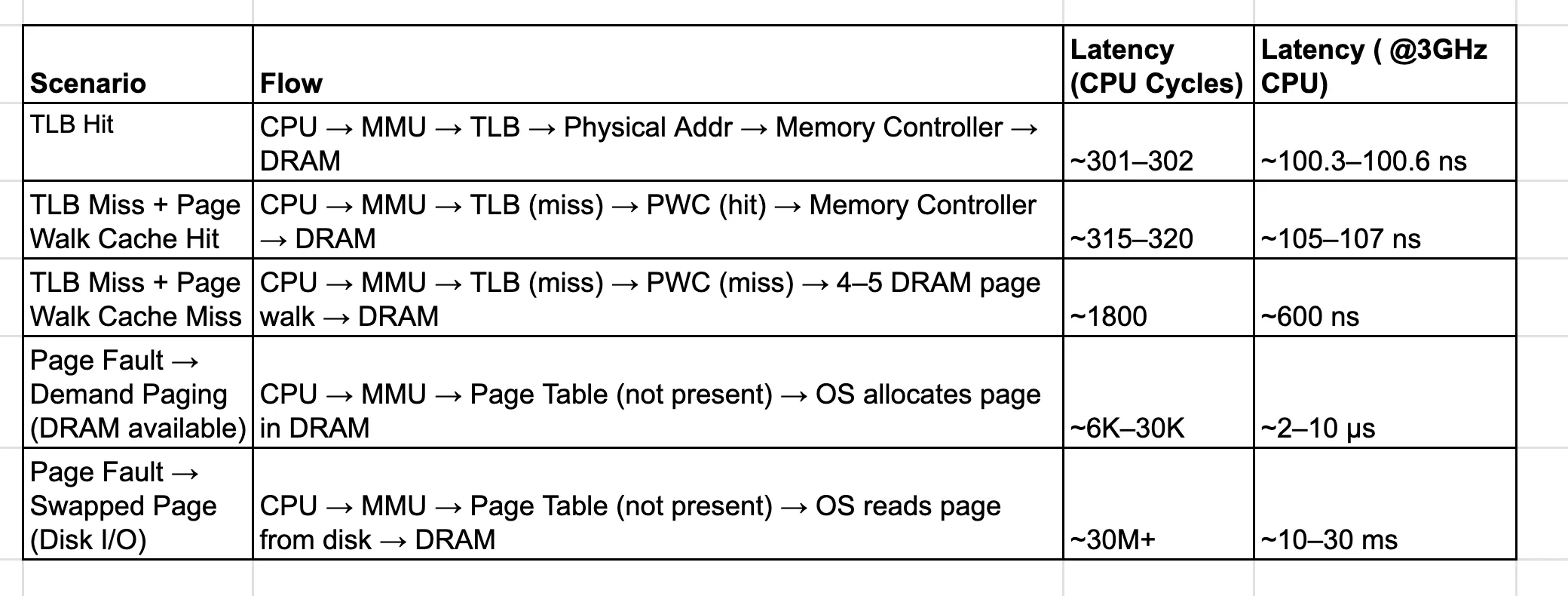
Memory Access Bottlenecks and Mitigations
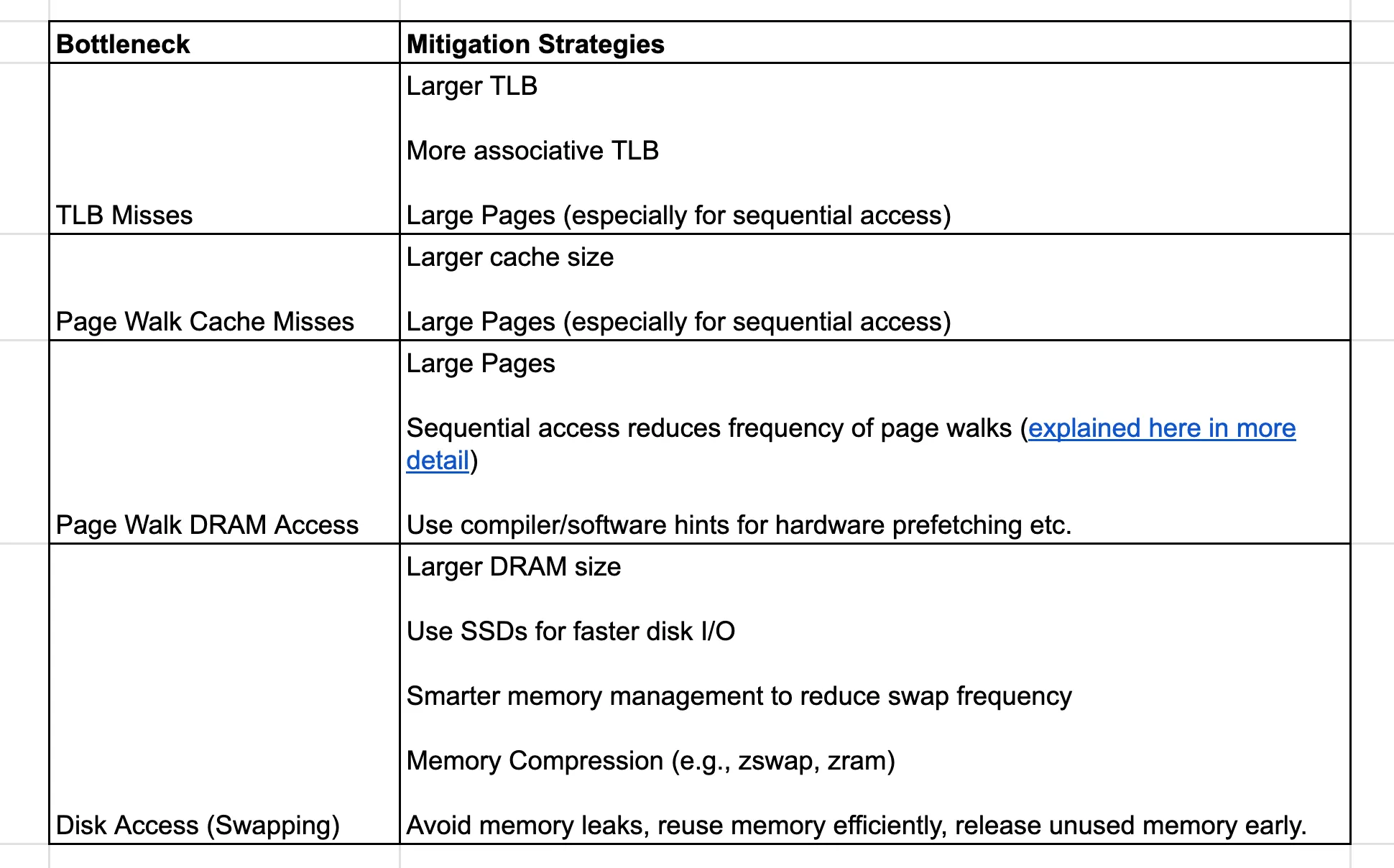
Each of the mitigation strategies mentioned above → large pages, higher TLB associativity, page walk optimizations, and smarter memory management → are deep, nuanced topics in their own right. They will be explored individually in separate sections or future articles.
If you have any feedback on the content, suggestions for improving the organization, or topics you’d like to see covered next, feel free to share → I’d love to hear your thoughts!
Subscribe to my newsletter
Read articles from Sachin Tolay directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sachin Tolay
Sachin Tolay
I am here to share everything I know about computer systems: from the internals of CPUs, memory, and storage engines to distributed systems, OS design, blockchain, AI etc. Deep dives, hands-on experiments, and clarity-first explanations.