Cache Coherence: How the MESI Protocol Keeps Multi-Core CPUs Consistent
 Sachin Tolay
Sachin TolayModern multi-core CPUs depend on caches to accelerate memory access and improve performance. However, when multiple cores cache the same memory address, maintaining a consistent view of memory across all cores and main memory (known as cache coherence) becomes a tricky problem.
One of the most widely used solutions to this challenge is the MESI cache coherence protocol. In this article, we’ll break down what cache coherence means, why it’s important, and how the MESI protocol ensures your multi-core CPU operates reliably and efficiently.
If you’re interested in diving deeper into how caches are organized and structured, I have written a separate article covering that in detail → Understanding CPU Cache Organization and Structure.
What Is Cache Coherence And Why Does It Matter?
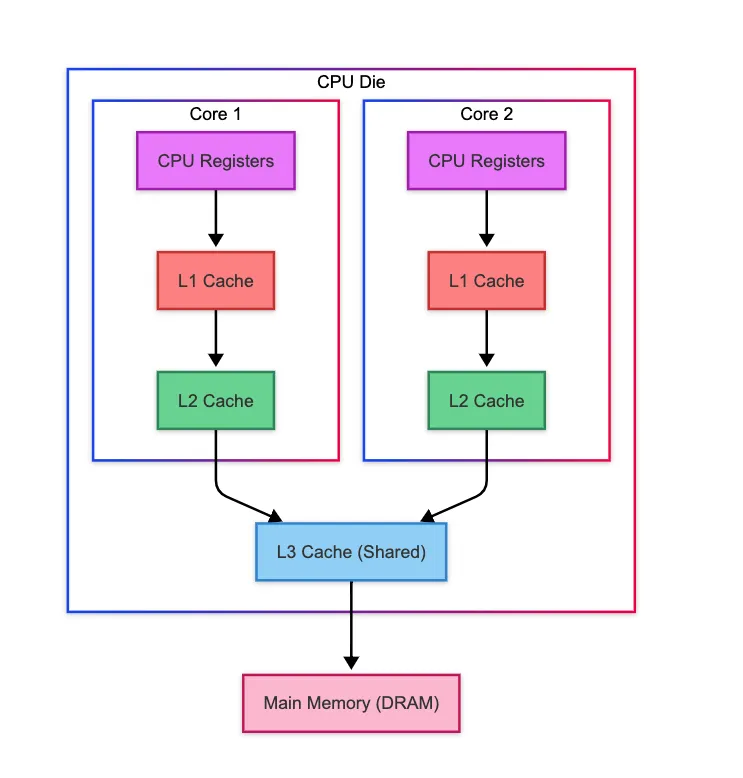
When multiple cores cache the same memory address, and one of them updates it, how do we make sure all other cores see the updated value? Example :-
Core 1 and Core 2 both cache the value at memory address X, which initially holds 10.
At this point, both cores have their own local copies of X (value: 10) in their private L1 caches.
Now, Core 1 updates X to 20 in its own L1 cache.
However, Core 2’s cache still holds the old value → 10.
Worse, main memory also still has the outdated value: 10.
Now, if Core 2 tries to read X, it will retrieve the outdated value (10) from its own cache, unaware that Core 1 has already updated it to 20. This kind of mismatch can lead to incorrect or unpredictable application behavior. This mismatch is what cache coherence aims to solve: Ensuring that all cores (and main memory) have a consistent and up-to-date view of memory.
How CPUs Handle Writes: Write-Through vs Write-Back
Before we talk about how cache coherence is maintained, it’s important to understand how caches handle writes, because that directly impacts why coherence is even needed.
Write-Through Caching
In this strategy, whenever a core writes to a cache line, the same update is immediately written to main memory as well. This keeps memory always up-to-date, making coherence simpler to maintain. But there’s a catch:
Every write results in a memory operation, which increases memory bandwidth usage.
It introduces latency, as writes must wait for memory.
And most importantly, it defeats the purpose of having fast, local caches → which is to reduce the need to access slower main memory in the first place.
Write-Back Caching (Used in Most CPUs Today)
In write-back caching, when a core updates a value:
The change is made only in the core’s private cache.
The updated value is not written to main memory immediately.
Instead, the new value stays in the cache and is written back only when the cache line is evicted or needs to be shared. And that’s exactly where cache coherence protocols like MESI are needed → to ensure all cores always see the correct, updated data.
MESI Protocol
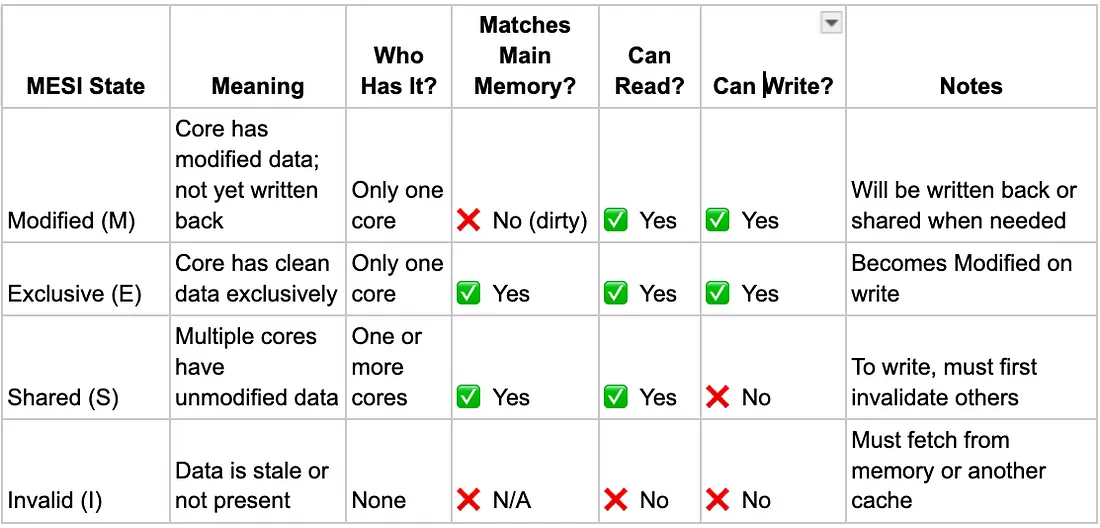
MESI stands for the four states each cache line can have → Modified (M), Exclusive (E), Shared (S) and Invalid (I). These states help the CPU know:
Which core has the most recent version of a piece of data,
Whether that version is the same as what’s in main memory,
What the CPU should do when a core tries to read or write that data.
Modified (M) → “I changed it, and no one else has it.”
If a CPU core has a cache line in the Modified state:
That core is the only one with the latest version of the data.
The data has been changed and no longer matches what’s in main memory.
If another core needs the data, the CPU can either:
Send the updated data directly to the other core (cache-to-cache transfer), or
Write it back to main memory if needed (e.g., on eviction).
Exclusive (E) → “I have the only clean copy.”
If a CPU core has a cache line in the Exclusive state:
That core is the only one with the latest version of the data.
The data matches the main memory → it has not been modified yet.
The core can:
Read the data freely.
Write to it directly, which promotes the cache line to the Modified state.
No other core has a copy, so there’s no need for invalidation.
Shared (S) → “Others may have it too, and it’s read-only.”
If a CPU core has a cache line in the Shared state:
One or more cores may have a copy of the latest version of the data in their caches; none have modified it.
The data in all those caches matches the main memory → it’s the latest clean version.
The core can:
Read the data freely.
Not write to it unless it first invalidates all other copies and gains exclusive access.
Invalid (I) → “My copy is stale or gone.”
If a CPU core has a cache line in the Invalid state:
- The cache line is not valid → the core cannot use it. It may have been :
Evicted due to limited cache space,
Invalidated by another core’s write,
Or never loaded at all.
- The core:
Cannot read or write to this data.
Must fetch a fresh copy from memory or another core’s cache to use it.
- Any access will cause a cache miss and trigger MESI protocol actions.
How Caches Communicate: Bus Snooping and Cache-to-Cache Transfer
Caches communicate in two key ways: Bus Snooping and Cache-to-Cache Transfers.
Bus Snooping: A Subscription Mechanism
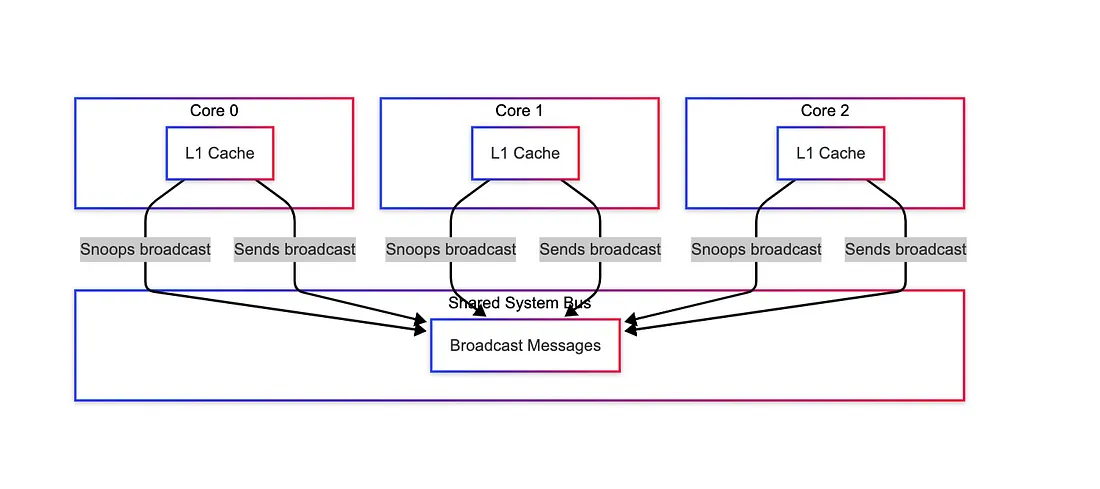
Bus snooping is a hardware technique where each core monitors the shared system bus to keep an eye on what other cores are doing with memory.
Every time a core reads or writes to a memory address, that action is broadcast on the system bus.
Other cores snoop (listen) to the bus.
If another core has a copy of the requested data, it can:
Respond with the most recent version (in Modified or Exclusive state).
Invalidate or update its own cached copy if needed.
Trigger a state change in its MESI cache line.
Cache-to-Cache Transfer: A Reply Mechanism
When a core issues a memory read request, and another core already has the most recent copy of the requested data in its cache, it can respond directly → this is called a cache-to-cache transfer.
Instead of fetching the data from main memory, the owning core:
Snoops the request via the bus,
Recognizes that it holds the latest copy, and
Sends the data directly to the requesting core.
This not only satisfies the request more quickly, but it also saves the latency of accessing main memory.
In this section, we just focused on how caches communicate over the system bus to stay coordinated. The specific actions caches take in various scenarios, will be covered in detail in the next section.
MESI State Transitions
We’ll break it down into five common scenarios that illustrate most of the transitions you’ll encounter. Lets assume, we have 3 cores → Core 1, Core 2 and Core 3.
First Read Scenario: Core 1 Reads a Line Not in Any Cache
Core 1 issues a memory read request (BusRd), which is broadcast on the system bus.
Core 2 and Core 3 snoop this request but do not have the line cached. Since no other cache has the line, none respond to the broadcast.
Core 1 then fetches the data from main memory in Exclusive (E) state, indicating this core is the sole owner.
State Transitions

Second Read Scenario: Core 2 Reads the Same Line
Core 2 issues a read request (BusRd) broadcast, which is broadcast on the system bus.
Core 1 snoops and sees it has the line in Exclusive (E).
Core 1 supplies the data directly to Core 2 via cache-to-cache transfer, saving a slower memory access.
Both Core 1 and Core 2 downgrade their cache lines to Shared (S).
Core 3 snoops but does not have the line, so doesn’t respond.
State Transitions

First Write Scenario: Core 1 Writes to the Shared Line
Core 1 issues a write intent request (BusUpgr) broadcast on the bus.
Core 2 and Core 3 snoop the broadcast:
Core 2 invalidates its Shared (S) copy → Invalid (I).
Core 3 does nothing (already Invalid).
Core 1 waits for invalidation acknowledgments.
Core 1 upgrades its cache line directly to Modified (M).
Core 1 now has exclusive write access; Core 2 and Core 3 have invalid copies.
State Transitions

Second Write Scenario: Core 3 Writes After Core 1’s Modified
Core 3 issues a read-for-ownership request (BusRdX) broadcast.
Core 1 snoops, sees it has the line Modified (M).
Core 1 supplies the updated data directly to Core 3 (cache-to-cache transfer).
Core 1 invalidates its Modified (M) copy → Invalid (I).
Core 3 caches the line as Modified (M) and performs the write.
Core 2 remains Invalid.
State Transitions

Concurrent Write Scenario: Core 1 and Core 2 Try to Write Simultaneously
Both Core 1 and Core 2 issue write intent requests (BusRdX) around the same time.
The bus orders the write intents, allowing only one core (say Core 1) to perform its MESI transition to Modified (M). Core 2 must wait for its turn or retry once the bus is available again.
Core 1 proceeds to upgrade its line to Modified (M).
Core 2’s request is delayed or retried after Core 1’s invalidations.
Other cores snoop and invalidate as needed.
Every action, such as a read or write request on the bus, is completed fully and indivisibly before another conflicting request starts. The bus serializes these requests, ensuring no two cores simultaneously hold conflicting states for the same cache line. This atomicity guarantees data consistency and correctness across all caches.
Limitations of MESI
While MESI effectively maintains cache coherence in many systems, it has some important limitations:
- False Sharing → MESI operates at the cache line granularity, not variable granularity. That means even if two threads access different variables, if those variables fall on the same cache line:
MESI treats them as shared data.
This causes unnecessary invalidations, even though no real data conflict exists.
- Scalability Issues → MESI relies on bus snooping, where all cores must snoop every memory transaction:
As the number of cores increases, the snooping traffic grows rapidly.
More cores mean more invalidations, more broadcasts, and more bus congestion.
Latency on Writes → To write to a cache line that’s shared, a core must broadcast a write intent, wait for other cores to invalidate their copies, then perform the write. This adds latency, especially when multiple cores frequently access the same data, or when contention is high.
No Built-in Support for Synchronization → MESI doesn’t handle higher-level synchronization (like locks or barriers). It only ensures data coherence, not program correctness.
If you have any feedback on the content, suggestions for improving the organization, or topics you’d like to see covered next, feel free to share → I’d love to hear your thoughts!
Subscribe to my newsletter
Read articles from Sachin Tolay directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sachin Tolay
Sachin Tolay
I am here to share everything I know about computer systems: from the internals of CPUs, memory, and storage engines to distributed systems, OS design, blockchain, AI etc. Deep dives, hands-on experiments, and clarity-first explanations.