Use the tiktoken package to tokenize text for OpenAI LLMs.
 Ramu Narasinga
Ramu NarasingaIn this article, you will learn how to use the tiktoken package to tokenize text for OpenAI LLMs. We will look at:
What is tiktoken?
tiktoken usage examples in Tiktokenizer app.
What is tiktoken?
If you need a programmatic interface for tokenizing text, check out tiktoken package for Python. For JavaScript, the community-supported @dbdq/tiktoken package works with most GPT models.
This @dbdq/tiktoken is officially recommended by the OpenAI and it is community supported.
tiktoken is a BPE tokeniser for use with OpenAI’s models, forked from the original tiktoken library to provide JS/WASM bindings for NodeJS and other JS runtimes.
This repository contains the following packages:
tiktoken(formally hosted at@dqbd/tiktoken): WASM bindings for the original Python library, providing full 1-to-1 feature parity.js-tiktoken: Pure JavaScript port of the original library with the core functionality, suitable for environments where WASM is not well supported or not desired (such as edge runtimes).
Documentation for js-tiktoken can be found in here. Documentation for the tiktoken can be found here.
Install
The WASM version of tiktoken can be installed from NPM:
npm install tiktoken
Usage
Basic usage follows, which includes all the OpenAI encoders and ranks:
import assert from "node:assert";
import { get_encoding, encoding_for_model } from "tiktoken";
const enc = get_encoding("gpt2");
assert(
new TextDecoder().decode(enc.decode(enc.encode("hello world"))) ===
"hello world"
);
// To get the tokeniser corresponding to a specific model in the OpenAI API:
const enc = encoding_for_model("text-davinci-003");
// Extend existing encoding with custom special tokens
const enc = encoding_for_model("gpt2", {
"<|im_start|>": 100264,
"<|im_end|>": 100265,
});
// don't forget to free the encoder after it is not used
enc.free();
Now that we understand what tiktoken is, lets look at some usage example in tiktokenizer app.
tiktoken usage examples in Tiktokenizer app.
In tiktokenizer/src/models/tokenizer.ts, at line 2, you will find the following code
import { get_encoding, encoding_for_model, type Tiktoken } from "tiktoken";
get_encoding
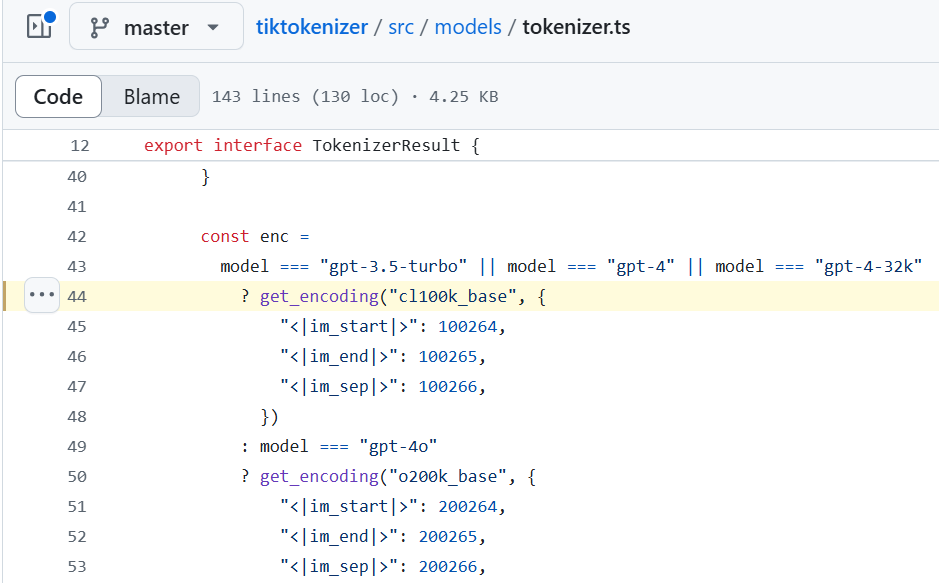
You will find the following code in tiktokenizer/src/models/tokenizer.ts at line 44.
const enc =
model === "gpt-3.5-turbo" || model === "gpt-4" || model === "gpt-4-32k"
? get_encoding("cl100k_base", {
"<|im_start|>": 100264,
"<|im_end|>": 100265,
"<|im_sep|>": 100266,
})
: model === "gpt-4o"
? get_encoding("o200k_base", {
"<|im_start|>": 200264,
"<|im_end|>": 200265,
"<|im_sep|>": 200266,
})
encoding_for_model
Below is an example invoking encoding_for_model function.
encoding_for_model(model);
You will find this above code in tiktokenizer/src/models/tokenizer.ts at line 56.
About me:
Hey, my name is Ramu Narasinga. I study codebase architecture in large open-source projects.
Email: ramu.narasinga@gmail.com
Want to learn from open-source code? Solve challenges inspired by open-source projects.
References:
Subscribe to my newsletter
Read articles from Ramu Narasinga directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Ramu Narasinga
Ramu Narasinga
I study large open-source projects and create content about their codebase architecture and best practices, sharing it through articles, videos.