Implementing a Concurrent Priority Queue in Rust
 Yashaswi Kumar Mishra
Yashaswi Kumar Mishra
Priority queues are fundamental to scheduling and coordination in systems, but making them thread-safe under real concurrent load is a nuanced challenge. Most implementations fall back on coarse locking, which works, but barely holds up under pressure. I wanted to explore a cleaner design in Rust that allows multiple threads to safely peek and pop without stepping on each other.
This writeup walks through the approach, the tradeoffs, and what it takes to keep things correct and efficient when threads start racing.
Let us start very dumb, by just defining a task struct and our queue would be nothing but a vector of tasks.
We implement debug and clone traits on Task.
#[derive(Debug, Clone)]
struct Task{
name : String,
priority : u32,
}
struct PriorityQueue{
tasks : Vec<Task>
}
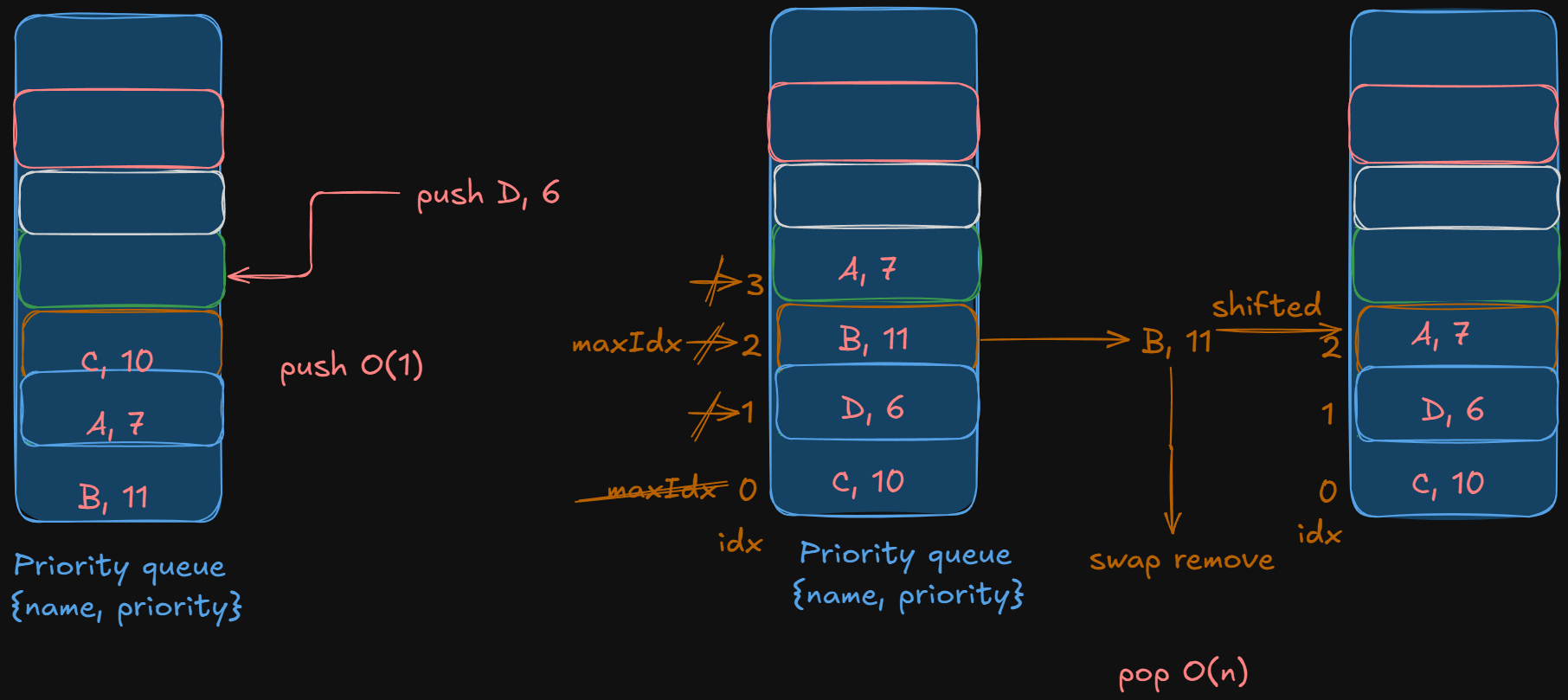
Let’s implement push. It just dumps a task to the end of queue. It’s O(1).
We will also write a very simple constructor, which initializes our tasks vector.
impl PriorityQueue{
fn new() -> Self{
Self { tasks: Vec::new() }
}
fn push(&mut self, task : Task){
self.tasks.push(task);
}
}
Let’s write the code for pop now.
fn pop(&mut self) -> Option<Task>{
if self.tasks.is_empty(){
return None;
}
let mut max_idx = 0;
for i in 1..self.tasks.len(){
if self.tasks[i].priority > self.tasks[max_idx].priority {
max_idx = i;
}
}
// swap_remove is O(1), just swaps with last and pops
Some(self.tasks.swap_remove(max_idx))
}
We do a linear scan of our tasks vector to find the task with the highest priority. swap_remove deletes it without shifting the rest (fast delete). This pop implementation takes O(n).
Is this design apt for concurrency? Let’s see
Say we have
let queue = PriorityQueue::new();
let shared = Arc::new(queue);
Let’s spawn two threads.
let q1 = Arc::clone(&shared);
let q2 = Arc::clone(&shared);
thread::spawn(move ||{
q1.push(Task { name: "A".into(), priority: 10 });
});
thread::spawn(move || {
q2.push(Task { name: "B".into(), priority: 5 });
});
The compiler throws this error into our face.
cannot borrow data in an
Arcas mutable traitDerefMutis required to modify through a dereference, but it is not implemented forstd::sync::Arc<T>
We’re trying to mutate shared data, but Arc<T> doesn’t give us mutable access. That’s where it bites.
Arc<T> is an atomic reference-counted pointer. Multiple threads can safely share it. Now, multiple threads own the same queue.
But, Arc only gives immutable references by default.
We’re trying to mutate data inside an Arc and that’s not allowed. Rust’s ownership model is very strict about holding multiple mutable refs to the same data. And it is good, as no two things should be able to mutate the same data at the same time. It causes race conditions, and is very bad for business logic.
What can we do then?
We can just wrap our queue in Mutex, which will allow thread-safe exclusive access to the queue. At one time only one thread can access the queue. We can go something like this.
let shared = Arc::new(Mutex::new(PriorityQueue::new()));
let handles: Vec<_> = (0..5).map(|i| {
let queue = Arc::clone(&shared);
thread::spawn(move || {
let task = Task { name: format!("T{i}").into(), priority: i };
let mut q = queue.lock().unwrap();
q.push(task);
})
}).collect();
for handle in handles {
handle.join().unwrap();
}
let final_q = shared.lock().unwrap();
println!("Final queue: {:?}", final_q.tasks);
But even Mutexhere is meh. Every thread waits to acquire the lock, even if they just wanna peek. More threads = more time fighting for the lock, especially in multi-core systems and this defeats the point of concurrency in the first place.
Doesn’t matter if you want to push, pop, or just check the top , you have to wait for your turn, for the lock to be released and deadlocks are real.
Our priority queue does work, but this is a very underwhelming design.
Our pop is O(n). Every pop is a full scan through the list.
We don’t have
peek, so we can’t inspect highest-priority taskThere is no thread safety. So this pq can’t be used in multithreaded context yet.
Push doesn’t maintain the priority order, so we can’t optimize reads or implement
peek.
Let’s start improving it a bit.
What we can do is make push O(n) and pop O(1), if we want to read data more frequently.
fn push(&mut self, task: Task) {
// Insert in correct position (sorted by priority ascending)
let pos = self.tasks.binary_search_by(|t| t.priority.cmp(&task.priority))
.unwrap_or_else(|e| e);
self.tasks.insert(pos, task);
}
fn pop(&mut self) -> Option<Task> {
self.tasks.pop() // O(1), max priority is always last
}
We're doing a binary search to find where to insert the new task, based on its priority. This keeps the vector sorted in ascending order of priority
That means the last element is always the highest priority which is great for pop. The binary_search_by call is O(log n) – classic binary search.
Still it feels like O(n) because of :
.unwrap_or_else(|e| e) Which is sort of a hack to extract the index e where the element would be inserted if it’s not found.
And inside binary_search_by, this return value is managed via a loop or branching logic that sometimes leads to linear-time fallback, especially if you mess up the ordering predicate.
But this only seems worse because of the verbose syntax and error-case code paths.
And the insertion via Vec::insert() is O(n) because it has to shift elements.
So the total cost is still O(log n) + O(n). But in practice, due to cache misses, branching, and verbose control flow, it performs worse than you'd expect for small structures.
binary_search_by= O(log n) to find the positionunwrap_or_else(|e| e)= extract insert index if not foundVec::insert()= O(n) because it has to shift elements
Let’s improve the push and use partition_point()
It finds the first index where the predicate breaks (t.priority ≤ task.priority).
So it walks through all the lower-or-equal priorities and returns the index where the new one should be inserted.
Since the vector is sorted, this is a binary search under the hood → O(log n).
Then, we call
Vec::insert(pos, task)→ shifts elements → O(n).
Now our push is :
fn push(&mut self, task: Task) {
// Maintain ascending order (lowest first, highest last)
let idx = self.tasks.partition_point(|t| t.priority <= task.priority);
self.tasks.insert(idx, task);
}
It avoids branching based on search results, better for CPU branch prediction and cache locality.
binary_search_by gives you a Result, which you must handle (found vs not-found). It is more verbose and can lead to unwrap_or_else(|e| e) boilerplate.
partition_point() is semantically cleaner.

Now we can write peek() as well since our vector is ordered.
fn peek(&self) -> Option<&Task>{
self.tasks.last()
}
We could have used a BinaryHeap , which would give us O(log n) push and O(log n) pop.
But we are building for real-world workloads, where reads dominate writes.
Naturally, the next question is “How do we make this concurrent?”
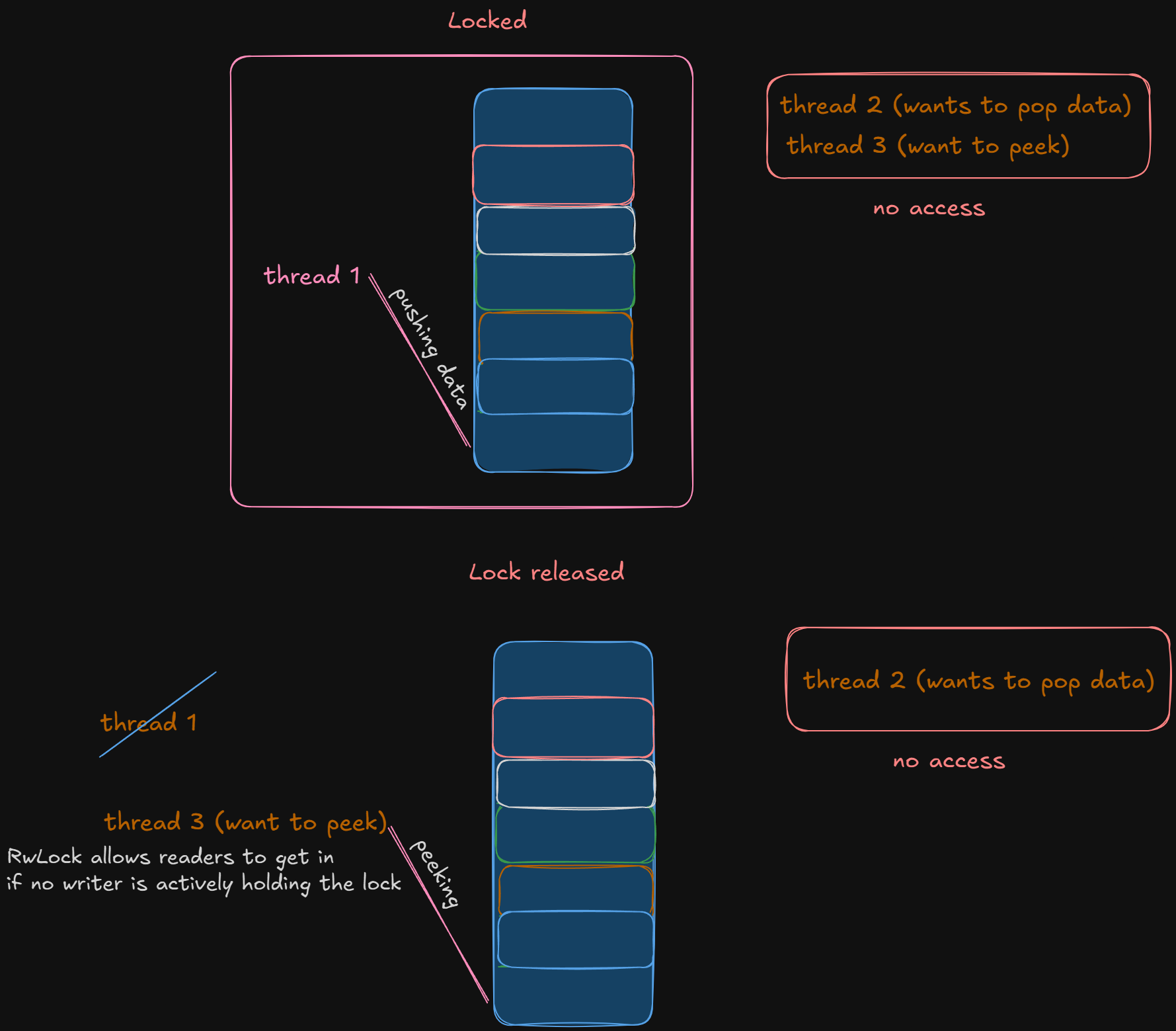
Let us use RwLock because we want concurrent reads but exclusive writes.
This maps perfectly to how a Priority Queue would works in high-concurrency setups. We allow multiple readers at once, but only one writer at a time, and no readers allowed during write. That is what RwLock .
We already saw why we will not be using Mutex earlier. Mutex is a brutal overkill especially if your workload is read-heavy, like queues that mostly peek() or pop() tasks in a worker loop.
We will also write trivial read functions like len() andis_empty() later.
Our PriorityQueue has 3 kinds of operations:
| Operation | Type | Thread Safety Needs |
push() | write | must block all readers & writers |
pop() | write | same, modifies vector |
peek() / len() / is_empty() | read | can happen in parallel with other reads |
Let us wrap our initial PriorityQueue struct in Arc<RwLock<_>>
#[derive(Clone)]
struct SharedQueue{
inner : Arc<RwLock<PriorityQueue>>
}
That’s it. Now we will just implthis SharedQueue struct, and just write the functions and provide read/write locks.
impl SharedQueue {
fn new() -> Self {
Self {
inner: Arc::new(RwLock::new(PriorityQueue::new())),
}
}
fn push(&self, task: Task) {
let mut q = self.inner.write().unwrap(); // exclusive write lock
q.push(task);
}
fn pop(&self) -> Option<Task> {
let mut q = self.inner.write().unwrap(); // still a write
q.pop()
}
fn peek(&self) -> Option<Task> {
let q = self.inner.read().unwrap(); // shared read lock
q.peek().cloned()
}
fn len(&self) -> usize {
self.inner.read().unwrap().tasks.len()
}
fn is_empty(&self) -> bool {
self.len() == 0
}
}
peek(),len(),is_empty()= read locks onlypush(),pop()= write locks
This seems fine. Let us test this by
Spawning 5 writer threads to push 10 elements each in the queue.
Some reader threads to peek.
And 2 threads to pop 15 elements each.
We should have 20 elements left at the end.
This is how we spawn these threads.
let queue = SharedQueue::new();
let mut handles = vec![];
// Spawn 5 writer threads
for i in 0..5 {
let q = queue.clone();
handles.push(thread::spawn(move || {
for j in 0..10 {
let task = Task {
name: format!("T{i}_{j}"),
priority: i * 10 + j,
};
q.push(task);
println!("[Writer-{i}] Pushed T{i}_{j}");
}
}));
}
// Spawn 3 reader threads (peek only)
for i in 0..3 {
let q = queue.clone();
handles.push(thread::spawn(move || {
for _ in 0..15 {
if let Some(top) = q.peek() {
println!("[Reader-{i}] Peeked: {:?}", top);
} else {
println!("[Reader-{i}] Queue is empty");
}
std::thread::sleep(std::time::Duration::from_millis(20));
}
}));
}
// Spawn 2 consumer threads (pop)
for i in 0..2 {
let q = queue.clone();
handles.push(thread::spawn(move || {
for _ in 0..15 {
if let Some(task) = q.pop() {
println!("[Popper-{i}] Popped: {:?}", task);
} else {
println!("[Popper-{i}] Nothing to pop");
}
std::thread::sleep(std::time::Duration::from_millis(30));
}
}));
}
for h in handles {
h.join().unwrap();
}
println!("\nFinal Length: {}", queue.len());
println!("Final Queue: {:?}", queue.inner.read().unwrap().tasks);
We .join() all threads to ensure the main thread waits for all worker threads to complete before printing the final state.
When we run the code, this is what we see.

On running the program, the output confirms our expectations:
The 30 highest-priority elements (IDs 20–49) were successfully popped by the threads.
The remaining 20 elements (IDs 0–19) are intact in the heap.
All
peek()logs accurately reflect the highest-priority item at various stages of concurrent access.
This validates that our concurrent-safe priority queue handles simultaneous pop() and peek() operations correctly, maintaining both thread safety and priority ordering under concurrent pressure.
We now have a concurrent priority queue that’s:
Thread-safe
Optimized for read-heavy loads
Easy to extend (timeouts, TTL, etc.)
Cleanly abstracted behind
SharedQueue
We avoided Mutex contention by using RwLock, and ensured O(n) push (sorted) with O(1) pop for fast consumer reads.
This design shines when:
You have multiple reader threads (workers, peeking schedulers, monitors)
You have predictable and fair task priorities
You want to avoid performance cliffs in
BinaryHeapunder concurrent access
For high-write workloads or better amortized performance, one might consider:
BinaryHeap + Mutex(less read-friendly)Lock-free data structures
Priority queues in
crossbeamorflumewith built-in channels
But this version is perfect for many backend schedulers, job dispatchers, and priority task managers in real-world multithreaded systems.
Thanks for reading. Catch you in the next one!
Subscribe to my newsletter
Read articles from Yashaswi Kumar Mishra directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by