Context Kills VRAM: How to Run LLMs on consumer GPUs
 Lyx
Lyx
TL;DR “You can run big models or long prompts on a consumer GPU (8–16 GB VRAM) — but rarely both.”
1. Introduction
Running large language models (LLMs) locally has never been easier — but doing it on a consumer GPU (8–16 GB VRAM) still comes with some surprises. Everything works fine… until it doesn’t.
What’s behind those sudden slowdowns? Why does context length chew through memory? And what exactly happens when a model “spills” to your CPU?
This guide breaks it all down.
We’ll show you how GPU memory (VRAM) gets used during inference, how to predict usage, and how to avoid common traps — understanding tricks like quantization, layer placement**,** and attention optimizations to stay fast and on-device.
2. Why VRAM Is the Bottleneck
2.1 The 8–16 GB Ceiling
Consumer GPUs like the RTX 30xx, 40xx, and 50xx have enough compute to run modern large language models. But their real constraint is VRAM.
Once a model or its KV cache (mostly driven by the context buffer — which itself is the part of the model that stores all previously seen text tokens from the prompt and the model response) no longer fits entirely in GPU memory, it spills to CPU RAM, triggering a sharp slowdown: performance can drop from 50–100 tokens/sec to just 2–5 tokens/sec.
Frameworks like Ollama support a hybrid mode, where model layers are split between GPU and CPU. This effectively increases your available memory — making it possible to load models that wouldn’t fit on GPU alone. At first glance, this sounds like a perfect fix for memory-limited consumer PCs. But hybrid GPU+CPU mode comes with a hidden cost: PCIe latency. Each token’s activations must cross the bus twice, and that transfer overhead can completely wipe out any speed gains from using the GPU.
We tested this with qwen3:14b, sweeping from 0% to 100% GPU layer usage. The results (Benchmarked on RTX 3060; your numbers may differ) show a clear pattern:
At 0% GPU (pure CPU): ~4.6 tokens/sec — decent for pure CPU, but far from ideal.
At low GPU usage, performance actually drops — hitting a low of ~2.6 tokens/sec. Here, PCIe transfer cost dominates, and the GPU isn’t doing enough to make up for it.
Around two-thirds GPU usage, performance recovers — matching CPU-only speed. This is the tipping point where GPU acceleration starts to outweigh transfer penalties.
At 100% GPU, speed climbs to 32 tokens/sec — a 7× gain over CPU-only, and finally the performance we’re after.
You can see this U-shaped performance curve below. The low point represents where hybrid mode is actively as it's worst, worse than CPU-only:
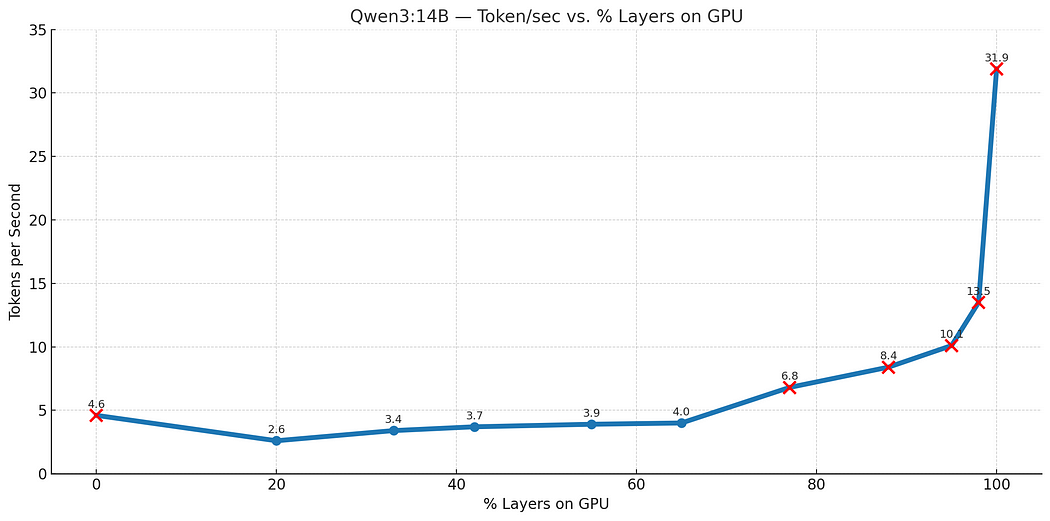
Figure: Performance (Token/sec ) vs GPU Layer Share (Qwen3:14B)
Therefore, on consumer GPUs, hybrid mode isn’t always faster. Until you offload enough layers, PCIe latency can erase the GPU’s advantage.
However, this tipping point shifts with model size. In our benchmark tests with a larger model like qwen3:32b, hybrid mode starts to help much earlier — even at around 30% GPU usage. The same U-shaped performance curve still applies, but the turning point shifts earlier. Larger models have heavier layers, so each GPU-offloaded layer gives more gain per transfer, making hybrid worthwhile sooner.
Even when it’s slower, hybrid mode has one big advantage left: It unlocks more total memory by combining CPU RAM and GPU VRAM. That alone can be the difference between running a model or not.
Upcoming technologies like PCIe 5.0, NVLink, and shared HBM memory will likely lower the hybrid tipping point — making it both fast and flexible on future consumer hardware.
🛠️ Note: In Ollama, num_gpu controls how many layers are assigned to the GPU — not how many GPUs are used. (Yes, it’s confusing.)
💡 Tip: Use tools like ollama ps and nvidia-smi to monitor usage. If GPU utilization dips while VRAM is maxed, you're probably spilling.
2.2 Model Size vs. Context Length
Two components dominate memory usage during inference:
Model weights — the actual model, fixed, usually quantized, always present
KV Cache — grows linearly with context length (prompt + generated tokens)
A 14B model (using Q4_K_M) might squeeze into 12 GB VRAM — but you might only manage ~4K tokens of context. In contrast, a 2–3B model can handle 100K+ tokens, though it might lack the reasoning ability of larger models.
💡 In short: You can run a big model or a long context — but rarely both.
Some small models don’t benefit from long contexts if they weren’t trained on them. The effective context limit is the lower of training data and model configuration.
2.3 Why Quantization Matters
To make large models fit on smaller GPUs, weights are often quantized — reducing precision from 16-bit floating point (FP16) to lower bit-width integers like 8-bit or 4-bit. This can shrink model size by 50–75%, with only small impact on performance.
One of the most effective formats today is Q4_K_M, which reduces weight storage to ~0.57 bytes per parameter — about 1/4 the size of FP16, while maintaining excellent perplexity across popular models.
Lower-bit formats are also emerging. For example: Microsoft’s BitNet explores 1-bit transformers, potentially pushing size and efficiency even further for future LLMs.
Note: Quantization originally applied only to model weights. But recent advances in Ollama and llama.cpp now extend it to the KV cache as well — storing keys and values in lower-precision formats. This can reduce memory use from context, though the impact on perplexity and generation quality is still being fully tested.
3. Where the Memory Goes
3.1 Formula Overview
At a high level, VRAM usage during inference can be summarized as:
VRAM = Constant + Linear(N)
This breaks down into:
A fixed cost — model weights + small system overhead
A context-dependent cost — the KV cache, which grows linearly with the number of tokens (
N)
A more precise formula is:
VRAM(N) [GB] = (P × b_w + 0.55 + 0.08 × P) + N × (2 × L × d/g × b_kv / 1024³)
Where the constants are derived empirically (using llama.cpp backend):
CUDA/system overhead ˜0.55 GB
Parameter scratchpad ˜0.08 × P GB
where we use these symbols and their description:
P:Parameters in billions (e.g., 7 for a 7B model)b_w:Bytes per weight (e.g., Q4_K_M ˜ 0.57)L:Number of transformer layersd:Hidden dimension sizeg:GQA grouping factor (query heads ÷ KV heads)b_kv:Bytes per KV scalar (usually 2 for FP16)N:Context length (in tokens)
3.2 The Constant Cost: Model & Overhead
The fixed VRAM load is consumed by:
Quantized model weights:
P × b_wCUDA/system overhead: cuBLAS buffers, workspace (˜ 0.55 GB)
Scratchpad activations: temporary tensors (˜ 0.08 × P GB)
Example : Qwen 2.5 7B, Q4_K_M
Component Estimated Usage
------------- ----------------------
Weights: 7.61 × 0.57 ˜ 4.34 GB
CUDA Overhead: ˜0.55 GB
Scratchpad: 7.61 × 0.08 ˜ 0.61 GB
Total: ~5.50 GB
Measured: ~5.33 GB
📊 The estimate aligns closely with real-world usage — the constant part is easy to predict and consistent across environments.
3.3 The Growing Cost: KV Cache
**What Is the KV Cache?
**Each time the model generates a new token, it must reference all previous tokens for attention. To avoid recomputation, it caches the Key and Value vectors — known as the KVCache.
This cache grows linearly with context length (N). At large contexts, it becomes the primary source of memory pressure, often dwarfing the model weights themselves.
Formula:
KVCache(N) [GB] = N × 2 × L × d/g × b_kv / 1024³
For Qwen 2.5 7B:L = 32, d = 3584, g = 4, b_kv = 2 (bytes per scalar in FP16)
This results in a KV memory cost of ~0.109 MiB/token.
📊 In practice, using Ollama, we measured 0.110 MiB/token — nearly a perfect match.
4. How Models Reduce KV Growth
Since the KVCache grows linearly with context length, modern LLMs use several architectural techniques to reduce its memory footprint — a critical factor for running long-context inference on consumer GPUs.
Multi-Head Attention (MHA) is the standard mechanism used in earlier transformers. It computes separate key-value pairs for each attention head, which leads to larger KVCache usage. While MHA enables richer representations, its memory cost scales significantly with both model size and context length.
Grouped Query Attention (GQA) improves efficiency by allowing multiple query heads to share a single set of key-value projections. This reduces the total number of KV tensors and significantly lowers memory usage. GQA is widely adopted in modern models like LLaMA-2/3, Mistral, and Qwen, and is a key reason these models support longer contexts within the constraints of consumer-grade VRAM.
Sliding Window Attention (SWA) reduces KVCache growth by restricting most layers to attend only to the most recent tokens, within a fixed-size window. Only a few layers retain full global attention, helping to bound memory usage while preserving long-range reasoning. This design is implemented, for example, in Mistral (˜1/6 of layers use global attention, with a window size of 4096 tokens) and Gemma 3 (1 global + 5 local layers, 1024-token window).
Latent Compression (MLA) is used by DeepSeek-R1 (the 671B-parameter model). Unlike its smaller sibling models (e.g. DeepSeek-R1 7B/14B ), which use Qwen-style GQA, DeepSeek-R1 (full) employs Multi-Latent Attention (MLA) to aggressively compress its KVCache. It does this by projecting the original key and value tensors into a smaller latent space, effectively reducing the dimensionality from
dto a much smallerk, wherek ≪ d(e.g.,k = 128in DeepSeek-R1, compared tod ≈ 16384). This significantly lowers memory usage — down to just ~7% of the original — without sacrificing long-range reasoning. The result is support for large context lengths while keeping VRAM usage surprisingly manageable — a standout architectural decision at this scale.
5. Real-World VRAM Tests
To evaluate how model architecture affects memory usage, we conducted a series of real-world VRAM measurements using Ollama with the llama.cpp backend. Our tests focus on open-source LLMs across various sizes — under practical, consumer-level GPU constraints. In the appendix below we list the test system used.
5.1 Constant VRAM (Context = 0)
This test measures baseline VRAM usage when the context length is set to zero — meaning just the model is loaded. Memory use reflects only the core model components: quantized weights, CUDA/system overhead, and temporary scratchpad activations used by the inference backend.
Understanding this baseline is crucial because it tells you how much VRAM is left for context tokens. If your model already occupies most of the available VRAM at zero context, there’s very little room left for prompt and response tokens before spilling to CPU.
The bar chart below compares predicted VRAM usage (based on our formula) with measured values:
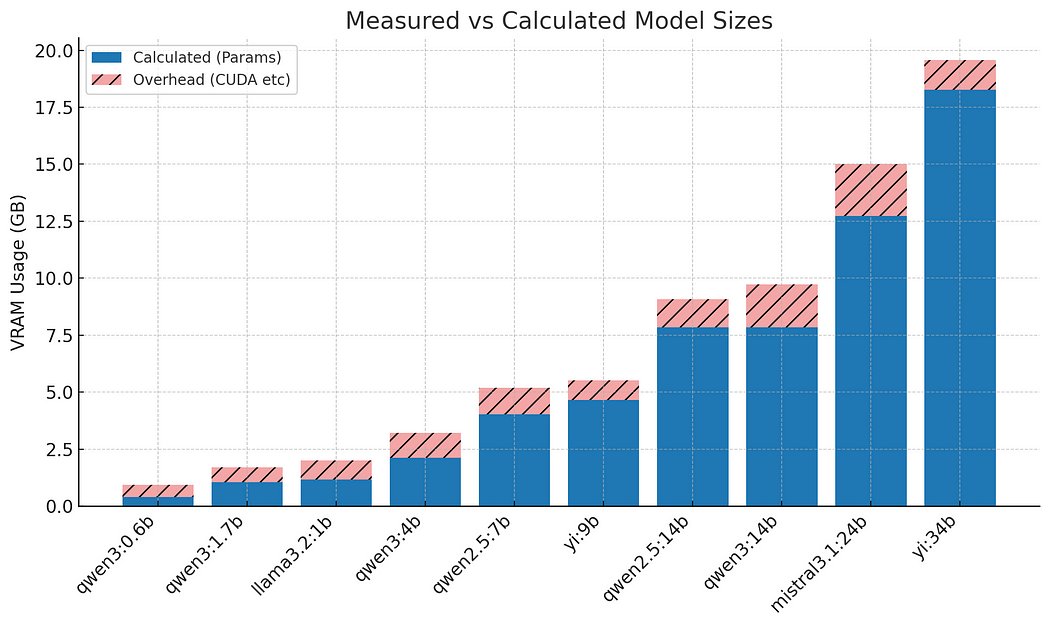
Figure: Model base memory usage (predicted vs measured)
We can see that most models fall within 200–300 MiB of the predicted value. This confirms that our estimation formula is reliable for planning purposes. The consistency also means you can confidently estimate base memory usage before ever running the model, just from its size and quantization format.
🧠 Takeaway: Base VRAM usage is predictable and stable. Once you know your model’s fixed cost, you can estimate the maximum context length that will still fit in VRAM — before performance drops or context truncation occurs.
5.2 VRAM vs. Context Length
This test explores how VRAM usage scales as we increase the context length — which includes both the input prompt and the generated tokens. We tested a range of models (1.7B, 7B, 14B, and 34B parameters), each using a similar quantization format to isolate the effect of context size. Ollama reserves the whole context at startup so the measurements show memory as if the whole context would be used.
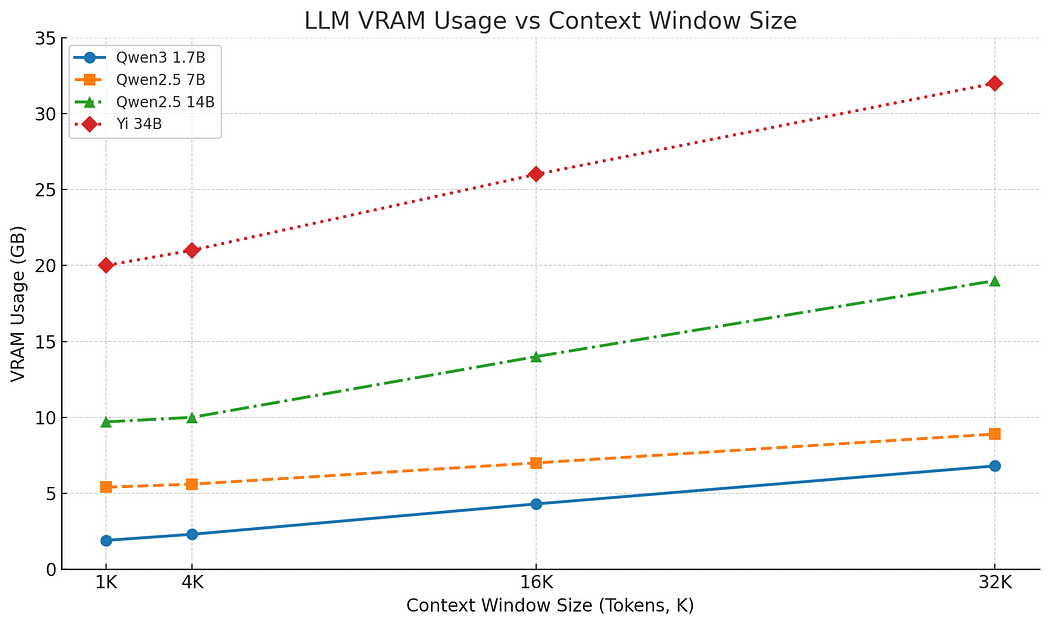
Figure: Linear relation VRAM vs context window
The results clearly show linear VRAM growth across model sizes. This confirms that the KVCache is the dominant variable memory cost during inference. As context length increases, the amount of memory required for storing key and value vectors rises proportionally — eventually becoming the limiting factor on how long your input/output can be before you hit your VRAM ceiling.
From the slope of each line, you can estimate the per-token memory cost for a given model — and project how many tokens your GPU can handle before performance degradation or CPU spill occurs.
Some models use non-linear context strategies like Sliding Window Attention (SWA), which would appear as a flattening curve in this type of plot. But the models we tested all exhibit linear growth.
⚠️ Note: By default, Ollama (in early 2025) limits context length to 4096 tokens — even for models that support more. To use different (also longer!) contexts, you’ll need to explicitly set it (num_ctx).
💡 Takeaway: VRAM usage grows linearly with context, not model size. Use this to your advantage: Measure VRAM at two different context lengths and extrapolate to find the max context your GPU can hold before spilling
This gives you a quick, practical method to tune prompt length and model size to stay within your GPU’s limits — without trial and error.
5.3 Attention Mechanisms: MHA vs. GQA
To demonstrate the impact of attention type on memory use, we include a figure from Zhang et al. (2024) [1] comparing KVCache VRAM usage between Multi-Head Attention (MHA) and Grouped Query Attention (GQA) for 7B and 13B models.
![Multi-Head Attention (MHA) vs Grouped Query Attention, redrawn from [1]](https://miro.medium.com/v2/resize:fit:1050/1*n68r95tgmhMSkNzL3ybpUQ.png)
Figure: Multi-Head Attention (MHA) vs Grouped Query Attention, redrawn from [1]
Both attention styles, Multi-Head Attention (MHA) and Grouped Query Attention (GQA), demonstrate linear VRAM growth with increasing context length. However, GQA consistently uses less memory. This improved efficiency stems from GQA’s design, which shares key-value projections across query heads, thereby reducing the number of key-value tensors that need to be stored per layer. As a result, GQA significantly enhances memory scalability, making it possible to handle longer contexts within the same fixed amount of VRAM.
5.4 Speed Drop from CPU Spill
One of the most significant performance bottlenecks when running LLMs locally is VRAM overflow — when the combined size of the model weights and KVCache exceeds GPU memory. In this scenario, parts of the inference process are offloaded to CPU RAM, introducing massive slowdowns due to the slower CPU and the much lower bandwidth and higher latency of PCIe transfers.
To measure this effect, we tested throughput using a 4096-token context across various models on a 12 GB RTX 3060.
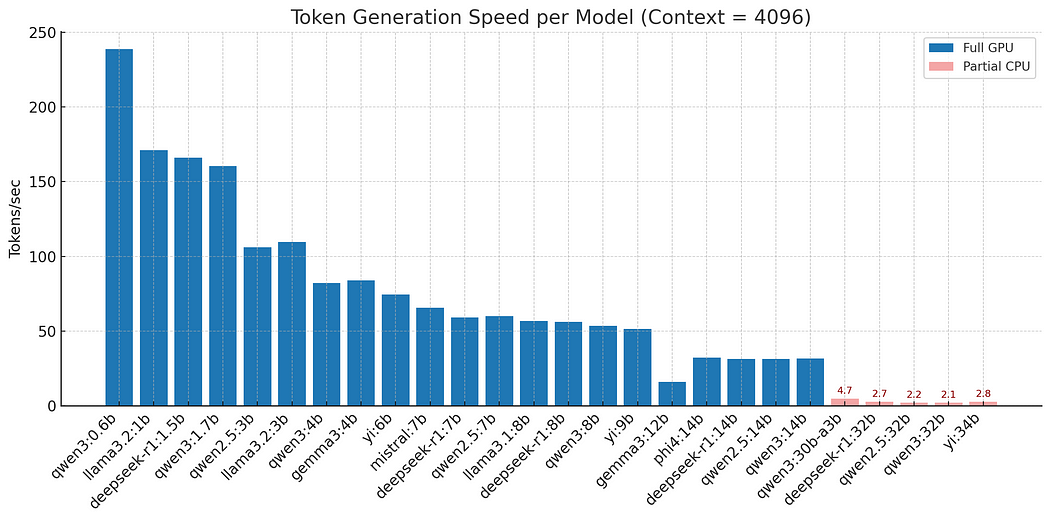
Figure: Tokens per second (blue = fits in VRAM, red = spills to CPU)
The performance tests reveal indeed a clear and dramatic trends in throughput degradation due to CPU memory spill. Models up to 14B parameters with our given context fit entirely within GPU memory and perform efficiently, generating at a rate of 30–150+ tokens per second. However, once you move to larger models like 32B, the available VRAM is no longer sufficient to hold both the model weights and KVCache. These larger models begin spilling into CPU memory, triggering a drop in performance.
In these spill scenarios, throughput can fall drastically — often by a factor of 5 to 15 — and in the worst cases in our test, drops as low as 2–5 tokens per second. (To be fair, these larger models are inherently slower even when fully in VRAM — but the spill still causes a major, measurable drop.) GPU utilization also takes a significant hit during these events, as visible in tools like nvidia-smi, where high VRAM usage is paired with idle or low GPU activity.
💡 Takeaway: Spilling to CPU is not a gradual slowdown — it’s a performance cliff**.** If you exceed your VRAM budget, inference speed can collapse. Always test your configuration and aim for a model + context combo that fits entirely within GPU memory. Use tools like nvidia-smi and ollama ps to spot early signs of spill (high VRAM, low GPU utilization).
6. Practical VRAM Planning
Here’s a practical guide to selecting and configuring models based on your available VRAM. Following this, several tips help ensure efficient VRAM usage and stable performance:
Pick a model that fits your VRAM.
Use quantized formats —
Q4_K_Mis a solid trade-off between size and accuracy.Estimate per-token KV cost from specs or by measuring the VRAM slope across two context lengths. Try to choose a context size where model + context fits entirely in VRAM.
Keep GPU utilization high — or move fully to CPU. Hybrid setups with too little on GPU can be slower than pure CPU.
Monitor live memory usage with
ollama psandnvidia-smi.For chat, keep batch size = 1; go higher only if you have spare VRAM.
The list below summarizes the typical context limits for different model sizes in quantized Q4_K_M format, making it easier to match model capacity with hardware constraints:
2–4B models
→ 64K–100K context tokens
→ Long memory, small model footprint
→ Works fine7–8B models
→ ~32K context tokens
→ Great fit for 12 GB GPUs13–14B models
→ 4K–8K context (up to ~20K with GQA)
→ Powerful, but tight VRAM limit30–34B models
→ won’t fit 12GB GPU in Q4_K_M→ bite the bullet and use CPU / CPU+GPU speed
For reference, you can see here an example of a real ollama ps output. You notice 50:50 CPU-GPU usage and 23GB memory size for qwen3:32b:
NAME ID SIZE PROCESSOR UNTIL
qwen3:32b e1c9f234c6eb 23 GB 50%/50% CPU/GPU 3 minutes from now
7. Conclusion
VRAM usage during inference is both predictable and manageable — if you know what to watch for.
The base model size is fixed.
The KV cache scales with context — and is the main hidden VRAM killer.
Spilling to CPU causes massive slowdowns due to CPU performance and PCIe bandwidth bottlenecks.
On a home GPU, smart tradeoffs are essential. You can absolutely run strong open-source LLMs — just remember:
⚠️ Pick either a big model or a long context — rarely both.
Modern techniques like GQA, Sliding Window Attention, and MLA help reduce KV memory demands. Quantization reduces base model size. But they don’t remove the need to plan ahead, monitor memory live, and scale back context size if inference starts to lag.
For most user cases on 12 GB GPUs, 7B models hit the sweet spot of power, speed and efficiency when paired with 16K–32K contexts. 14B models usually work when long context is not as important.
💡Choose wisely:
Smaller model, longer memory
Bigger model, shorter leash
And if generation starts to feel sluggish… check if you’re the victim of CPU sabotage. 🔌
Appendix:
🧪 Benchmark Environment
All performance tests in this guide were run on:
GPU: NVIDIA RTX 3060 (12 GB)
CUDA: Version 12.9
CPU: Intel Core i5–13400F
Backend: Ollama v0.6.7
OS: Windows 11
Performance may vary depending on driver versions, system load, OS, and backend optimizations.
🧠 Acronym Cheat Sheet
LLM — Large Language Model. A neural network trained to generate and understand human language.
GPU — Graphics Processing Unit. Accelerates parallel computations; ideal for deep learning.
CPU — Central Processing Unit. General-purpose processor; slower for LLM inference but with more RAM.
VRAM — Video RAM. Memory on the GPU; used to store model weights, activations, and KVCache.
KV Cache — Key/Value Cache. Stores attention vectors for past tokens; grows linearly with context length.
Context — The number of input + generated tokens that the model can attend to at once.
Quantized — Refers to using lower-precision integers (e.g., 4-bit, 8-bit) instead of floating point, to reduce memory use.
Q4_K_M — A 4-bit quantized format with good trade-off between memory footprint and model accuracy.
PCIe — Peripheral Component Interconnect Express. The data bus connecting GPU to CPU; limited bandwidth can bottleneck hybrid setups.
CUDA — Compute Unified Device Architecture. NVIDIA’s platform for GPU acceleration.
GQA — Grouped Query Attention. Reduces memory by sharing key/value projections across heads.
SWA — Sliding Window Attention. Limits attention to a window of recent tokens, cutting KV memory growth.
MLA — Multi-Latent Attention. Compresses KV tensors into a smaller latent space (e.g.,
k=128).RoPE — Rotary Positional Embedding. A method of encoding token position using sinusoidal rotations.
📚References
Zhang, H., Ji, X., Chen, Y., Fu, F., Miao, X., Nie, X., Chen, W., & Cui, B. (2024). PQCache: Product Quantization-based KVCache for Long Context LLM Inference. Manuscript, Peking University.
Ollama — local LLM inference engine using
llama.cpp.llama.cpp GitHub repo — the C++ backend powering Ollama
BitNet on GitHub — official framework for 1-bit LLMs (e.g., BitNet b1.58).
DeepSeek-R1 on Hugging Face — 671B parameter model using Multi-Latent Attention (MLA).
Subscribe to my newsletter
Read articles from Lyx directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by