Decoding AI Jargons
 Rachit Goyal
Rachit Goyal
Tokenization
Tokenization is the process of converting text into a sequence of tokens, which can be anything like words, sub-words, or characters. It may seem to us that LLMs understand Hindi, English, Numbers, practically everything in human existence, but under the hood, there are tokenizers working which convert any form of input into tokens. Each LLM has its own tokenization mechanism like( GPT, Gemini, DeepSeek etc.)
If you want to visualize how tokens are created, you can refer this link: https://tiktokenizer.vercel.app
What Tokenization simply does convert a user’s input into tokens: mostly integers

Vocab Size
Vocab Size refers to the size of the ‘vocabulary’ of the LLM, basically how many ‘unique tokens does it have.
Think of it like the English Vocabulary. There are a certain amount of unique words in English Vocabulary which are basically used in English. If we calculate the size of the Vocabulary of English Language, that will be come out to be in millions.
In the same fashion, LLMs have their own Vocab Size, which is the number of unique tokens they have.
GPT-4o has approximately 200k tokens and hence that is its vocab size.
Knowledge Cutoff
Every AI Company trains its LLM regularly, say once or twice every year.
The latest date until which the training dataset for the LLM is available is called the Knowledge Cutoff Date.
For Example:
For every LLM, the Knowledge Cutoff is mentioned by the company owning the LLM.

If your model is trained in 2024, it won’t have the data to 2025 events.
Like the LLM won’t know that RCB won IPL in 2025 even though it did. That’s Agentic AI that updates the latest information to the LLM.
Encoder & Decoder
Encoding is basically converting user inputs into tokens and Encoder is what who does this.
You can write your own encoder as well from scratch.
Decoding is the reverse of encoding where each encoded token is converted back into its original form.
Here is an example of an encoder I wrote which converts each character into a token

GPT has its own way of tokenizing.

Vector Embeddings

Have a look at the above picture.
Can you guess what will come in place of the “?”.
Of course, “Woman” is the correct answer.
You were able to answer that because your brain made connections or relations to it.
This is what vector embeddings mean high level.
Vector Embeddings basically bring out the semantic meaning of words.
ChatGPT defines:
Vector Embeddings to be “numeric vector representations of things like words, sentences, images, documents and even code!”
Words with similar meanings have closer vectors and they help capture the semantic relationships between words.
How to do this in code?
pip install sentence-transformers
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ['You are reading nikhil blog.']
embeddings = model.encode(sentences)
print(embeddings)
Here is a visualization of Vector Embeddings. The words having similar meanings are closer to each other than the ones having different meanings.

If you want to visualize, you can use this link: https://projector.tensorflow.org/
In simple terms, vector embeddings turn words into numbers, which computers understand and then map those numbers in such a way that the words having similar meanings are mapped closer to each other.
Just like on a map, ‘aircraft’ and ‘railway’ are mapped closer to each other since they have similar meanings.
Positional Encoding
Lets consider two sentences:
The River Bank
The SBI Bank
Here, a tokenizer might assign the same token to “Bank” even though the word has different meanings in a different context while having the same semantic meaning.
This is where positional encoding comes into the picture.
Positional Encoding (yes, once again) assigns numerical patterns to each position in the sequence, which help in differentiating between phrases like “river bank” and “SBI bank” even though the word ‘bank’ is the same, its meaning depends on where it is placed.
The motive of Positional Encoding is basically to tell the model where each token is placed.
Think of it this way:
“I love you” and “You love I” has completely different meanings but semantic meaning of each word is same. Positional Encoding assigns numbers to each token to reference its position so that it retains its meaning. They allow the model to detect relative positions, not just the absolute place.
Self Attention
In Self-Attention, we allow tokens to talk to each other, basically interact with each other and update their meaning accordingly.
Say we read a sentence:
The cat sat on the mat because it was tired.
How does a Transformer know what ‘it’ is referring to?
That’s exactly what Self-Attention does.
It looks at all other words in the sentence and then decide how much attention to pay each word.
Temperature
Temperature is the parameter that controls how much creative the response of the LLM is going to be.
A lower temperature means the LLM is going to be not at all creative and give the same answer. The answers are going to be very predictable and the Transformer always picks the most likely next word.
A higher temperature means the LLM is going to be creative with the responses and might give some out of worldish answer. It picks from a wider range of possible next answers. Responses become creative or even weird in some cases.

Softmax
Consider a scenario where you are chatting with ChatGPT, for every output:
The model predicts scores for each possible word. SoftMax turns these scores into probabilities. The model then samples or picks the next word using those probabilities.
The Softmax function creates a probability distribution for each output token in the vocabulary, allowing us to generate output tokens with certain probabilities.
Example:
Imagine you're hosting a pizza party and ask your friends to vote on toppings. Here's how they score each one:
Pepperoni: 8 votes —> (0.84)
Mushrooms: 4 votes —>(0.11)
Pineapple: 2 votes —>(0.05)
You want to randomly pick a topping based on the popularity. Softmax converts them into probabilities so that the LLM can choose one based on the probability.
In the above example, [0.84, 0.11, 0.05] are the probabilities that softmax generated.
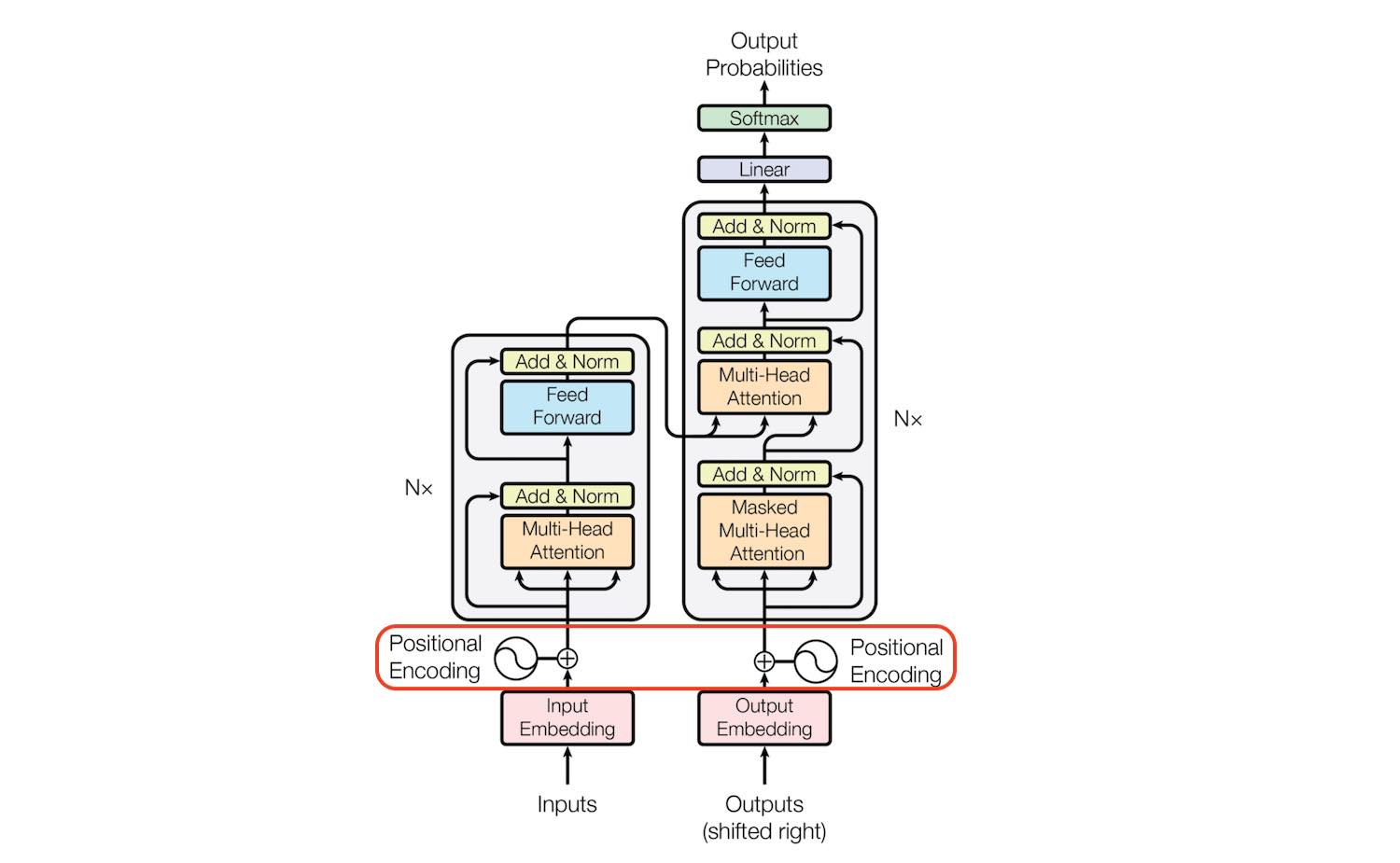
If you wish to know more about transformers, refer to this Research Paper “Attention Is All You Need” by Google.
Subscribe to my newsletter
Read articles from Rachit Goyal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Rachit Goyal
Rachit Goyal
i code sometimes