How HDDs and SSDs Store Data - The Block Storage Model
 Sachin Tolay
Sachin TolayWhen you open a file in your program, it seems like you can read or change any byte you want. But in reality, your storage device doesn’t work with single bytes. Instead, HDDs and SSDs read and write data in larger chunks, called blocks or pages, which are usually a few KBs in size.
This gap between what software wants (small, random access) and how storage hardware works (large, fixed-size chunks) is one of the most important challenges in computer systems.
In this article, we’ll explore:
The two fundamental models of data access → block-addressable and byte-addressable.
Why storage is not byte-addressable like RAM.
How HDDs and SSDs store and access data.
How the block model shapes performance and design.
The Two Fundamental Models: Byte-Addressable vs. Block-Addressable
Byte-Addressable Model
This is how RAM (DRAM) works.
Memory is organized as a sequence of individual bytes, each with its own address.
The CPU can read or write any single byte directly and instantly.
Latency is extremely low (nanoseconds), making random access cheap.
char value = buffer[100]; // Read exactly 1 byte
buffer[200] = 'A'; // Write exactly 1 byte
This fine-grained access makes it possible for RAM to support rich data structures like linked lists, trees, and pointer-chasing algorithms.
Block-Addressable Model
This is how storage devices (HDDs and SSDs) work.
Storage is divided into fixed-size chunks called blocks (in HDDs) or pages (in SSDs).
Typical block/page size: 4 KB or larger.
You cannot read or write a single byte on its own.
Even if you want just 1 byte, the device must read or write the entire block containing it.
Reads and writes operate on these blocks or pages as the atomic unit.
Why RAM and Storage Use Different Access Models
RAM (Byte-Addressable Memory): RAM is like having a mini-fridge in your bedroom. You can grab exactly the water bottle or even a single sip whenever you want → instantly and with no extra effort. This lets the CPU quickly access tiny pieces of data (like single bytes) whenever it needs them.
Storage (Block-Addressable Devices like HDDs/SSDs): Storage is like going all the way to the kitchen. You wouldn’t walk there just to pick up one water bottle → it’s too slow and inefficient. Instead, you grab the water bottle plus some snacks or other items you might need soon.
This means when your program requests data, the storage device reads or writes a whole block (the water bottle + snacks) at once, because making multiple trips for tiny data would be too slow and wear out the hardware faster.
How HDDs Store And Access Data
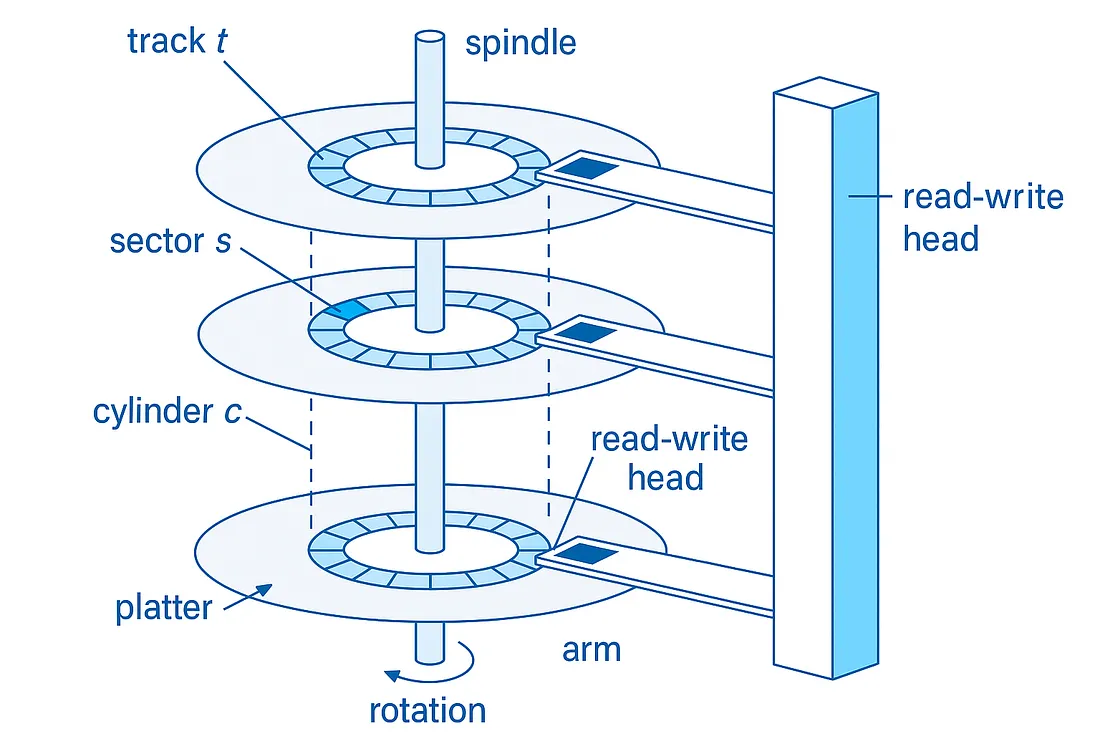
HDDs are electromechanical devices that store data magnetically on spinning disks called platters.
Platters spin at thousands of RPM (e.g., 5,400, 7,200, 10,000, or 15,000 RPM).
Each platter has concentric tracks divided into sectors (typically 512 bytes or 4 KB).
Each surface of a platter has its own read/write head.
All heads are mounted on a single actuator arm that moves them in unison across the platters.
How Read Works
When you read data from a hard drive, 3 steps are involved:
- Seek Time: Moving the Arm
The actuator arm moves the read/write heads to the correct track (cylinder).
Typical time: 4–10 ms
Think of it like → Moving a record player needle to the right groove.
Rotational Latency: Waiting for the Right Sector Once the head is on the correct track, the disk must rotate so the exact sector spins under the head.

Think of it like → Waiting for the spinning wheel to bring your slice in front of you
Typically half a rotation worth of time.
- Data Transfer
Once aligned, data is read sector by sector.
Sequential reads are much faster since the head stays on track.
How Write Works
Writing to an HDD follows the same physical steps as reading:
Seek to the correct track.
Wait for rotation to align the sector.
Transfer data sector by sector.
Handling Changes/Edits in Files
When you edit a file on an HDD, the operating system has to figure out where to put the new or changed data on the disk.
If it’s a small change → like fixing a typo or tweaking a line → the OS can often just overwrite the existing spot directly. It’s quick and easy.
If you add more content →like inserting whole paragraphs or lots of new data → the old space might not be big enough anymore. The OS then has to find free sectors somewhere else on the disk and write the new data there.
After writing, the OS keeps track of where all the pieces of the file are so it can read them in the right order later.
Over time, as you keep editing and adding, parts of the file can end up scattered in many places on the disk. This is called fragmentation. It means the read/write head has to jump around more, which slows things down.
To keep everything fast and tidy, operating systems use techniques like buffering, batching, and defragmentation. These help organize writes better and reduce unnecessary movement.
How SSDs Store and Access Data

SSDs have no moving parts and store data in flash memory cells arranged into pages and blocks.
Pages are typically 4 -16 KB each.
Blocks contain many pages (e.g., 256 pages per block).
All management is handled by the SSD controller and its Flash Translation Layer (FTL).
How Read Works
Reading data from an SSD is simple and fast, thanks to the lack of mechanical parts.
Page-Level Reads
SSDs store data in pages (typically 4 -16 KB each).
Reads happen at the page level → you can’t read less than a page.
Example → Imagine your notebook. If you want a single note, you have to look at the whole page. You can’t magically see just one word without opening the page. Similarly, SSDs always read entire pages, even if your program only wants a few bytes.
No Moving Parts
Unlike HDDs, SSDs have no mechanical parts like spinning platters or moving heads.
There’s no seek time or rotational delay.
Reads are extremely fast → typically tens to hundreds of microseconds.
Example → It’s like opening a notebook instantly to the right page, with no need to flip through slowly.
Flash Translation Layer (FTL)
The SSD controller uses a Flash Translation Layer (FTL) to keep track of where data is physically stored in NAND flash.
When you request data, the FTL quickly maps your logical request to the right physical page and retrieves it.
This mapping is completely invisible to the operating system and user.
Example → Think of having an index at the front of your notebook that tells you exactly which page to turn to for each topic.
How Write Works
When writing data to an SSD, the process is a bit more complex than reading:
Out-of-Place Writes
Flash memory can’t overwrite existing data in place.
New data is always written to a free page.
The old page is marked invalid.
Example → Think of a notebook with 256 pages (like a flash block). If there are blank pages left, you can write on them immediately. This is how SSDs handle new data → they just use the next available free page without any extra work.
Erase Before Write Requirement
Once all pages in a block have been written (even if many are now invalid), they can’t just be overwritten.
Flash requires erasing the entire block at once to make its pages writable again.
Example → Imagine you wrote with a pen in that notebook. If you want to change what’s on a page, you can’t just erase a single line. You’d have to rip out the entire sheet to get a fresh, blank page. Similarly, SSDs must erase the whole block to reuse its pages.
Garbage Collection
The SSD’s controller periodically cleans up space by copying valid pages elsewhere and erasing blocks.
This process consolidates free space and makes new pages available for writing.
Example: Out of 256 pages in a block, maybe 200 are invalid (old data you don’t need). 56 pages are still valid. The SSD will:
Copy the 56 valid pages to another clean block.
Erase the original block completely. — Now, all 256 pages are blank and ready for new writes.
How the Block Model Shapes Performance and Design

Block-based storage prefers bigger, aligned, sequential operations. Software is designed to take advantage of this by buffering, batching, and organizing data to reduce costly small writes.
Subscribe to my newsletter
Read articles from Sachin Tolay directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sachin Tolay
Sachin Tolay
I am here to share everything I know about computer systems: from the internals of CPUs, memory, and storage engines to distributed systems, OS design, blockchain, AI etc. Deep dives, hands-on experiments, and clarity-first explanations.