Optimal Usage Based on Cloud Run Functions Directory Structure
 Tanuki Developers
Tanuki Developers
Introduction
When implementing simple backend processes, what should you use in GCP?
Here are some products that come to mind. Can you explain the differences between them?
Cloud Run Functions
Cloud Functions for Firebase
Cloud Run Service
Cloud Run Jobs
Batch
I must admit, I don't fully understand all of them yet, but each product has its intended use case, so it's important to consider requirements and find the optimal solution.
What I Want to Do
This time, I want to create a simple task: "Send a message to Slack when a document is created in Firestore."
As you develop products, there are a lot of services you have to manage. If you can immediately catch important events or KPIs in Slack—alongside error notifications, operations become much easier.
Since this requirement is an event-triggered task instead of scheduled execution, Cloud Run Jobs and Batch, which are designed for periodic execution and require customization for event triggers, are excluded from consideration this time.
Why Not Cloud Functions for Firebase?
Cloud Functions for Firebase seems perfect for this task regarding the service name itself, but after some testing, I found a few limitations:
Supported languages are only Node.js and Python, which is fewer than the main Cloud Functions service
Debugging in Python doesn't work with IDE debuggers, so you have to rely on logging or print statements
Functions for Firebase allow you to write simpler integration code with Firebase products compared to regular Functions, but you can achieve the same results even if you use regular Functions, so I decided to exclude it this time.
Note: the debugger issue has been open for over a year, suggesting that Node.js is the assumed language, and it may be technically impossible for Python.
https://github.com/firebase/firebase-tools/issues/6838
Differences Between Cloud Run Service and Functions
That leaves Cloud Run (Service) and Functions. What's the difference?
An article provides the following comparison:
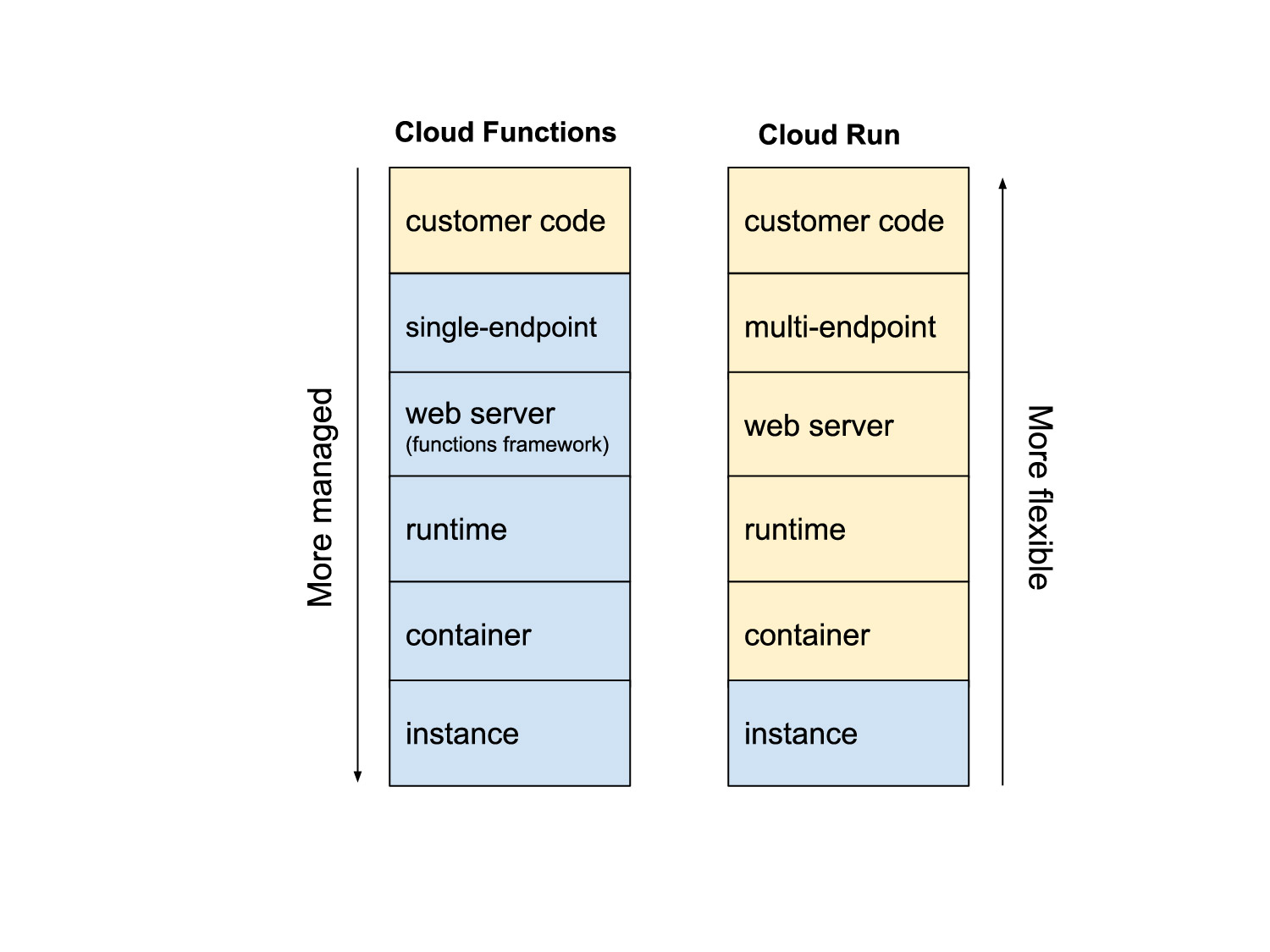
Source: Google Cloud Blog: Cloud Functions vs. Cloud Run: when to use one over the other
As shown in the image, Functions only require you to maintain the code, while everything else is managed, which is a key advantage. Now that Functions have been integrated into Cloud Run, the infrastructure after deployment is almost the same.
Given my requirements, I questioned whether Cloud Run Service was necessary, so I prioritized simplicity and decided to implement with Functions first.
Functions Directory Structure
This time, there are two Firestore collections to notify Slack about, so I need to create two Functions.
You'll also need products like Eventarc or Pub/Sub as triggers, but with Functions, you only need to add a small amount of code to the function and deployment command, making it very convenient.
@functions_framework.cloud_event
def function1(cloud_event: CloudEvent) -> str:
...
gcloud functions deploy function1 \
--runtime python312 \
# Specify Eventarc options here
--trigger-location {firestore-location} \
--trigger-event-filters type=google.cloud.firestore.document.v1.created \
--trigger-event-filters database="(default)" \
--trigger-event-filters-path-pattern=document='your-collection/{document}' \
--entry-point function1 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID
Common processes like logging and Slack notifications are grouped in a commons directory and imported from each Function.
functions/
├── commons
│ ├── slack.py
│ └── custom_logger.py
├── function1
│ ├── main.py
│ └── requirements.txt
├── function2
│ ├── main.py
│ └── requirements.txt
Now, you'd want to deploy, but this will result in an error. Why?
The reason is that, in Functions, you can't specify code above the main.py entry point in the directory hierarchy.
As a result, commons is excluded during build, causing a code not found error.
You could move or package commons during build, but that complicates things and undermines the simplicity of Functions, so it's not a great option.
According to the official documentation, the recommended structure for managing multiple functions is as follows:
functions/
├── src
│ ├── commons
│ │ ├── slack.py
│ │ └── custom_logger.py
│ ├── function1.py
│ └── function2.py
├── requirements.txt
└── main.py
main.py serves as the entry point and simply imports the actual implementations:
from src.function1 import *
from src.function2 import *
This approach keeps the code DRY, but:
If there's an error in function2, deployment of function1 fails
Each function creates a separate Docker image, leading to unnecessary storage costs
As the number of functions grows, these drawbacks become more significant.
It seems Functions are intended for much smaller processes, where shared code isn't needed, compared to what I initially thought.
Still, since I only have two types this time, I decided to deploy as is.
Summary
I've learned a bit more about Cloud Run Functions.
It's certainly convenient to deploy functions without worrying about infrastructure, so:
Start with Cloud Run Functions for a minimal implementation
If similar features increase and it makes sense to build a single application, migrate to Cloud Run Service or Jobs, which support multiple endpoints
This seems like a good approach.
Finally, be sure to check out Tanuki's information as well!
Subscribe to my newsletter
Read articles from Tanuki Developers directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Tanuki Developers
Tanuki Developers
Tanuki - Shop, Review & Share Tanuki is a shopping management app that makes your daily shopping smarter and more enjoyable. Register your frequently purchased items in a shopping list and shop in a more organized way.