The Fault-Tolerant Job Queue You’ll Actually Understand – in Go
 Yashaswi Kumar Mishra
Yashaswi Kumar Mishra
Async job queues are the quiet workhorses behind a lot of the stuff you take for granted, sending emails, processing payments, resizing images, crunching analytics. Basically, any task that doesn’t need to happen right now but still needs to get done, reliably. A good job queue takes these tasks, runs them in the background, retries if something fails, and makes sure things don’t fall through the cracks.
You need one when your app starts to grow up. Maybe you're dealing with slow external APIs. Maybe your users are uploading giant files. Or maybe your backend is doing a lot of heavy lifting, and you just want to keep your main flow snappy. Async queues are built for this. They give you timeouts, retries, and even distributed execution if you're scaling across multiple workers.
So why not just use Celery, Sidekiq, or something off the shelf? You totally could. But most of those systems come with big batteries included, Redis, RabbitMQ, a whole runtime, sometimes even their own DSL. That’s great for big teams and big infra. But if you're trying to deeply understand how things actually work or just want to build something lean, it's a lot of overhead.
That's why this one’s in Go. Concurrency in Go is smooth. Goroutines and channels are basically made for this kind of system. No runtime bloat, no Java-style ceremony. Just straight-up efficient task handling with great performance, clarity, and simplicity.
In this blog, we’re going to build our own async job queue system from scratch. Real code. Real retries. Real persistence. Let’s get to work. Also here is the github repo : https://github.com/pixperk/asynq
I am writing this up alongside building the whole thing, so I will keep it as long as it takes me . Okay, I cracked my fingers and now let’s write some code and think a little. My initial plan is to structure a Job Queue and make every popped job go through a worker which will process the job. Let’s define the job interface first and then we will ponder about how we can take it further.
So the idea of the interface is that a “job” can be anything that can be executed, so every job must have an Execute() method.
type Job interface {
Execute() error
}
Our queue can be a channel for receiving these jobs. A simple struct like the following will do for now.
type JobQueue struct {
jobs chan Job
}
The plan is to do something like Submit(job) which will send the job into the channel. And JobQueue struct will hold the buffered channel and the worker.
Now, we will need a worker. It can be a simple go routine, which receives jobs from the channel and calls Execute(). It is a go routine so that it can run in the background, pick up the jobs and process them.
go func(){
for job := range q.jobs {
job.Execute()
}
}()
Now we want this to be triggered as soon as our queue is initialized. So let’s make a constructor for our JobQueue struct and put this go routine in there.
func NewJobQueue(buffer int) *JobQueue {
q := &JobQueue{
jobs: make(chan Job, buffer),
}
go func() {
for job := range q.jobs {
job.Execute()
}
}()
return q
}
And then write a small function for the JobQueue struct to dump jobs in the queue (channel).
func (q *JobQueue) Submit(job Job) {
q.jobs <- job
}
So, this is our very first idea of the Job Queue. Let’s get going and create a new job, let’s call it SampleJob. We will make the struct and implement the Execute method on it.
type SampleJob struct {
ID int
}
func (s *SampleJob) Execute() error {
startTime := time.Now()
fmt.Printf("🔧 Job %d started at %s\n", s.ID, startTime.Format("15:04:05.000"))
time.Sleep(2 * time.Second) // simulate slowness
endTime := time.Now()
duration := endTime.Sub(startTime)
fmt.Printf("✅ Job %d finished at %s (duration: %v)\n", s.ID, endTime.Format("15:04:05.000"), duration)
return nil
}
I have modelled each job to take 2s of time. Let’s write our main function and see how our job queue performs.
func main() {
q := job.NewJobQueue(10)
start := time.Now()
for i := 1; i <= 5; i++ {
q.Submit(&job.SampleJob{ID: i})
}
// Wait for all jobs to complete (5 jobs * 2s = ~10s total)
time.Sleep(11 * time.Second)
fmt.Printf("\nTotal execution time: %.2fs\n", time.Since(start).Seconds())
}
As we have only 1 worker now, all jobs will be queued behind each other. Let’s see the output logs.
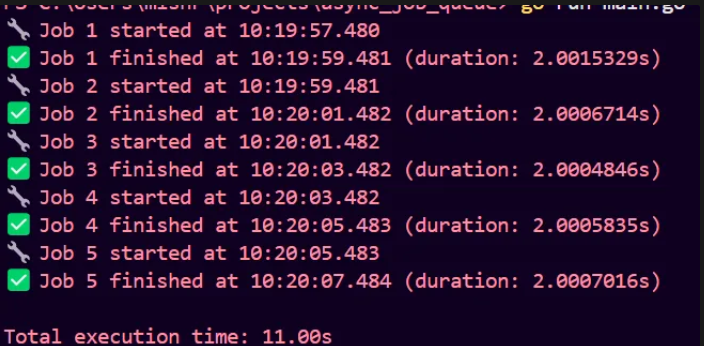
Every job is running synchronously and the total time is sum of all job times. We don’t want this. If one of the jobs break, everything else will be bottlenecked. So we have got only one worker, and we can’t scale. Apart from that, we have :
No status or tracking
No retry or error handling
No job types
Crashes = all jobs die
Let’s spin up multiple workers now. We can change our JobQueue struct and introduce workers and waitgroup fields.
type JobQueue struct {
jobs chan Job
workers int
wg sync.WaitGroup
}
sync.WaitGroup is like a counter that tracks a group of goroutines and block execution until all of them signal completion.
Let’s break down its core API:
wg.Add(delta int)
This increments (or decrements) the counter by delta.
Usually delta is +1 when you’re launching a new task.
This tells the WaitGroup:
"I now have 1 more task I’m waiting on."
You can call Add(n) before launching n goroutines.
wg.Done()
This is shorthand for wg.Add(-1).
It tells the WaitGroup:
"This specific task has finished its job."
Every Done() call must match an Add(1). If it doesn't, the counter never reaches zero, and Wait() blocks forever (deadlock).
wg.Wait()
Blocks the calling goroutine (usually main() or a coordinator)
"Don't move forward until all tracked tasks have called Done() and the counter reaches zero."
With all this in our head, let us modify some job methods. Let’s modify the constructor first.
func NewJobQueue(buffer int, workers int) *JobQueue {
q := &JobQueue{
jobs: make(chan Job, buffer),
workers: workers,
}
for i := 0; i < q.workers; i++ {
go func(workerID int) {
for job := range q.jobs {
fmt.Printf("👷 Worker %d picked a job\n", workerID)
job.Execute()
q.wg.Done()
}
}(i + 1)
}
return q
}
jobs channel is now a shared queue across multiple goroutines and we spawn N workers while initializing the new queue. We let sync.WaitGroup track the job completion.
Let’s go ahead and modify our Submit method to add the job to the waitgroup.
func (q *JobQueue) Submit(job Job) {
q.wg.Add(1)
q.jobs <- job
}
We define two more methods on our JobQueue struct : Wait and Shutdown .
Wait() blocks until all jobs are done and Shutdown() gracefully closes the job channel.
func (q *JobQueue) Wait() {
q.wg.Wait()
}
func (q *JobQueue) Shutdown() {
close(q.jobs)
}
Now let’s modify our main function to comply with the changes we just made.
func main() {
start := time.Now()
buffer, workers := 10, 3
q := job.NewJobQueue(buffer, workers)
for i := 1; i <= 5; i++ {
q.Submit(&job.SampleJob{ID: i})
}
q.Wait()
q.Shutdown()
fmt.Printf("\nTotal execution time: %.2fs\n", time.Since(start).Seconds())
}
We removed time.Sleep , thanks to sync.WaitGroup . It knows exactly when all jobs are done and only then unblocks the main goroutine. Let us run the main and check for the output.
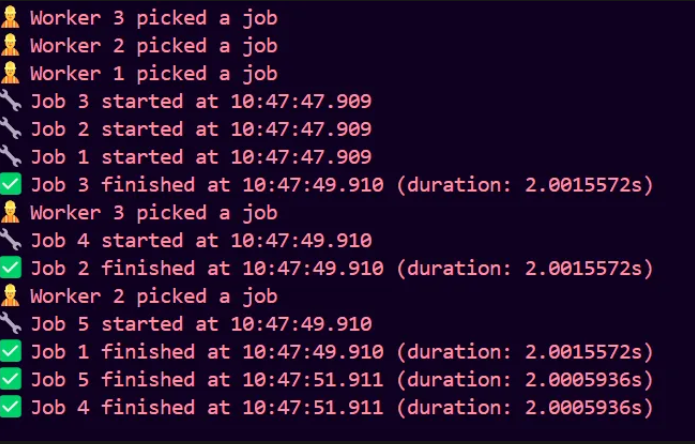
As we have 3 workers, 3 jobs can run parallelly, jobs 3,2 and 1 run parallelly and take 2 seconds to complete in total. After this, workers pick up the remaining jobs and take 2 seconds to process. The main thread waits precisely until the last job is finished, then exits.
This works, but we still have no clue, what has to be done if one of our jobs fail. We have minimal to no error handling or retry mechanism. Let’s improve this.
Evidently, we now want to track our jobs. Let’s make a tracked job structure which will contain metadata like status, retries, etc. We will wrap our Jobinterface with it later which currently just does Execute() error .
type TrackedJob struct {
Job Job //wrap job interface
RetryCount int
MaxRetries int
Status JobStatus
LastError error
mu sync.Mutex
}
The mutex mu ensures thread-safe updates to the job state when workers access it concurrently.
Also, we need an enum like structure for job status. Here is how we write it.
type JobStatus string
const (
StatusPending JobStatus = "PENDING"
StatusRunning JobStatus = "RUNNING"
StatusFailed JobStatus = "FAILED"
StatusSuccess JobStatus = "SUCCESS"
)
Now we have to wrap our Execute() with retry logic and status tracking Our main aim is to track the status here, and make sure only one thread can write status so we wrap it in mutex. If we encounter errors, we will retry till max retry count and we keep updating the last error, status and retry count. We will wrap all the writes to the struct with the mutex.
func (t *TrackedJob) ExecuteWithRetry() {
t.mu.Lock()
t.Status = StatusRunning
t.mu.Unlock()
for attempt := 1; attempt <= t.MaxRetries+1; attempt++ {
err := t.Job.Execute()
if err != nil {
...
}
} else {
t.mu.Lock()
t.Status = StatusSuccess
t.mu.Unlock()
fmt.Printf("✅ Job succeeded on attempt %d\n", attempt)
return
}
}
}
We put the status as StatusRunning at beginning and then if the job executes successfully, we update it to StatusSuccessful, we run this execution cycle till MaxRetriesand if we are successful, we break out. What to do if the execution gives an error? We retry and continue the loop.
if err != nil {
//track the job
t.mu.Lock()
t.LastError = err
t.Status = StatusFailed
t.RetryCount = attempt
t.mu.Unlock()
fmt.Printf("Attempt %d failed: %v\n", attempt, err)
if attempt <= t.MaxRetries {
fmt.Printf("Retrying job (attempt %d)...\n", attempt+1)
time.Sleep(500 * time.Millisecond) // backoff delay
continue
}
Now this is what we have as our retry engine. And we have some sort of tracking mechanism as well. Let us modify our JobQueueto work with TrackedJob
type JobQueue struct {
jobs chan *TrackedJob
workers int
wg sync.WaitGroup
}
Now the jobs channel is of type TrackedJob (earlier it was the Jobinterface)
Our constructor changes as well to comply with this.
func NewJobQueue(buffer int, workers int) *JobQueue {
q := &JobQueue{
jobs: make(chan *TrackedJob, buffer),
workers: workers,
}
for i := 0; i < q.workers; i++ {
go func(workerID int) {
for job := range q.jobs {
fmt.Printf("👷 Worker %d picked a job\n", workerID)
job.ExecuteWithRetry()
q.wg.Done()
}
}(i + 1)
}
return q
}
We need to change our Submit implementation as well. It takes maxRetries now, and makes a TrackedJob struct with StatusPending
func (q *JobQueue) Submit(job Job, maxRetries int) {
q.wg.Add(1)
tracked := &TrackedJob{
Job: job,
MaxRetries: maxRetries,
Status: StatusPending,
}
q.jobs <- tracked
}
Now, we can also define a status function for our TrackedJobto poll job status later
func (t *TrackedJob) StatusString() string {
t.mu.Lock()
defer t.mu.Unlock()
return string(t.Status)
}
Let’s define an ErroneousJob to test our implementation.
type ErroneousJob struct {
ID int
Attempts int
}
func (f *ErroneousJob) Execute() error {
f.Attempts++
fmt.Printf("Executing ErroneousJob %d (attempt %d)\n", f.ID, f.Attempts)
if f.Attempts < 3 {
return fmt.Errorf("simulated failure on attempt %d", f.Attempts)
}
time.Sleep(1 * time.Second)
fmt.Printf("🎉 ErroneousJob %d succeeded\n", f.ID)
return nil
}
If attempts are less than 3, it will always error out, perfect for testing. Our main function should look like the following now.
func main() {
start := time.Now()
buffer, workers := 10, 3
q := job.NewJobQueue(buffer, workers)
maxRetries := 5
q.Submit(&job.ErroneousJob{ID: 2}, maxRetries)
q.Wait()
q.Shutdown()
fmt.Printf("\nTotal execution time: %.2fs\n", time.Since(start).Seconds())
}
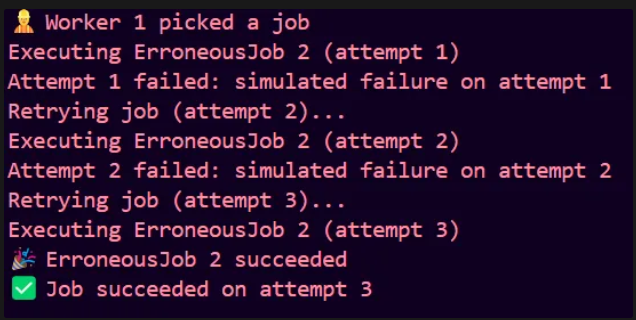
The job succeeds on 3rd retry, so the retry system works fine. Let’s spin up 5 such jobs and see how it works. The modified main looks like this :
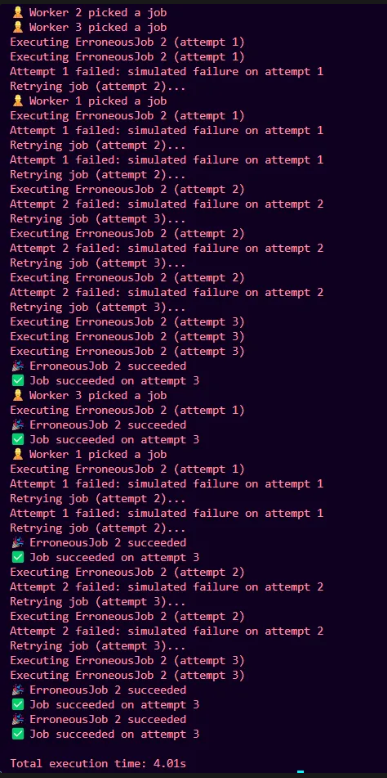
It works perfectly.
So, now we have got a retry mechanism and our jobs are tracked, all this along with concurrent job execution. But the Job Metadata is not persistent, nor do we have Job IDs & external status querying. We also do not have proper retry strategy tuning (backoff/jitter). Let’s look to make it better. Our goal is to devise a global tracking layer for external status querying. We will start by introducing a JobID in our TrackedJob struct. We will generate this id in Submit using a simple UUID generator.
type TrackedJob struct {
JobID string
Job Job //wrap job interface
RetryCount int
MaxRetries int
Status JobStatus
LastError error
mu sync.Mutex
}
Now we can write our global tracker. It will be a struct with a read-write mutex (exclusive locking for writes and shared access for reads) and an in-memory hashmap (for now) mapping each job to its metadata.
type JobTracker struct {
mu sync.RWMutex
store map[string]*JobMetadata
}
The JobMetadata struct will be like this :
type JobMetadata struct {
JobID string
Status JobStatus
RetryCount int
LastError error
CreatedAt time.Time
UpdatedAt time.Time
}
Let’s build a constructor for JobTracker
func NewJobTracker() *JobTracker {
return &JobTracker{
store: make(map[string]*JobMetadata),
}
}
Now we will implement methods on this JobTracker to register a job in the store and update the store.
func (jt *JobTracker) Register(jobID string) {
jt.mu.Lock()
defer jt.mu.Unlock()
jt.store[jobID] = &JobMetadata{
JobID: jobID,
Status: StatusPending,
CreatedAt: time.Now(),
UpdatedAt: time.Now(),
}
}
func (jt *JobTracker) Update(jobID string, status JobStatus, retry int, err error) {
jt.mu.Lock()
defer jt.mu.Unlock()
if meta, exists := jt.store[jobID]; exists {
meta.Status = status
meta.RetryCount = retry
meta.LastError = err
meta.UpdatedAt = time.Now()
}
}
We make use of mutex, to ensure that the writes are atomic.
We write a small method to print the status of all jobs at a time.
func (jt *JobTracker) PrintAll() {
jt.mu.RLock()
defer jt.mu.RUnlock()
fmt.Println("\n Job Tracker Status:")
for _, meta := range jt.store {
fmt.Printf("- [%s] JobID: %s | Retries: %d | Error: %v | Updated: %s\n",
meta.Status, meta.JobID, meta.RetryCount, meta.LastError, meta.UpdatedAt.Format("15:04:05"))
}
}
Now we can easily plug this tracker into out main JobQueue
type JobQueue struct {
jobs chan *TrackedJob
workers int
wg sync.WaitGroup
tracker *JobTracker
}
func NewJobQueue(buffer int, workers int) *JobQueue {
q := &JobQueue{
jobs: make(chan *TrackedJob, buffer),
workers: workers,
tracker: NewJobTracker(),
}
//...existing background workers
}
Let us write a simple util to generate jobIDs.
func GenerateJobID() string {
b := make([]byte, 4)
_, err := rand.Read(b)
if err != nil {
return "job-xxxx"
}
return fmt.Sprintf("job-%x", b)
}
Now let us update Submit() to:
generate a JobID
assign to TrackedJob
register with tracker
func (q *JobQueue) Submit(job Job, maxRetries int) {
q.wg.Add(1)
jobID := GenerateJobID()
tracked := &TrackedJob{
JobID: jobID, //Add
Job: job,
MaxRetries: maxRetries,
Status: StatusPending,
}
q.tracker.Register(jobID)
q.jobs <- tracked
}
Now the final thing left is to update Tracker inside ExecuteWithRetry
For that we will have to inject this tracker into the TrackedJob struct
type TrackedJob struct {
JobID string
Job Job
RetryCount int
MaxRetries int
Status JobStatus
LastError error
Tracker *JobTracker //Add
mu sync.Mutex
}
And in Submit(), we can do this :
func (q *JobQueue) Submit(job Job, maxRetries int) {
q.wg.Add(1)
jobID := GenerateJobID()
tracked := &TrackedJob{
JobID: jobID,
Job: job,
MaxRetries: maxRetries,
Status: StatusPending,
Tracker: q.tracker, //Add
}
q.tracker.Register(jobID)
q.jobs <- tracked
}
Now in the ExecuteWithRetry method, we can update our Tracker ledger.
We update the Tracker at all three places where we initially wrote into the TrackedJob struct
t.mu.Lock()
t.Status = StatusRunning
//Update ledger
t.Tracker.Update(t.JobID, StatusRunning, 0, nil)
t.mu.Unlock()
t.mu.Lock()
t.mu.Lock()
t.LastError = err
t.Status = StatusFailed
t.RetryCount = attempt
//Update ledger
t.Tracker.Update(t.JobID, StatusFailed, attempt, err)
t.mu.Unlock()
t.mu.Lock()
//Update ledger
t.Tracker.Update(t.JobID, StatusSuccess, attempt, nil)
t.Status = StatusSuccess
t.mu.Unlock()
Now our jobs are being tracked, let’s print the store status in main. First let’s expose the PrintAll function through JobQueue.
func (q *JobQueue) StoreStatus() {
q.tracker.PrintAll()
}
And we can add this line in main.
q.StoreStatus()
This is the output we get (for the StoreStatus)
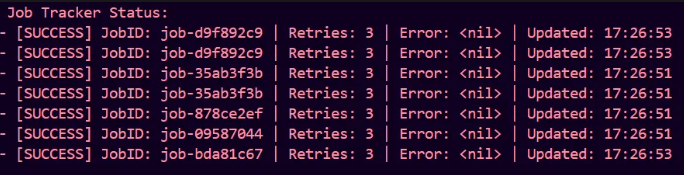
Yes, it does it correctly. Our jobs are being tracked correctly. We can add persistence to our jobs later. The big question is why are there two separate things : JobTracker and TrackedJob ? TrackedJob is responsible for the execution and retry logic of a single job ,it handles its own lifecycle. JobTracker is a decoupled, centralized ledger used purely for auditing, visibility, and external monitoring.
We keep them separate to ensure a clear separation of concerns between job execution and job tracking.
****With all that in place, let us look to improve our retry system a little more. Currently, we are not delaying the wait between two retries, but what if two concurrent jobs fail at the same time? They will look to retry at the same time putting more load at our resources. So we will introduce two things in our retry mechanism.
Exponential Backoff : We want to increase the wait time between retries exponentially. For ex : 500ms for 1st retry, 1s for another, 2s for third, 4s for fourth and so on. Why but? It gives our downstream systems time to recover, reduces request floods and prevents concurrent retries from multiple jobs.
Jitter : We will aim to add randomness to the retry delay. Instead of retrying all clients at exactly 2s, you retry somewhere in 1.5s – 2.5s. Why?
Prevents the "thundering herd problem" (thousands of jobs retrying at the same time)
Helps stagger retries in distributed systems.
Reduces contention on databases, queues, APIs, etc.
Let us make our Backoff Strategy plug-n-play, we code this up in the retry package, then just plug it into our ExecuteWithRetry() .
BackOffStrategy will be an interface with a method called NextDelay which will return the delay duration.
type BackoffStrategy interface {
NextDelay(attempt int) time.Duration
}
Now, our strategy is Exponential Backoff with Jitter, let us structure ExponentialBackoff. We will need BaseDelay, MaxDelay and a bool to decide if want to add jitter or not.
type ExponentialBackoff struct {
BaseDelay time.Duration //initial delay
MaxDelay time.Duration
Jitter bool
}
Now, it must implement NextDelay() .
func (b ExponentialBackoff) NextDelay(attempt int) time.Duration {
exp := float64(b.BaseDelay) * math.Pow(2, float64(attempt-1))
delay := time.Duration(exp)
return delay
}
It can be this simple, but what if the delay is greater than the maximum delay time, then we cap the delay at MaxDelay
exp := float64(b.BaseDelay) * math.Pow(2, float64(attempt-1))
delay := min(time.Duration(exp), b.MaxDelay)
return delay
And let’s add jitter if it is enable, let’s go for 30% jitter. We could have also dynamically taken the percentage, but 30% sounds good.
if b.Jitter {
jitter := rand.Float64()*float64(delay) * 0.3
delay += time.Duration(jitter)
}
It works like this : (Example)
Original delay: 4 seconds
Random factor: 0.8 (from
rand.Float64())Jitter:
0.8 * 4s * 0.3 = 0.96 secondsFinal delay:
4s + 0.96s = 4.96 seconds
Instead of all clients retrying at exactly 4 seconds, they'll now retry at random times between 4.0s and 5.2s (4s + 0% to 30% jitter).
This provides a 0% to +30% variance above the base exponential backoff delay. So, our final implementation will look this this :
func (b ExponentialBackoff) NextDelay(attempt int) time.Duration {
exp := float64(b.BaseDelay) * math.Pow(2, float64(attempt-1))
delay := min(time.Duration(exp), b.MaxDelay)
if b.Jitter {
jitter := rand.Float64() * float64(delay) * 0.3
delay += time.Duration(jitter)
}
return delay
}
Now, our plug-n-play Backoff strategy is ready. Time to plug it into our TrackedJob struct.
type TrackedJob struct {
JobID string
Job Job //wrap job interface
RetryCount int
MaxRetries int
Status JobStatus
LastError error
Tracker *JobTracker
Backoff retry.BackoffStrategy //Add
mu sync.Mutex
}
And in our ExecuteWithRetry(), will make the following changes
if attempt <= t.MaxRetries {
delay := t.Backoff.NextDelay(attempt) //Add
fmt.Printf("Retrying job (attempt %d)...\n", attempt+1)
time.Sleep(delay) // backoff delay
continue
Now whenever, a TrackedJob is created, we can pass our ExponentialBackoff in the Backoff field. We do this in our Submit() function.
func (q *JobQueue) Submit(job Job, maxRetries int) {
q.wg.Add(1)
jobID := GenerateJobID()
tracked := &TrackedJob{
JobID: jobID,
Job: job,
MaxRetries: maxRetries,
Status: StatusPending,
Tracker: q.tracker,
Backoff: retry.ExponentialBackoff{ //Add
BaseDelay: 500 * time.Millisecond,
MaxDelay: 5 * time.Second,
Jitter: true,
},
}
q.tracker.Register(jobID)
q.jobs <- tracked
}
Now, our retries are resilient with beautiful exponential backoff with jitter implementation.
Now, let us make our jobs “context” aware. If a job hangs (infinite loopor external call, etc.), we will literally need a kill switch. With context.WithTimeout, we can force jobs to bail if they exceed their allowed execution window. Also if our entire worker pool shuts down (e.g. SIGINT), we should be able to cancel the root context, and all in-progress jobs will also gracefully terminate. This is what structured concurrency is, our cancellation chains are clean and scoped. Further, we need to respect deadlines from clients. When exposing an HTTP API later, we can pass the HTTP request’s context into jobs. If the client bounces, we stop the job. Let’s start by allowing the Execute method inside our main Job interface take a context as param.
type Job interface {
Execute(ctx context.Context) error
}
Now. in our ExecuteWithRetry(), let’s introduce context.WithTimeout with background context. We will eventually refactor it, but we just want it to be up and running for now.
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel() // cleanup context even if job returns early
err := t.Job.Execute(ctx)
We will also log if the error is “timed out”
if errors.Is(err, context.DeadlineExceeded) {
fmt.Printf("Job attempt %d timed out\n", attempt)
} else {
fmt.Printf("Attempt %d failed: %v\n", attempt, err)
}
Let’s check this by writing a SleepyJob.
type SleepyJob struct {
Duration time.Duration
}
func (j *SleepyJob) Execute(ctx context.Context) error {
select {
case <-time.After(j.Duration):
fmt.Println("😴 Job finished sleeping")
return nil
case <-ctx.Done():
return ctx.Err() // return context.Canceled or context.DeadlineExceeded
}
}
And we update our main function. (Keeping maxRetries = 0)
func main() {
start := time.Now()
buffer, workers := 10, 3
q := job.NewJobQueue(buffer, workers)
q.Submit(&job.SleepyJob{Duration: 1 * time.Second}, 0)
q.Submit(&job.SleepyJob{Duration: 6 * time.Second}, 0)
q.Wait()
q.Shutdown()
q.StoreStatus()
fmt.Printf("\nTotal execution time: %.2fs\n", time.Since(start).Seconds())
}
We get this
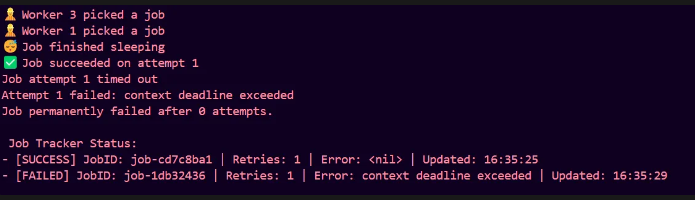
So, this is works just fine. I just noticed that we are getting Retries : 1 in our final logs, but that is just the attempt count. We can rename that, but for now let us focus on our functionalities.
Now let us make the timeouts dynamic, let us first inject a timeout field in our TrackedJob struct.
type TrackedJob struct {
JobID string
Job Job //wrap job interface
RetryCount int
MaxRetries int
Status JobStatus
LastError error
Tracker *JobTracker
Backoff retry.BackoffStrategy
Timeout time.Duration //Add
mu sync.Mutex
}
With this our ExecuteWithRetry() is ready to take a context from outside. We change the function signature to ExecuteWithRetry(ctx Context.context)
Change the previous context implementation to below :
// Derive a child context with timeout for this attempt
attemptTimeout := t.Timeout
if attemptTimeout == 0 {
attemptTimeout = 5 * time.Second // default fallback
}
attemptCtx, cancel := context.WithTimeout(ctx, attemptTimeout)
defer cancel()
err := t.Job.Execute(attemptCtx)
Now let’s modify our NewJobQueue to take in a context so that it can pass it down to ExecuteWithRetry .
func NewJobQueue(ctx context.Context, buffer int, workers int) *JobQueue
Now let’s modify the internal go routine for graceful context based shutdown.
go func(workerID int) {
for {
select {
case <-ctx.Done():
fmt.Printf("Worker %d shutting down: %v\n", workerID, ctx.Err())
return
case job, ok := <-q.jobs:
if !ok {
fmt.Printf(" Job channel closed. Worker %d exiting\n", workerID)
return
}
fmt.Printf("👷 Worker %d picked a job\n", workerID)
job.ExecuteWithRetry(ctx)
q.wg.Done()
}
}
}(i + 1)
We use a select statement here to listen for signals from the channel.
case <-ctx.Done():
fmt.Printf("Worker %d shutting down: %v\n", workerID, ctx.Err())
return
When context is cancelled (timeout, manual cancellation, etc.), worker immediately stops and exits gracefully.
case job, ok := <-q.jobs:
if !ok {
fmt.Printf(" Job channel closed. Worker %d exiting\n", workerID)
return
}
fmt.Printf("👷 Worker %d picked a job\n", workerID)
job.ExecuteWithRetry(ctx)
q.wg.Done()
}
Worker detects channel closure and exits which prevents panic from reading closed channel. If the channel is open, job is available and context is still active, and the default processing and execution can be done. Let’s refactor this whole goroutine function and put it somewhere, and just call it from here.
func ProcessJob(ctx context.Context, q *JobQueue, workerID int)
func NewJobQueue(ctx context.Context, buffer int, workers int) *JobQueue {
q := &JobQueue{
jobs: make(chan *TrackedJob, buffer),
workers: workers,
tracker: NewJobTracker(),
}
for i := 0; i < q.workers; i++ {
go ProcessJob(ctx, q, i+1)
}
return q
}
Now let us modify our main to pass the root context.
func main() {
start := time.Now()
buffer, workers := 10, 3
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
q := job.NewJobQueue(ctx, buffer, workers)
q.Submit(&job.SleepyJob{Duration: 1 * time.Second}, 0)
q.Submit(&job.SleepyJob{Duration: 6 * time.Second}, 0)
q.Wait()
q.Shutdown()
q.StoreStatus()
fmt.Printf("\nTotal execution time: %.2fs\n", time.Since(start).Seconds())
}
We can also pass timeout in our TrackedJobs , but we would have to hardcode it, we can find a way and pass it from the top. But, let’s not go down that path for now.
We have made a minor mistake in the for loop of our ExecuteWithRetry()
for attempt := 1; attempt <= t.MaxRetries+1; attempt++ {
attemptCtx, cancel := context.WithTimeout(ctx, attemptTimeout)
defer cancel() // ❌
...
}
What’s wrong?
defer cancel() means “run cancel() when the current function exits”. But this lives inside a loop, so we are stacking cancel() calls, one for every attempt, but it won’t run until after all retries are done (after the whole function ends). So, the timeouts for earlier attempts aren't released when they’re no longer needed. As a result, we may have context leaks, memory build-up, maybe zombie goroutines if downstream uses that context.
So we will cancel as soon as possible.
attemptCtx, cancel := context.WithTimeout(ctx, attemptTimeout)
err := t.Job.Execute(attemptCtx)
cancel()
This cancels the child context right after the attempt ends, regardless of success or failure.
Right now, our workers are zombies. They do not care if the OS sends a SIGINT (Ctrl+C), or if the app is shutting down. Jobs might be halfway done or still in queue. So in our main.go, we will listen for OS signals (SIGINT, SIGTERM) and cancel the context to stop all workers. This will make our graceful shutdown complete.
ctx, cancel := context.WithCancel(context.Background())
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, os.Interrupt, syscall.SIGTERM)
go func() {
sig := <-sigChan
fmt.Printf("\nReceived signal: %s. Shutting down gracefully...\n", sig)
cancel() // Broadcast shutdown to all workers
}()
We can add this code to our main. A channel called sigChan receives signals from OS and on receiving that, our go routine in background, broadcasts shutdown to all workers. Let’s test it, by pressing ctrl+C, while a job is being executed.
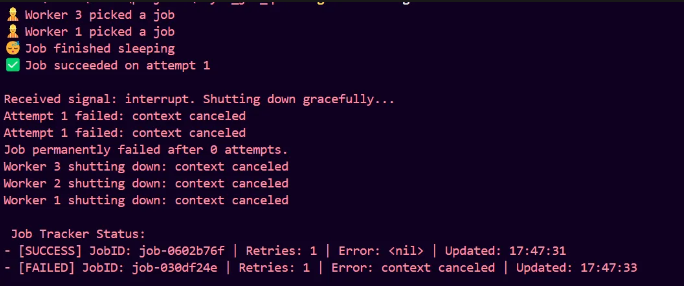
So, it works, the context gets cancelled, get broadcasted to all workers, and we see a graceful shutdown.
Let us now define a struct called SubmitOptions , to cleanly separate job configuration from job execution logic. This allows us to customize every single job.
type SubmitOptions struct {
MaxRetries int
Timeout time.Duration
Metadata map[string]string
}
Now we can update our Submit() method to take MaxRetries and Timeout from here. Also let’s add Metadata field to TrackedJobs and send it through Submit .
type TrackedJob struct {
...
Metadata map[string]string
...
}
func (q *JobQueue) Submit(job Job, opts SubmitOptions) {
q.wg.Add(1)
jobID := GenerateJobID()
func (q *JobQueue) Submit(job Job, opts SubmitOptions) {
q.wg.Add(1)
jobID := GenerateJobID()
tracked := &TrackedJob{
...
MaxRetries: opts.MaxRetries,
Timeout: opts.Timeout,
Metadata: opts.Metadata,
...
},
}
q.tracker.Register(jobID)
q.jobs <- tracked
}
Now we can pass SubmitOptions (max retries and timeout) from main.go itself. We’re doing this to cleanly separate config from behavior, unlock per-job flexibility, avoid future pain, and make the code actually readable and scalable.
q.Submit(&job.SleepyJob{Duration: 1 * time.Second}, job.SubmitOptions{
MaxRetries: 2,
Timeout: 4 * time.Second,
})
q.Submit(&job.SleepyJob{Duration: 6 * time.Second}, job.SubmitOptions{
MaxRetries: 0,
})
I think, it is the perfect time now for us to design a persistence layer
Let’s write out JobPersister interface.
type JobPersister interface {
SaveJob(job *job.TrackedJob) error
UpdateStatus(jobID string, status job.JobStatus, retry int, err error) error
LoadPendingJobs() ([]*job.TrackedJob, error)
}
This forces any persister implementation to implement the methods for saving jobs to our store, updating job status and fetching pending jobs from the store. We will first write out a simple JSON persister to see how the persistence might work. Our core job queue system shouldn’t care how data is saved , only that it is saved. We will follow our JSON implementation with a SQLite persistence layer for ACID-compliant durability and fast querying/resuming.
With all that in our mind, let’s build the json_persister.go .
Let’s start by writing the JSONPersister struct, it will have a dir field (where the json files will live) and a mutex for exclusive writes.
type JSONPersister struct {
dir string
mu sync.Mutex
}
We will write out a constructor like this.
func NewJSONPersister(dir string) *JSONPersister {
if err := os.MkdirAll(dir, os.ModePerm); err != nil {
panic(fmt.Sprintf("Failed to create job directory: %v", err))
}
return &JSONPersister{dir: dir}
}
Note:
os.MkdirAll(dir, os.ModePerm): Creates the directory and all parent directories if they don't exist
os.ModePerm: Sets full permissions (0777) - read, write, execute for owner, group, and others
Now we can implement the three methods forced by our JobPersister interface.
func (p *JSONPersister) SaveJob(job *job.TrackedJob) error {
p.mu.Lock()
defer p.mu.Unlock()
filePath := filepath.Join(p.dir, fmt.Sprintf("%s.json", job.JobID))
data, err := json.MarshalIndent(job, "", " ")
if err != nil {
return fmt.Errorf("failed to marshal job: %w", err)
}
if err := os.WriteFile(filePath, data, 0644); err != nil {
return fmt.Errorf("failed to write job file: %w", err)
}
return nil
}
In our SaveJobs method, we use mutex to prevent concurrent write conflicts. We create a dedicated file for our job with {JobID}.json and save human-readable, indented JSON format into that filepath.
Let’s move and spin up our UpdateStatus Method. Here we will just unmarshal the json into our TrackedJob struct, change the status, retry count and last error, then again save it. Below is the implementation.
func (p *JSONPersister) UpdateStatus(jobID string, status job.JobStatus, retry int, lastErr error) error {
p.mu.Lock()
defer p.mu.Unlock()
filePath := filepath.Join(p.dir, fmt.Sprintf("%s.json", jobID))
data, err := os.ReadFile(filePath)
if err != nil {
return fmt.Errorf("couldn't read job file: %w", err)
}
var j job.TrackedJob
if err := json.Unmarshal(data, &j); err != nil {
return fmt.Errorf("unmarshal error: %w", err)
}
j.Status = status
j.RetryCount = retry
j.LastError = lastErr
return p.SaveJob(&j)
}
Let’s load the jobs now. We will read the files from our dir, skipping if the file is a directory itself or if it is corrupted. Unmarshal the data and load it to our trackedJob struct, we will make an array of these trackedJob structs and put the trackedJob in it if the status is pending or failed and return the array.
func (p *JSONPersister) LoadPendingJobs() ([]*job.TrackedJob, error) {
p.mu.Lock()
defer p.mu.Unlock()
p.mu.Lock()
defer p.mu.Unlock()
var jobs []*job.TrackedJob
files, err := os.ReadDir(p.dir)
if err != nil {
return nil, fmt.Errorf("read dir error: %w", err)
}
for _, file := range files {
if file.IsDir() {
continue
}
path := filepath.Join(p.dir, file.Name())
data, err := os.ReadFile(path)
if err != nil {
continue // skip corrupted files
}
var j job.TrackedJob
if err := json.Unmarshal(data, &j); err != nil {
continue
}
if j.Status == job.StatusPending || j.Status == job.StatusFailed {
jobs = append(jobs, &j)
}
}
return jobs, nil
}
With all this, the JSONPersister looks good. Let’s go ahead and plug it with our existing JobQueue.
type JobQueue struct {
jobs chan *TrackedJob
workers int
wg sync.WaitGroup
tracker *JobTracker
persister persister.JobPersister
}
We can plug the persister, but we get an error while importing this persister “import cycle not allowed”. It is because persister is using stuff from our job package like TrackedJobs, JobStatus etc and job package wants to use persister. Let us put TrackedJobs and other stuff in different packages.
Actually, just let me separate all the concerns now itself to avoid any such cyclic dependency in future. You can check out the github repo for reference.
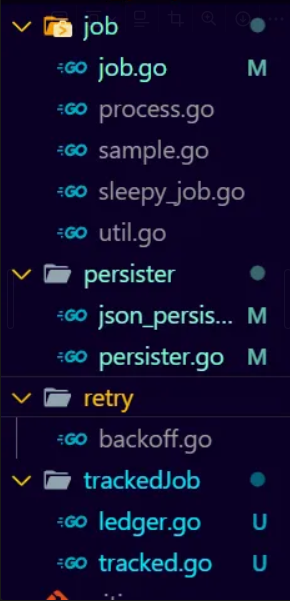
This is how it looks right now. It is a dag now Job → Persister → TrackedJob Job → TrackedJob Job has our jobqueue related stuff and TrackedJob has our main Job interface and everything related to tracked jobs and the global ledger. We must make sure that we never introduce cyclic dependencies between our packages.
Now the error goes away, and we can continue with plugging the persister in our JobQueue.
In our Submit() function for JobQueue, we will persist the job when it is submitted.
//persist the job
if q.persister != nil {
if err := q.persister.SaveJob(tracked); err != nil {
log.Printf("Failed to persist job %s: %v", jobID, err)
}
}
Next we will Update the job in the ExecuteWithRetry() function
But it will create a dependency cycle again, so we make a hook for this update.
Add this to the TrackedJob struct.
OnStatusUpdate func(jobID string, status JobStatus, retry int, err error)
To hook up OnStatusUpdate cleanly, pass a callback function from JobQueue to the TrackedJobThat callback will usually be a method on JobQueue that does callsq.persister.UpdateStatus(...)
So let’s write the following method on JobQueue
func (q *JobQueue) handleStatusUpdate(jobID string, status trackedjob.JobStatus, retry int, err error) {
if q.tracker != nil {
q.tracker.Update(jobID, status, retry, err)
}
if q.persister != nil {
saveErr := q.persister.UpdateStatus(jobID, status, retry, err)
if saveErr != nil {
log.Printf("Persistence update failed for job %s: %v", jobID, saveErr)
}
}
}
Now in the Submit(), we can allow the OnStatusUpdate field of TrackedJob to be the above method.
tracked := &trackedjob.TrackedJob{
...
OnStatusUpdate: q.handleStatusUpdate,
...
}
Now we can define an update status function on TrackedJob struct to do all the updates.
func (t *TrackedJob) updateStatus(status JobStatus, attempt int, err error) {
t.mu.Lock()
t.Status = status
t.RetryCount = attempt
t.LastError = err
t.mu.Unlock()
if t.OnStatusUpdate != nil {
t.OnStatusUpdate(t.JobID, status, attempt, err)
}
}
And plug in this to our ExecuteWithRetry method.
func (t *TrackedJob) ExecuteWithRetry(ctx context.Context) {
t.updateStatus(StatusRunning, 0, nil)
for attempt := 1; attempt <= t.MaxRetries+1; attempt++ {
// Derive a child context with timeout for this attempt
attemptTimeout := t.Timeout
if attemptTimeout == 0 {
attemptTimeout = 5 * time.Second // default fallback
}
attemptCtx, cancel := context.WithTimeout(ctx, attemptTimeout)
err := t.Job.Execute(attemptCtx)
cancel()
if err != nil {
t.updateStatus(StatusFailed, attempt, err)
if errors.Is(err, context.DeadlineExceeded) {
fmt.Printf("Job attempt %d timed out\n", attempt)
} else {
fmt.Printf("Attempt %d failed: %v\n", attempt, err)
}
fmt.Printf("Attempt %d failed: %v\n", attempt, err)
if attempt <= t.MaxRetries {
delay := t.Backoff.NextDelay(attempt)
fmt.Printf("Retrying job (attempt %d)...\n", attempt+1)
time.Sleep(delay) // backoff delay
continue
} else {
fmt.Printf("Job permanently failed after %d attempts.\n", attempt-1)
return
}
} else {
t.updateStatus(StatusSuccess, attempt, nil)
fmt.Printf("✅ Job succeeded on attempt %d\n", attempt)
return
}
}
}
We can also abstract out other stuff from this function to make it look shorter but that is unnecessary for now. The only thing left now is to plug in LoadPendingJobs . The idea is to load these jobs as soon as we start our thing.
func (q *JobQueue) LoadPersistedJobs() {
if q.persister == nil {
return
}
jobs, err := q.persister.LoadPendingJobs()
if err != nil {
log.Printf("Failed to load persisted jobs: %v", err)
return
}
for _, j := range jobs {
log.Printf("Re-queuing persisted jobs: %s", j.JobID)
q.wg.Add(1)
q.jobs <- j
}
}
We simply wrap our LoadPendingJobs() into this method on JobQueue, then we feed these jobs to our jobs channel. We will just put this in our main to load the jobs. Also in the constructor for our queue, let us pass in a persister, so that we can initialize the queue with a persister of our choice (JSONpersister for now).
func NewJobQueue(ctx context.Context, buffer int, workers int, persister persister.JobPersister) *JobQueue {
q := &JobQueue{
jobs: make(chan *trackedjob.TrackedJob, buffer),
workers: workers,
tracker: trackedjob.NewJobTracker(),
persister: persister,
}
for i := 0; i < q.workers; i++ {
go ProcessJob(ctx, q, i+1)
}
return q
}
Our main function should be like this now.
func main() {
start := time.Now()
buffer, workers := 10, 3
ctx, cancel := context.WithCancel(context.Background())
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, os.Interrupt, syscall.SIGTERM)
go func() {
sig := <-sigChan
fmt.Printf("\nReceived signal: %s. Shutting down gracefully...\n", sig)
cancel() // Broadcast shutdown to all workers
}()
persister := persister.NewJSONPersister("saved_jobs")
q := job.NewJobQueue(ctx, buffer, workers, persister)
q.LoadPersistedJobs()
q.Submit(&job.SleepyJob{Duration: 1 * time.Second}, job.SubmitOptions{
MaxRetries: 2,
Timeout: 4 * time.Second,
})
q.Submit(&job.SleepyJob{Duration: 6 * time.Second}, job.SubmitOptions{
MaxRetries: 0,
})
q.Wait()
q.Shutdown()
q.StoreStatus()
fmt.Printf("\nTotal execution time: %.2fs\n", time.Since(start).Seconds())
}
If we try to run now, it fails because the OnStatusUpdate field in the TrackedJob struct cannot be serialized, we can put a json tag to ignore this field.
OnStatusUpdate func(jobID string, status JobStatus, retry int, err error) `json:"-"`
We can do the same for Job (interface) and the mutex. But there is an issue, rather a big one. We can persist the data related to jobs, but how do we persist the behavior like the interface, mutex, function?
We are trying to serialize the behavior as well. And that won’t work, even if we ignore Job interface or others from getting serialized, where will we derive the behavior from on rehydration? Let’s step a bit back and redesign our architecture.
What we are going to do is to implement something called factory pattern for job persistence and restoration.
Before that, there’s another mistake we did before. In the original code, both SaveJob and UpdateStatus would lock the same mutex. However, UpdateStatus would then call SaveJob while it was still holding the lock.
This created a deadlock scenario:
UpdateStatusacquires the lock.UpdateStatusdoes its work and then callsSaveJob.SaveJobtries to acquire the same lock, which is already held byUpdateStatus.The program freezes, as
SaveJobwaits forever for a lock that will never be released.
To solve this, we introduce a new method, saveJob (with a lowercase 's'), which contains the core logic for writing a job to a file but does not lock the mutex.
We plug this saveJob into the UpdateStatus Now, we are ready to write our factory.go
This is the heart of the solution for turning data back into behavior. Since we can't store the actual code for a SleepyJob (say) in a JSON file, we need a way to say, "this data belongs to a SleepyJob, please create one for me."
type JobCreator func(config json.RawMessage) (trackedjob.Job, error)
This is the "recipe" for creating a single, specific type of job. The config parameter contains the job's unique data (like the Duration for a SleepyJob), and the function's job is to use that data to construct the actual job object.
Now we need a JobFactory struct. This is the main struct, the factory itself. It holds a single field: a map.
The
keyis a string which is the unique name for a job type (e.g.,"SleepyJob").The
valueis theJobCreatorfunction, the "recipe" that knows how to build that specific job.
type JobFactory struct {
creators map[string]JobCreator
}
func NewJobFactory() *JobFactory {
return &JobFactory{
creators: make(map[string]JobCreator),
}
}
A register function is needed to register the job type.
func (f *JobFactory) Register(jobType string, creator JobCreator) {
f.creators[jobType] = creator
}
And to finally create a job
func (f *JobFactory) Create(jobType string, config json.RawMessage) (trackedjob.Job, error) {
creator, ok := f.creators[jobType]
if !ok {
return nil, fmt.Errorf("no creator registered for job type: %s", jobType)
}
return creator(config)
}
We will use it like this : When LoadPersistedJobs reads a job file, it gets the JobType string and the JobData. It passes these to this Create method.
It looks up the
jobTypestring in itscreatorsmap.If it finds a corresponding
JobCreatorfunction, it executes that function, passing it the config data.It returns the newly created job object, ready to be executed.
If it can't find a creator for the given
jobType, it returns an error, preventing the program from crashing.
Now, our factory is ready, let’s plug it in our existing architecture.
We update our TrackedJob struct first.
type TrackedJob struct {
JobID string `json:"job_id"`
JobType string `json:"job_type"`
JobData json.RawMessage `json:"job_data"`
Job Job `json:"-"`
RetryCount int `json:"retry_count"`
MaxRetries int `json:"max_retries"`
Status JobStatus `json:"status"`
Metadata map[string]string `json:"metadata"`
LastError string `json:"last_error"`
Tracker *JobTracker `json:"-"`
Backoff retry.BackoffStrategy `json:"-"`
Timeout time.Duration
mu sync.Mutex `json:"-"`
OnStatusUpdate func(jobID string, status JobStatus, retry int, err error) `json:"-"`
}
JobType(e.g.,"SleepyJob") is the string key we use to look up the correct creator in theJobFactory.JobData(json.RawMessage) is a flexible way to hold the specific configuration for that job (e.g., theDurationfor aSleepyJob). It's a byte slice, so the persister doesn't need to understand its contents.
And we change our main Job interface
type Job interface {
Execute(ctx context.Context) error
TypeName() string
Serialize() (json.RawMessage, error)
}
TypeName()forces each job to declare its own identifier, which is used for theJobTypefield.Serialize()forces each job to know how to turn its own configuration into a JSON byte slice (JobData). This is a much more scalable design, as each job manages its own data.
Now we can update Submit and LoadPersistedJobs.
When a new job is submitted, it's no longer enough to just put it in the queue. We now need to prepare it for persistence before it even starts running.
It calls job.TypeName() and job.Serialize() to get the job's type and data.
It populates the
JobTypeandJobDatafields in the TrackedJob.This fully-populated TrackedJob is then saved by the persister.
func (q *JobQueue) Submit(job trackedjob.Job, opts SubmitOptions) {
q.wg.Add(1)
jobID := GenerateJobID()
jobData, err := job.Serialize() //here
if err != nil {
log.Printf("Failed to serialize job %s: %v", jobID, err)
q.wg.Done()
return
}
tracked := &trackedjob.TrackedJob{
JobID: jobID,
JobType: job.TypeName(), //here
JobData: jobData,
Job: job,
MaxRetries: opts.MaxRetries,
Timeout: opts.Timeout,
Status: trackedjob.StatusPending,
Metadata: opts.Metadata,
OnStatusUpdate: q.handleStatusUpdate,
Tracker: q.tracker,
Backoff: retry.ExponentialBackoff{
BaseDelay: 500 * time.Millisecond,
MaxDelay: 5 * time.Second,
Jitter: true,
},
}
q.tracker.Register(jobID)
//persist the job
if q.persister != nil {
if err := q.persister.SaveJob(tracked); err != nil {
log.Printf("Failed to persist job %s: %v", jobID, err)
}
}
q.jobs <- tracked
}
LoadPersistedJobs: This is the reverse process.
It fetches the raw TrackedJob data from the persister.
It uses the job.JobType and job.JobData along with the
JobFactoryto re-create the correct job object (e.g., a newSleepyJob).Crucially, it then re-hydrates the TrackedJob by restoring the fields that couldn't be persisted: the Job interface itself, the
OnStatusUpdatecallback, theTracker, and theBackoffstrategy.
func (q *JobQueue) LoadPersistedJobs(factory *JobFactory) {
if q.persister == nil {
return
}
jobs, err := q.persister.LoadPendingJobs()
if err != nil {
log.Printf("Failed to load persisted jobs: %v", err)
return
}
for _, j := range jobs {
rehydratedJob, err := factory.Create(j.JobType, j.JobData) //here
if err != nil {
log.Printf("Failed to rehydrate job %s of type %s: %v", j.JobID, j.JobType, err)
continue
}
//Putting in the behavior
j.Job = rehydratedJob
j.OnStatusUpdate = q.handleStatusUpdate
j.Tracker = q.tracker
j.Backoff = retry.ExponentialBackoff{
BaseDelay: 500 * time.Millisecond,
MaxDelay: 5 * time.Second,
Jitter: true,
}
log.Printf("Re-queuing persisted jobs: %s", j.JobID)
q.wg.Add(1)
q.jobs <- j
}
}
Now let us implement the Type and Serialize methods on SleepyJob.
func (j *SleepyJob) TypeName() string {
return "SleepyJob"
}
func (j *SleepyJob) Serialize() (json.RawMessage, error) {
return json.Marshal(j)
}
This is how we implement the factory pattern. Below is the new main
func main() {
start := time.Now()
buffer, workers := 10, 3
ctx, cancel := context.WithCancel(context.Background())
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, os.Interrupt, syscall.SIGTERM)
go func() {
sig := <-sigChan
fmt.Printf("\nReceived signal: %s. Shutting down gracefully...\n", sig)
cancel() // Broadcast shutdown to all workers
}()
persister := persister.NewJSONPersister("saved_jobs")
jobFactory := job.NewJobFactory()
jobFactory.Register("SleepyJob", func(config json.RawMessage) (trackedjob.Job, error) {
var sj job.SleepyJob
if err := json.Unmarshal(config, &sj); err != nil {
return nil, err //Duration field of SleepyJob is unmarshalled and stored in JobData
}
return &sj, nil
})
q := job.NewJobQueue(ctx, buffer, workers, persister)
q.LoadPersistedJobs(jobFactory)
q.Submit(&job.SleepyJob{Duration: 1 * time.Second}, job.SubmitOptions{
MaxRetries: 2,
Timeout: 4 * time.Second,
})
q.Submit(&job.SleepyJob{Duration: 6 * time.Second}, job.SubmitOptions{
MaxRetries: 0,
Timeout: 10 * time.Second,
})
q.Wait()
q.Shutdown()
q.StoreStatus()
fmt.Printf("\nTotal execution time: %.2fs\n", time.Since(start).Seconds())
}
Now if we run it, our jobs persist. If we try to stop while a job is executing and restart, the job is loaded and finished. See the screenshots below.
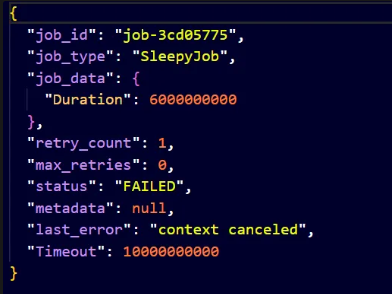
On restarting, (comment out the previous submits)

I think the global ledger is not necessary now, because we have already got our persistence in place, so we remove it. We can implement the SQLite implementation similarly, and then it will be just plug-n-play. You can check that out in the repo.
And yeah, I think that’s it for this one. We didn’t include circuit breakers, DLQ, or API wrappers here because the goal was to build a solid, minimal core. Those features are valuable, but they deserve their own thoughtful design, and we’ll be treating this project like a product, not just a demo. So we’re keeping it clean, focused, and ready for whatever comes next.
Subscribe to my newsletter
Read articles from Yashaswi Kumar Mishra directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by