End To End Paper Implementation “Attention Is All You Need”
 Ramazan Turan
Ramazan TuranIn this article, I present an end-to-end implementation of the paper “Attention is All You Need”, along with selected quotes from the paper.
This article focuses only on implementation. For a more explanatory and conceptual guide, I recommend the following YouTube video: https://www.youtube.com/watch?v=KJtZARuO3JY
Detailed Implementation
Components
Encoder
Decoder
Attention Mechanisms
Self-Attention (Encoder)
Masked Self-Attention (Decoder)
Position-wise Feed-Forward Networks
Layer Normalization
Positional Encoding
Embedding and Output Layers
Input Embedding
Architecture
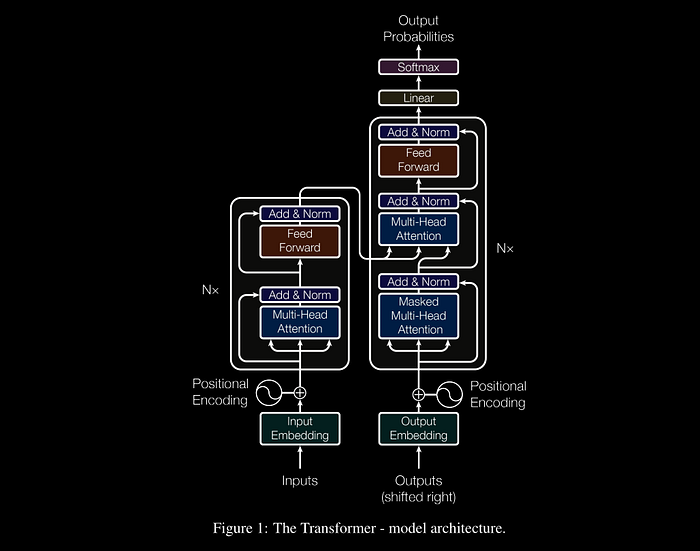
Encoder
Quote: “The encoder is composed of a stack of N = 6 identical layers*. Each layer has two sub-layers. The first is a* multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network. We employ a residual connection around each of the two sub-layers, followed by layer normalization*. That is, the output of eac*h sub-layer is LayerNorm(x + Sublayer(x)), where Sublayer(x) is the function implemented by the sub-layer itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel = 512.*”*
Positional Encoding
class PositionalEncoding(nn.Module):
"""
Adds positional encoding to the token embeddings for the Transformer model
Paper Reference: Section 3.5 "Positional Encoding"
Described in Equations 5 and 6.
"""
def __init__(self, d_model, max_len=5000, dropout=0.1):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Positional encoding calculation
# Paper Reference: Section 3.5, Equations 5 and 6
# PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
# PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # Sine for even indices
pe[:, 1::2] = torch.cos(position * div_term) # Cosine for odd indices
pe = pe.unsqueeze(0).transpose(0, 1) # [max_len, 1, d_model]
# Register as a persistent buffer (not a model parameter)
self.register_buffer('pe', pe)
def forward(self, x):
"""
Args:
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
Multi-Head Self-Attention
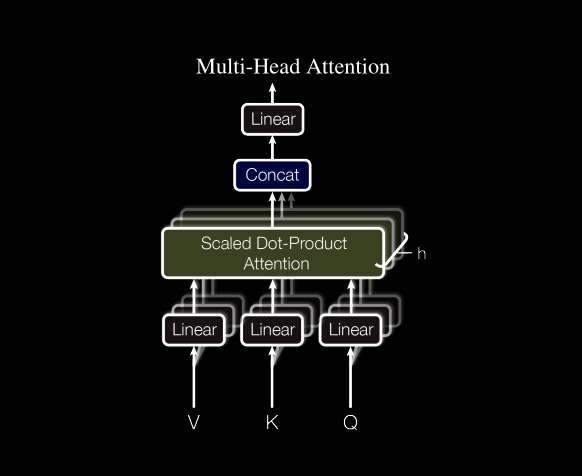
class MultiHeadAttention(nn.Module):
"""
Multi-Head Attention mechanism
Paper Reference: Section 3.2.2 "Multi-Head Attention"
Described in Equations 1 and 2.
Structure is shown on the left side of Figure 2 in the paper.
"""
def __init__(self, d_model, n_head, dropout=0.1):
super(MultiHeadAttention, self).__init__()
assert d_model % n_head == 0
self.d_model = d_model
self.n_head = n_head
self.d_k = d_model // n_head
# Linear projections
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
self.fc = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
"""
Args:
query: [batch_size, seq_len_q, d_model]
key: [batch_size, seq_len_k, d_model]
value: [batch_size, seq_len_v, d_model]
mask: [batch_size, seq_len_q, seq_len_k] or [batch_size, 1, seq_len_q, seq_len_k]
Paper Reference: Sections 3.2.1 and 3.2.2
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V
MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O
head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)
"""
batch_size = query.size(0)
# Linear projections and head separation
# [batch_size, seq_len, n_head, d_k]
q = self.wq(query).view(batch_size, -1, self.n_head, self.d_k).transpose(1, 2)
k = self.wk(key).view(batch_size, -1, self.n_head, self.d_k).transpose(1, 2)
v = self.wv(value).view(batch_size, -1, self.n_head, self.d_k).transpose(1, 2)
# Scaled Dot-Product Attention calculation
# Paper Reference: Section 3.2.1, Equation 1
# Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
# Masking (optional)
if mask is not None:
# Handle different mask dimensions
if mask.dim() == 3: # [batch_size, seq_len_q, seq_len_k]
mask = mask.unsqueeze(1) # [batch_size, 1, seq_len_q, seq_len_k]
elif mask.dim() == 4: # [batch_size, 1, seq_len_q, seq_len_k]
pass # Already correct dimension
# Expand mask for all heads
mask = mask.expand(batch_size, self.n_head, -1, -1)
scores = scores.masked_fill(mask == 0, -1e9)
# Softmax and Dropout
attn = F.softmax(scores, dim=-1)
attn = self.dropout(attn)
# Output calculation
out = torch.matmul(attn, v) # [batch_size, n_head, seq_len_q, d_k]
out = out.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
out = self.fc(out)
return out
Positional Feed-Forward
class PositionwiseFeedForward(nn.Module):
"""
Two-layer Feed-Forward Network
Paper Reference: Section 3.3 "Position-wise Feed-Forward Networks"
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂
Described in Equation 2.
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""
Args:
x: [batch_size, seq_len, d_model]
"""
return self.fc2(self.dropout(F.relu(self.fc1(x))))
Encoder Layer
class EncoderLayer(nn.Module):
"""
Transformer Encoder Layer
Paper Reference: Section 3.1 "Encoder and Decoder Stacks" - Encoder part
Structure shown on the left side of Figure 1.
Each encoder layer has a multi-head self-attention and a feed-forward network.
Each sublayer has a residual connection and layer normalization.
"""
def __init__(self, d_model, n_head, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, n_head, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
"""
Quote: "We apply dropout [33] to the output of each sub-layer, before it is
added to the sub-layer input and normalized"
Section: 5.4 Regularization
"""
def forward(self, x, mask=None):
"""
Args:
x: [batch_size, seq_len, d_model]
mask: [batch_size, seq_len, seq_len]
Paper Reference: Section 3.1, "Sublayer Connection"
For each sublayer: LayerNorm(x + Sublayer(x))
"""
# First sublayer: Multi-Head Self-Attention
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout1(attn_output)) # Residual connection + LayerNorm
# Second sublayer: Position-wise Feed-Forward Network
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout2(ff_output)) # Residual connection + LayerNorm
Encoder
class Encoder(nn.Module):
"""
Transformer Encoder
Paper Reference: Section 3.1 "Encoder and Decoder Stacks"
The encoder consists of N=6 identical encoder layers.
First applies token embedding and positional encoding.
"""
def __init__(self, vocab_size, d_model, n_head, d_ff, n_layers, dropout=0.1, max_len=5000):
super(Encoder, self).__init__()
# Paper Reference: Section 3.4, "Embeddings and Softmax"
# "We multiply those weights by sqrt(d_model)"
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, max_len, dropout)
self.layers = nn.ModuleList([
EncoderLayer(d_model, n_head, d_ff, dropout) for _ in range(n_layers)
])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
"""
Args:
x: [batch_size, src_seq_len]
mask: [batch_size, src_seq_len, src_seq_len]
Paper Reference: Section 3.1 "Encoder"
The encoder consists of N identical encoder layers.
"""
# Embedding and Positional Encoding
# Paper Reference: Section 3.4, "We multiply those weights by sqrt(d_model)"
x = self.embedding(x) * math.sqrt(self.embedding.embedding_dim)
x = self.pos_encoding(x)
for layer in self.layers:
x = layer(x, mask)
x = self.norm(x)
return x
Decoder
Quote: “The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. We also modify the self-attention sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.”
Decoder Layer
class DecoderLayer(nn.Module):
"""
Transformer Decoder Layer
Paper Reference: Section 3.1 "Encoder and Decoder Stacks" - Decoder part
Structure shown on the right side of Figure 1.
Each decoder layer has a masked multi-head self-attention,
a multi-head cross-attention, and a feed-forward network.
Each sublayer has a residual connection and layer normalization.
"""
def __init__(self, d_model, n_head, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, n_head, dropout)
self.cross_attn = MultiHeadAttention(d_model, n_head, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, enc_output, self_mask=None, cross_mask=None):
"""
Args:
x: [batch_size, seq_len, d_model]
enc_output: [batch_size, src_seq_len, d_model]
self_mask: [batch_size, seq_len, seq_len]
cross_mask: [batch_size, seq_len, src_seq_len]
Paper Reference: Section 3.1, "Decoder"
The decoder has masked multi-head attention, multi-head attention, and
feed-forward network sublayers.
For each sublayer: LayerNorm(x + Sublayer(x))
"""
attn_output = self.self_attn(x, x, x, self_mask)
x = self.norm1(x + self.dropout1(attn_output)) # Residual connection + LayerNorm
# Sublayer with Cross-Attention (Decoder attends to encoder output)
attn_output = self.cross_attn(x, enc_output, enc_output, cross_mask)
x = self.norm2(x + self.dropout2(attn_output)) # Residual connection + LayerNorm
# Sublayer with Feed-Forward Network
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout3(ff_output)) # Residual connection + LayerNorm
return x
Decoder
class Decoder(nn.Module):
"""
Transformer Decoder
Paper Reference: Section 3.1 "Encoder and Decoder Stacks"
The decoder consists of N=6 identical decoder layers.
Like the encoder, it first applies token embedding and positional encoding.
The decoder also uses masking for subsequent positions (section 3.2.3).
"""
def __init__(self, vocab_size, d_model, n_head, d_ff, n_layers, dropout=0.1, max_len=5000):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, max_len, dropout)
self.layers = nn.ModuleList([
DecoderLayer(d_model, n_head, d_ff, dropout) for _ in range(n_layers)
])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, enc_output, self_mask=None, cross_mask=None):
"""
Args:
x: [batch_size, tgt_seq_len]
enc_output: [batch_size, src_seq_len, d_model]
self_mask: [batch_size, tgt_seq_len, tgt_seq_len] or [batch_size, 1, tgt_seq_len, tgt_seq_len]
cross_mask: [batch_size, tgt_seq_len, src_seq_len] or [batch_size, 1, tgt_seq_len, src_seq_len]
"""
# Embedding and Positional Encoding
x = self.embedding(x) * math.sqrt(self.embedding.embedding_dim)
x = self.pos_encoding(x)
# Pass through decoder layers
for layer in self.layers:
x = layer(x, enc_output, self_mask, cross_mask)
x = self.norm(x)
return x
Transformer Model
class Transformer(nn.Module):
"""
Transformer model (Attention is All You Need)
Paper Reference: The entire paper, especially Section 3 and Figure 1
The Transformer consists of an encoder and a decoder.
The output projection converts decoder output to target word distributions.
"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, n_head=8,
d_ff=2048, n_layers=6, dropout=0.1, max_len=5000):
super(Transformer, self).__init__()
# Paper Reference: Section 3.1 and Table 1
# Base model: d_model=512, n_head=8, d_ff=2048, n_layers=6, dropout=0.1
self.encoder = Encoder(src_vocab_size, d_model, n_head, d_ff, n_layers, dropout, max_len)
self.decoder = Decoder(tgt_vocab_size, d_model, n_head, d_ff, n_layers, dropout, max_len)
self.projection = nn.Linear(d_model, tgt_vocab_size)
def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None):
"""
Args:
src: [batch_size, src_seq_len]
tgt: [batch_size, tgt_seq_len]
src_mask: [batch_size, src_seq_len, src_seq_len]
tgt_mask: [batch_size, tgt_seq_len, tgt_seq_len]
memory_mask: [batch_size, tgt_seq_len, src_seq_len]
Paper Reference: The entire paper, especially Figure 1
Transformer model flow:
1. Encoder takes input and produces encoder output
2. Decoder takes encoder output and its own input
3. Final projection produces target word distribution
"""
enc_output = self.encoder(src, src_mask)
dec_output = self.decoder(tgt, enc_output, tgt_mask, memory_mask)
output = self.projection(dec_output)
return output
Full Code
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class PositionalEncoding(nn.Module):
"""
Adds positional encoding to the token embeddings for the Transformer model
Paper Reference: Section 3.5 "Positional Encoding"
Described in Equations 5 and 6.
"""
def __init__(self, d_model, max_len=5000, dropout=0.1):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Positional encoding calculation
# Paper Reference: Section 3.5, Equations 5 and 6
# PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
# PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # Even indices use sine
pe[:, 1::2] = torch.cos(position * div_term) # Odd indices use cosine
pe = pe.unsqueeze(0) # [1, max_len, d_model]
# Register as persistent buffer (not a model parameter)
self.register_buffer('pe', pe)
def forward(self, x):
"""
Args:
x: [batch_size, seq_len, d_model]
"""
x = x + self.pe[:, :x.size(1), :]
return self.dropout(x)
class MultiHeadAttention(nn.Module):
"""
Multi-Head Attention mechanism
Paper Reference: Section 3.2.2 "Multi-Head Attention"
Described in Equations 1 and 2.
Structure is shown on the left side of Figure 2 in the paper.
"""
def __init__(self, d_model, n_head, dropout=0.1):
super(MultiHeadAttention, self).__init__()
assert d_model % n_head == 0
self.d_model = d_model
self.n_head = n_head
self.d_k = d_model // n_head
# Linear projections
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
self.wv = nn.Linear(d_model, d_model)
self.fc = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, mask=None):
"""
Args:
query: [batch_size, seq_len_q, d_model]
key: [batch_size, seq_len_k, d_model]
value: [batch_size, seq_len_v, d_model]
mask: [batch_size, seq_len_q, seq_len_k] or [batch_size, 1, seq_len_q, seq_len_k]
Paper Reference: Sections 3.2.1 and 3.2.2
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V
MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O
head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)
"""
batch_size = query.size(0)
# Linear projections and head separation
# [batch_size, seq_len, n_head, d_k]
q = self.wq(query).view(batch_size, -1, self.n_head, self.d_k).transpose(1, 2)
k = self.wk(key).view(batch_size, -1, self.n_head, self.d_k).transpose(1, 2)
v = self.wv(value).view(batch_size, -1, self.n_head, self.d_k).transpose(1, 2)
# Scaled Dot-Product Attention calculation
# Paper Reference: Section 3.2.1, Equation 1
# Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.d_k)
# Masking (optional)
if mask is not None:
# Handle different mask dimensions
if mask.dim() == 3: # [batch_size, seq_len_q, seq_len_k]
mask = mask.unsqueeze(1) # [batch_size, 1, seq_len_q, seq_len_k]
elif mask.dim() == 4: # [batch_size, 1, seq_len_q, seq_len_k]
pass # Already correct dimension
# Expand mask for all heads
mask = mask.expand(batch_size, self.n_head, -1, -1)
scores = scores.masked_fill(mask == 0, -1e9)
# Softmax and Dropout
attn = F.softmax(scores, dim=-1)
attn = self.dropout(attn)
# Output calculation
out = torch.matmul(attn, v) # [batch_size, n_head, seq_len_q, d_k]
out = out.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
out = self.fc(out)
return out
class PositionwiseFeedForward(nn.Module):
"""
Two-layer Feed-Forward Network
Paper Reference: Section 3.3 "Position-wise Feed-Forward Networks"
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂
Described in Equation 2.
"""
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""
Args:
x: [batch_size, seq_len, d_model]
"""
return self.fc2(self.dropout(F.relu(self.fc1(x))))
class EncoderLayer(nn.Module):
"""
Transformer Encoder Layer
Paper Reference: Section 3.1 "Encoder and Decoder Stacks" - Encoder part
Structure shown on the left side of Figure 1.
Each encoder layer has a multi-head self-attention and a feed-forward network.
Each sublayer has a residual connection and layer normalization.
"""
def __init__(self, d_model, n_head, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, n_head, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
"""
Quote: "We apply dropout [33] to the output of each sub-layer, before it is
added to thesub-layer input and normalized"
Section: 5.4 Regularization
"""
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask=None):
"""
Args:
x: [batch_size, seq_len, d_model]
mask: [batch_size, seq_len, seq_len]
Paper Reference: Section 3.1, "Sublayer Connection"
For each sublayer: LayerNorm(x + Sublayer(x))
"""
# First sublayer: Multi-Head Self-Attention
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout1(attn_output)) # Residual connection + LayerNorm
# Second sublayer: Position-wise Feed-Forward Network
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout2(ff_output)) # Residual connection + LayerNorm
class DecoderLayer(nn.Module):
"""
Transformer Decoder Layer
Paper Reference: Section 3.1 "Encoder and Decoder Stacks" - Decoder part
Structure shown on the right side of Figure 1.
Each decoder layer has a masked multi-head self-attention,
a multi-head cross-attention, and a feed-forward network.
Each sublayer has a residual connection and layer normalization.
"""
def __init__(self, d_model, n_head, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, n_head, dropout)
self.cross_attn = MultiHeadAttention(d_model, n_head, dropout)
self.feed_forward = PositionwiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, enc_output, self_mask=None, cross_mask=None):
"""
Args:
x: [batch_size, seq_len, d_model]
enc_output: [batch_size, src_seq_len, d_model]
self_mask: [batch_size, seq_len, seq_len]
cross_mask: [batch_size, seq_len, src_seq_len]
Paper Reference: Section 3.1, "Decoder"
The decoder has masked multi-head attention, multi-head attention, and
feed-forward network sublayers.
For each sublayer: LayerNorm(x + Sublayer(x))
"""
attn_output = self.self_attn(x, x, x, self_mask)
x = self.norm1(x + self.dropout1(attn_output)) # Residual connection + LayerNorm
# Sublayer with Cross-Attention (Decoder attends to encoder output)
attn_output = self.cross_attn(x, enc_output, enc_output, cross_mask)
x = self.norm2(x + self.dropout2(attn_output)) # Residual connection + LayerNorm
# Sublayer with Feed-Forward Network
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout3(ff_output)) # Residual connection + LayerNorm
return x
class Encoder(nn.Module):
"""
Transformer Encoder
Paper Reference: Section 3.1 "Encoder and Decoder Stacks"
The encoder consists of N=6 identical encoder layers.
First applies token embedding and positional encoding.
"""
def __init__(self, vocab_size, d_model, n_head, d_ff, n_layers, dropout=0.1, max_len=5000):
super(Encoder, self).__init__()
# Paper Reference: Section 3.4, "Embeddings and Softmax"
# "We multiply those weights by sqrt(d_model)"
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, max_len, dropout)
self.layers = nn.ModuleList([
EncoderLayer(d_model, n_head, d_ff, dropout) for _ in range(n_layers)
])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
"""
Args:
x: [batch_size, src_seq_len]
mask: [batch_size, src_seq_len, src_seq_len] or [batch_size, 1, src_seq_len, src_seq_len]
Paper Reference: Section 3.1 "Encoder"
The encoder consists of N identical encoder layers.
"""
# Embedding and Positional Encoding
# Paper Reference: Section 3.4, "We multiply those weights by sqrt(d_model)"
x = self.embedding(x) * math.sqrt(self.embedding.embedding_dim)
x = self.pos_encoding(x)
# Pass through encoder layers
for layer in self.layers:
x = layer(x, mask)
x = self.norm(x)
return x
class Decoder(nn.Module):
"""
Transformer Decoder
Paper Reference: Section 3.1 "Encoder and Decoder Stacks"
The decoder consists of N=6 identical decoder layers.
Like the encoder, it first applies token embedding and positional encoding.
The decoder also uses masking for subsequent positions (section 3.2.3).
"""
def __init__(self, vocab_size, d_model, n_head, d_ff, n_layers, dropout=0.1, max_len=5000):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model, max_len, dropout)
self.layers = nn.ModuleList([
DecoderLayer(d_model, n_head, d_ff, dropout) for _ in range(n_layers)
])
self.norm = nn.LayerNorm(d_model)
def forward(self, x, enc_output, self_mask=None, cross_mask=None):
"""
Args:
x: [batch_size, tgt_seq_len]
enc_output: [batch_size, src_seq_len, d_model]
self_mask: [batch_size, tgt_seq_len, tgt_seq_len] or [batch_size, 1, tgt_seq_len, tgt_seq_len]
cross_mask: [batch_size, tgt_seq_len, src_seq_len] or [batch_size, 1, tgt_seq_len, src_seq_len]
"""
# Embedding and Positional Encoding
x = self.embedding(x) * math.sqrt(self.embedding.embedding_dim)
x = self.pos_encoding(x)
# Pass through decoder layers
for layer in self.layers:
x = layer(x, enc_output, self_mask, cross_mask)
x = self.norm(x)
return x
class Transformer(nn.Module):
"""
Transformer model (Attention is All You Need)
Paper Reference: The entire paper, especially Section 3 and Figure 1
The Transformer consists of an encoder and a decoder.
The output projection converts decoder output to target word distributions.
"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, n_head=8,
d_ff=2048, n_layers=6, dropout=0.1, max_len=5000):
super(Transformer, self).__init__()
# Paper Reference: Section 3.1 and Table 1
# Base model: d_model=512, n_head=8, d_ff=2048, n_layers=6, dropout=0.1
self.encoder = Encoder(src_vocab_size, d_model, n_head, d_ff, n_layers, dropout, max_len)
self.decoder = Decoder(tgt_vocab_size, d_model, n_head, d_ff, n_layers, dropout, max_len)
self.projection = nn.Linear(d_model, tgt_vocab_size)
def forward(self, src, tgt, src_mask=None, tgt_mask=None, memory_mask=None):
"""
Args:
src: [batch_size, src_seq_len]
tgt: [batch_size, tgt_seq_len]
src_mask: [batch_size, src_seq_len, src_seq_len]
tgt_mask: [batch_size, tgt_seq_len, tgt_seq_len]
memory_mask: [batch_size, tgt_seq_len, src_seq_len]
Paper Reference: The entire paper, especially Figure 1
Transformer model flow:
1. Encoder takes input and produces encoder output
2. Decoder takes encoder output and its own input
3. Final projection produces target word distribution
"""
enc_output = self.encoder(src, src_mask)
dec_output = self.decoder(tgt, enc_output, tgt_mask, memory_mask)
output = self.projection(dec_output)
return output
def create_masks(src, tgt, pad_idx):
"""
Creates padding and subsequent masks
Paper Reference: Section 3.2.3 "Attention Masking"
Masking is applied in the decoder to prevent seeing future positions.
Masking is also applied for padding tokens.
"""
# Encoder masking (padding mask)
# src_mask: [batch_size, src_len] -> [batch_size, 1, src_len, src_len]
src_pad_mask = (src != pad_idx).unsqueeze(1).unsqueeze(1) # [B, 1, 1, src_len]
src_len = src.size(1)
src_mask = src_pad_mask.expand(-1, -1, src_len, -1) # [B, 1, src_len, src_len]
# Decoder self-attention masking (padding mask + subsequent mask)
tgt_len = tgt.size(1)
tgt_pad_mask = (tgt != pad_idx).unsqueeze(1).unsqueeze(1) # [B, 1, 1, tgt_len]
tgt_pad_mask = tgt_pad_mask.expand(-1, -1, tgt_len, -1) # [B, 1, tgt_len, tgt_len]
# Subsequent mask (lower triangular)
tgt_sub_mask = torch.tril(torch.ones((tgt_len, tgt_len), device=tgt.device)).bool()
tgt_sub_mask = tgt_sub_mask.unsqueeze(0).unsqueeze(0) # [1, 1, tgt_len, tgt_len]
tgt_mask = tgt_pad_mask & tgt_sub_mask
# Cross attention masking (encoder-decoder attention)
# memory_mask: [batch_size, tgt_len, src_len]
src_pad_mask_for_cross = (src != pad_idx).unsqueeze(1).unsqueeze(1) # [B, 1, 1, src_len]
memory_mask = src_pad_mask_for_cross.expand(-1, -1, tgt_len, -1) # [B, 1, tgt_len, src_len]
return src_mask, tgt_mask, memory_mask
# Example of model usage
def example_usage():
"""
Example usage with proper error handling
"""
try:
# Parameters
# Paper Reference: Section 3.1 and Table 1
# Base model: d_model=512, n_head=8, d_ff=2048, n_layers=6, dropout=0.1
src_vocab_size = 10000
tgt_vocab_size = 10000
d_model = 512
n_head = 8
d_ff = 2048
n_layers = 6
dropout = 0.1
pad_idx = 0
# Create model
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, n_head, d_ff, n_layers, dropout)
# Print model parameters
total_params = sum(p.numel() for p in transformer.parameters())
print(f"Total parameters: {total_params:,}")
# Example input data
src = torch.randint(1, src_vocab_size, (64, 10)) # [batch_size=64, src_seq_len=10]
tgt = torch.randint(1, tgt_vocab_size, (64, 20)) # [batch_size=64, tgt_seq_len=20]
# Create masks
src_mask, tgt_mask, memory_mask = create_masks(src, tgt, pad_idx)
print(f"Source mask shape: {src_mask.shape}")
print(f"Target mask shape: {tgt_mask.shape}")
print(f"Memory mask shape: {memory_mask.shape}")
# Forward pass
output = transformer(src, tgt, src_mask, tgt_mask, memory_mask)
print(f"Output shape: {output.shape}") # [64, 20, tgt_vocab_size]
print("Forward pass successful!")
return output
except Exception as e:
print(f"Error occurred: {str(e)}")
return None
example_usage()
Subscribe to my newsletter
Read articles from Ramazan Turan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by