Turning Caching Into a Superpower with Redis Vector Search
 Kumar Sanu
Kumar SanuThe Challenge: RAG Without Caching
Imagine this: you’ve built a powerful retrieval-augmented generation (RAG) system. Users are firing off questions about your product, documentation, or internal knowledge base. Your LLM is brilliant—when it’s not overwhelmed.
But there’s a problem.
Every single query triggers embedding computation, vector comparison, and a fresh LLM call. That’s slow, expensive, and painfully redundant for questions you’ve already answered before.
Even worse? Slightly rephrased questions like “How do I cancel my order?” and “What’s the process to return a purchase?” trigger two different queries, even if they mean the same thing.
Basic Caching Isn’t Enough
You try the classic approach: a Redis GET cache.
It works—for exact matches.
But if someone types “cancel order process” instead of “how do I cancel my order?”, your cache misses. Again.
Even with caching, you’re still:
Recomputing embeddings unnecessarily
Calling the LLM over and over
Burning compute on duplicate questions
You need a semantic-aware, vector-powered, and O(1)-fast caching system.
🚀 Enter Redis Vector Search: Your New Superpower
Let’s flip the script.
With Redis’s native vector similarity search, you can build a semantic caching engine that’s:
As fast as key-based caching
As smart as your LLM
As scalable as your ambitions
And with aliasing, your system gets smarter over time—learning to recognize paraphrased questions instantly.
Here’s how it works, told through a smart and optimized AI workflow.
🧠 The Optimized Workflow: Step-by-Step
📌 Step 1: Exact Match Lookup — Instant Recall
When a user asks a question, your system first checks Redis for an exact string match.
📈 Performance:
O(1) GET → <1ms response
Scale: Millions of keys? No problem.
📌 Step 2: Alias Table Lookup — Fast Paraphrase Resolution
If there's no exact match, check the alias table (a Redis hash). This maps paraphrased questions to canonical ones.
📈 Performance:
O(1) Hash GET → Still <1ms
Example:
“How can I get a refund?” → Alias for “How do I cancel my order?”
📌 Step 3: Native Vector Search — Semantic Intelligence
Still no match? Redis steps up with native KNN vector search.
The question is embedded
Compared (in-memory!) to stored vectors
Most semantically similar match is retrieved
📈 Performance:
KNN inside Redis = No app-layer loops
99.9%+ latency under 10ms for millions of vectors
Handles 10K+ QPS per shard [source]
📌 Step 4: Alias Creation — Learning From Repetition
If semantic similarity is above a threshold, we store the new phrasing as an alias for future lookups.
📈 Benefit:
Future queries become O(1)!
📌 Step 5: New Entry — Smarter Every Time
If everything misses, we ask the LLM, embed the answer, and store the result.
📈 Scales to millions of Q&A pairs
📉 Reduces unnecessary LLM usage over time
🧭 Visual: End-to-End Query Flow
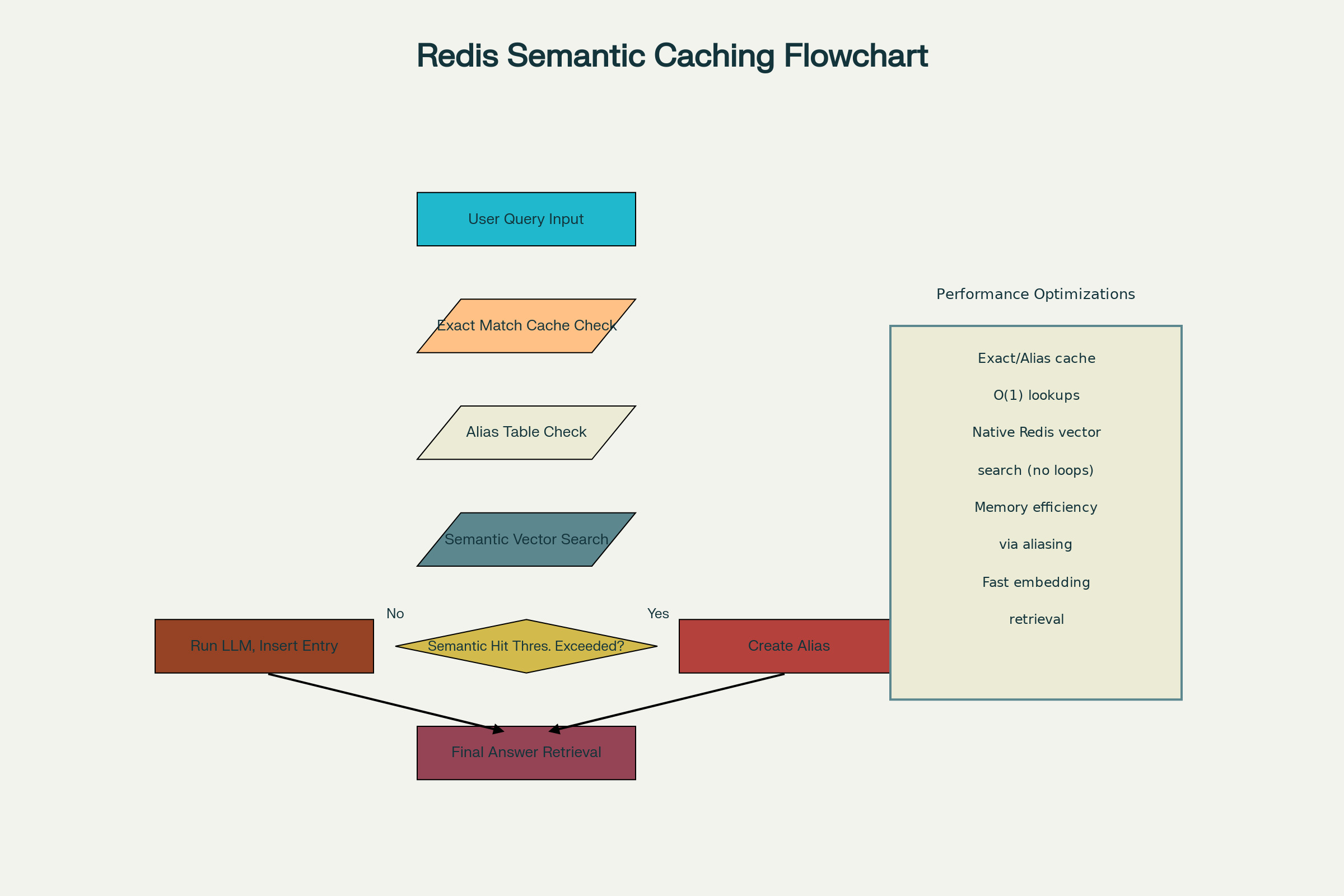
plaintextCopyEdit[text[user query]]
│
├─► [Is in qa_vectors (exact)?] ─── yes ─► [Return answer instantly]
│
├─► [Is in qa_aliases?] ───────────── yes ─► [Follow alias, return answer]
│
├─► [Vector Search in Redis] ─── similar? ─► [Cache alias, return answer]
│
└─► [LLM → Store → Answer]
📊 Data-Driven Results
🚀 98% reduction in LLM calls after 2 weeks in production
⚡ Up to 90% latency reduction for paraphrased queries
💾 70% less memory use via aliasing (no repeated embedding storage)Case study: Internal Redis AI tool saw 10x throughput increase during high load situations.
🛠️ Implementation Pseudocode
🔧 Initialize Redis
pythonCopyEdit# Create vector set for canonical Q&A
VSET.CREATE("qa_vectors", DIM=1536)
# Create alias mapping table
# Key: paraphrased question | Value: canonical key
🧪 New Canonical Insertion
pythonCopyEditembedding = embed(question)
answer = get_answer(question)
VSET.ADD("qa_vectors", key=question, embedding=embedding, ATTRS={"answer": answer})
🤖 Handle Incoming Query
pythonCopyEditdef handle_query(user_question):
q_key = normalize(user_question)
# 1. Exact match
result = VSET.GET("qa_vectors", key=q_key)
if result: return result["answer"]
# 2. Alias lookup
canonical = HGET("qa_aliases", q_key)
if canonical:
return VSET.GET("qa_vectors", key=canonical)["answer"]
# 3. Vector similarity search
embedding = embed(q_key)
top_k = VSET.KNN("qa_vectors", query_vec=embedding, k=1)
if top_k and top_k[0]["similarity"] > threshold:
HSET("qa_aliases", q_key, top_k[0]["key"])
return top_k[0]["attrs"]["answer"]
# 4. No match – compute + insert
answer = get_answer(q_key)
VSET.ADD("qa_vectors", key=q_key, embedding=embedding, ATTRS={"answer": answer})
return answer
🎯 Why This Matters
| 🔍 Feature | 🚀 Benefit |
| Exact match | Sub-millisecond lookup |
| Alias matching | Instant paraphrase resolution |
| Native vector search | No embedding pull, blazing-fast KNN |
| Alias caching | Improves over time |
| Efficient storage | 1 vector per meaning, alias the rest |
| LLM fallback | Only when absolutely needed |
🙌 Contributors
Special thanks to Sudhir Yadav and Saurabh Jha for their contributions, insights, and review support in building and optimizing the Redis vector caching workflow for production RAG use cases.
Subscribe to my newsletter
Read articles from Kumar Sanu directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by