Kimi K2 vs Grok 4: Open-Source Challenger vs Premium Powerhouse
 Mrunmay Shelar
Mrunmay Shelar
Choosing the right large-language model (LLM) has moved beyond “GPT-4o or bust.” In 2025, Kimi K2 (Moonshot AI) and Grok 4 (xAI) give developers two very different yet highly capable options: an open-source trillion-parameter Mixture-of-Experts model on one side and a premium, real-time, multi-agent powerhouse on the other. This article walks through their architectures, benchmark results, practical use cases, and how you can access both through LangDB AI gateway.
TL;DR:
In a nutshell, Kimi K2 is an open-source MoE with 1 T parameters and a 128 K token context, self-hostable and priced at just $0.15/$2.50 per million tokens—ideal for high-volume or agentic workflows—while Grok 4 is a proprietary dense model with 1.7 T parameters, a 256 K token window plus live web/X hooks, costing $3/$15 per million tokens and excelling at deep reasoning and real-time data. Benchmarks show Grok leading on live-execution and toughest reasoning tasks, with Kimi matching on static coding and general-knowledge tests at one-tenth the cost. In a real-world LangGraph run, Kimi K2 completed the pipeline in half the time (86 s vs 168 s) at one-tenth the cost ($0.012 vs $0.128).
Architecture
| Model | Core design | Params (total / active) | Context window | Stand-out features |
| Kimi K2 | Mixture-of-Experts | 1 T / 32 B active | 128 K tokens (up to 1 M offline) | MuonClip optimizer, open weights |
| Grok 4 | Dense + RL-tuned; “Heavy” = multi-agent | ≈ 1.7 T | 256 K via API | Real-time X/Twitter & web search, Colossus-scale training |
Kimi K2
Moonshot’s MoE activates just 32 B parameters per token, giving near-GPT-4o performance at far lower compute. The open Apache 2.0 license plus 128 K context makes it attractive for self-hosting and agentic workflows.
Grok 4
xAI trained Grok 4 on 200 K H100 GPUs; the Heavy variant federates multiple Groks that “debate” their answers, boosting deep reasoning. Real-time data hooks mean answers stay current without extra retrieval plumbing.
Benchmarks
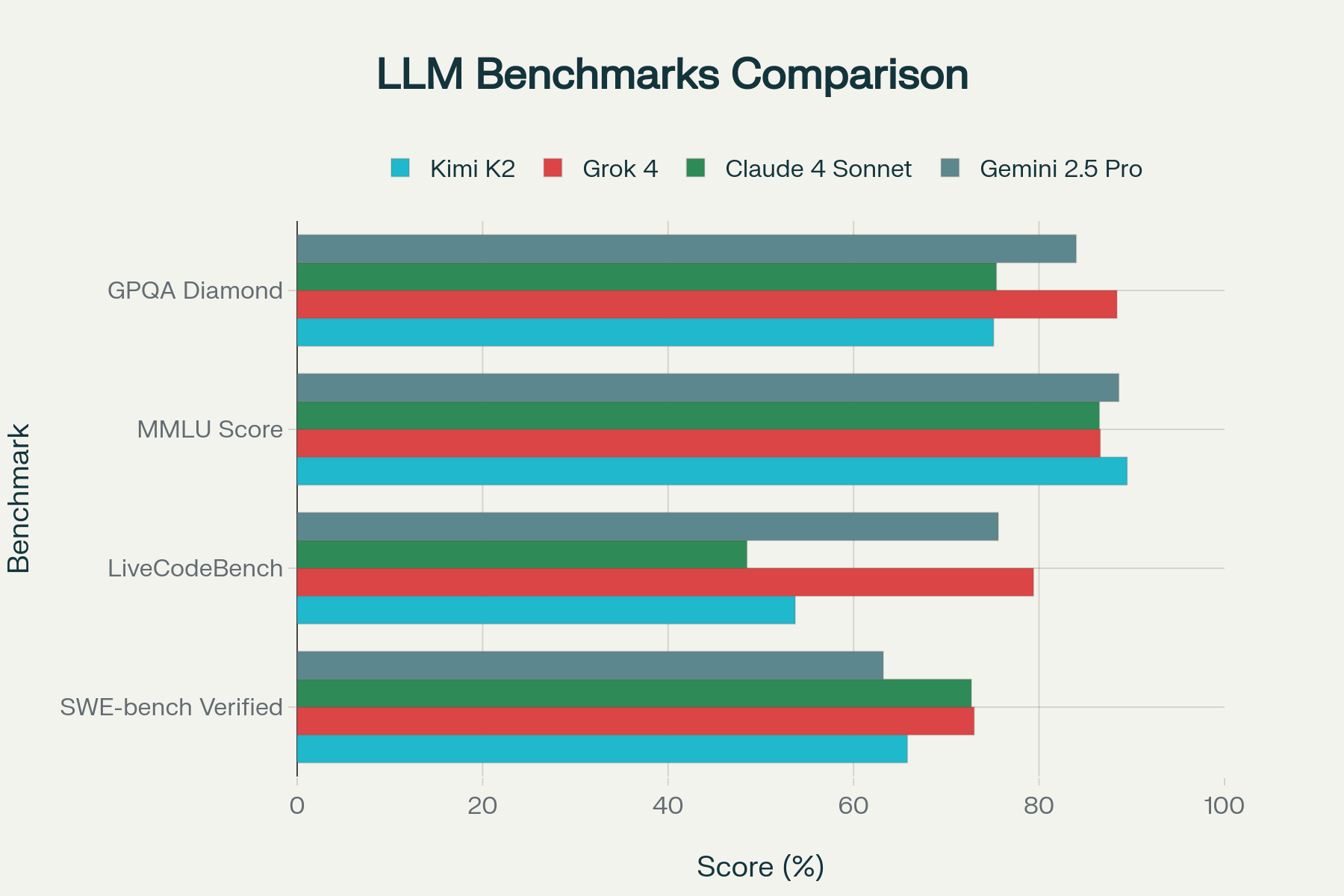
| Suite | Kimi K2 | Grok 4 | Notes |
| SWE-bench Verified | 65.8 % (71.6 % w/ parallel) | 73 % | Real-world GitHub bug-fixing |
| LiveCodeBench | 53.7 % | 79.4 % | Code must compile & run |
| MMLU | 89.5 % | 86.6 % | General knowledge |
| GPQA Diamond | 75.1 % | 88.4 % | Grad-level physics |
Take-away: Grok 4 dominates the hardest reasoning and live-execution tasks; Kimi stays neck-and-neck on static coding and actually wins broad knowledge tests—all while being orders-of-magnitude cheaper.
Use Cases
| Scenario | Best fit | Rationale | Self-hostable? |
| Autonomous agents & CI/CD | Kimi K2 | Native sandboxed tool-calling + open plugin ecosystem | ✅ Yes |
| Whole-repo deep debugging | Grok 4 Heavy | 256 K context + multi-agent reasoning spots elusive bugs | ❌ No |
| Budget-constrained startups | Kimi K2 | $0.15 / $2.50 per M tokens vs $3 / $15 per M tokens; self-host option | ✅ Yes |
| Regulated enterprise, live data | Grok 4 | SOC 2/GDPR compliance; real-time search; enterprise support | ❌ No |
Both models provide correct solutions, but Kimi K2’s open-source nature and lower cost make it more accessible for high-volume or repetitive tasks, while Grok 4’s premium features justify its higher price when you need complex reasoning or real-time data.
Accessibility through LangDB
Both models (alongside Claude 4, Gemini 2.5 Pro, and 300+ others) are available through LangDB’s OpenAI-compatible API.
LangDB is the fastest enterprise AI gateway—fully built in Rust—to secure, govern, and optimize AI traffic across 250+ LLMs via a single OpenAI-compatible API. Key features include:
Unified access to Kimi K2, Grok 4, Claude 4, Gemini 2.5 Pro, and hundreds more
Observability & tracing for every request and agent step
Guardrails to enforce policy and compliance
Cost control without changing your code
Framework-agnostic—works seamlessly with LangChain, LangGraph, and any OpenAI-compatible library
Integrate in minutes and let LangDB handle model management, metrics, and governance so you can focus on building.
Real-World LangGraph Performance
To see these differences in action, we ran the same LangGraph data-extraction pipeline against both models (full traces linked below):

Grok 4: https://app.langdb.ai/sharing/threads/4d25db11-e011-41be-b7bc-c12f7edee2fb
Kimi K2: https://app.langdb.ai/sharing/threads/82403cde-533a-41b5-bf03-92abceb2b018
| Model | Cost (USD) | Time Taken (s) |
| Grok 4 | 0.128 | 167.87 |
| Kimi K2 | 0.012 | 86.00 |
See it in action:
LangGraph data-extraction guide → https://docs.langdb.ai/guides/building-agents/building-complex-data-extraction-with-langgraph
Full code examples → https://github.com/langdb/langdb-samples/tree/main/examples/langchain/langchain-data-extraction
On the same LangGraph pipeline, Kimi K2 ran in roughly half the time and at one-tenth the cost of Grok 4. This real-world test underlines the cost-efficiency and speed advantages of an open-source MoE model for typical data-extraction workflows.
However, if your pipeline demands the deepest reasoning chains or the freshest web-hooks, Grok 4’s premium features may still be worth the extra spend and latency. Evaluate your throughput and SLAs to pick the best fit.
Conclusion
AI’s future isn’t one-size-fits-all. Kimi K2 democratizes near-SOTA coding for pennies and full control, while Grok 4 pushes the reasoning ceiling and keeps answers current—at a premium. With LangDB, you can seamlessly plug both into your stack and choose the right model per task, without rewriting your integration. Pick your path, optimize your costs, and get building!
Subscribe to my newsletter
Read articles from Mrunmay Shelar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by