Beyond Integrations: How to Build the Future of AI with Context Engineering
 Context Space
Context Space"When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. " — Andrej Karpathy
In the race to build smarter AI systems, the industry has focused heavily on prompt engineering. But as practitioners and organizations push LLMs into more complex workflows like customer support, autonomous agents, and copilots, one thing is becoming clear: prompts aren't enough.
The real unlock lies in a deeper architectural shift: context engineering.
What is Context Engineering?
Context engineering is the emerging discipline of designing the infrastructure, processes, and protocols that give AI agents access to high-quality, relevant, and persistent context across time, data sources, and interactions.
Whereas prompt engineering focuses on optimizing single inputs to LLMs, context engineering builds the information ecosystem around the model:
| Aspect | Prompt Engineering | Context Engineering |
| Focus | Crafting better instructions | Delivering the right data, at the right time |
| Scope | One-shot prompts | Persistent, multi-turn, memory-driven interaction |
| Integration | Minimal | Deep integration across services and data streams |
| Memory | Stateless | Stateful, evolving memory and personalization |
| Scalability | Human-crafted | Systematic and automated at scale |
Why Prompt Engineering Falls Short
LLMs are certainly very powerful, but they constantly suffer from amnesia. Without memory, situational awareness, or external grounding, they:
- Hallucinate facts
- Lose track of user preferences
- Repeat themselves
- Fail in longer interactions
These aren't model failures, they’re context failures.
As systems grow more complex, context becomes the bottleneck. Reliable AI agents need dynamic access to the right information, not just well-crafted prompts.
Our Belief: Context Engineering Starts with MCP + Integrations
To operationalize context, we need a new foundation. At Context Space, we believe this starts with two pillars:
1. MCP (Model Context Protocol) — The Universal Context Interface
MCP provides a standardized way for AI agents to:
- Read and write to memory
- Query for relevant context
- Fetch data from third-party sources
- Structure and compress inputs for model compatibility Think of MCP as the equivalent of HTTP for context. In other words, a protocol that separates model logic from memory, perception, and integration.
2. Service Integrations — The Context Graph in Action
Context lives in tools: GitHub, Slack, Notion, Airtable, Figma, Zoom, Stripe, HubSpot, and beyond. Real-world AI agents can’t function without:
- OAuth-secured access to data
- Structured operations across services
- Normalized representations of user activity
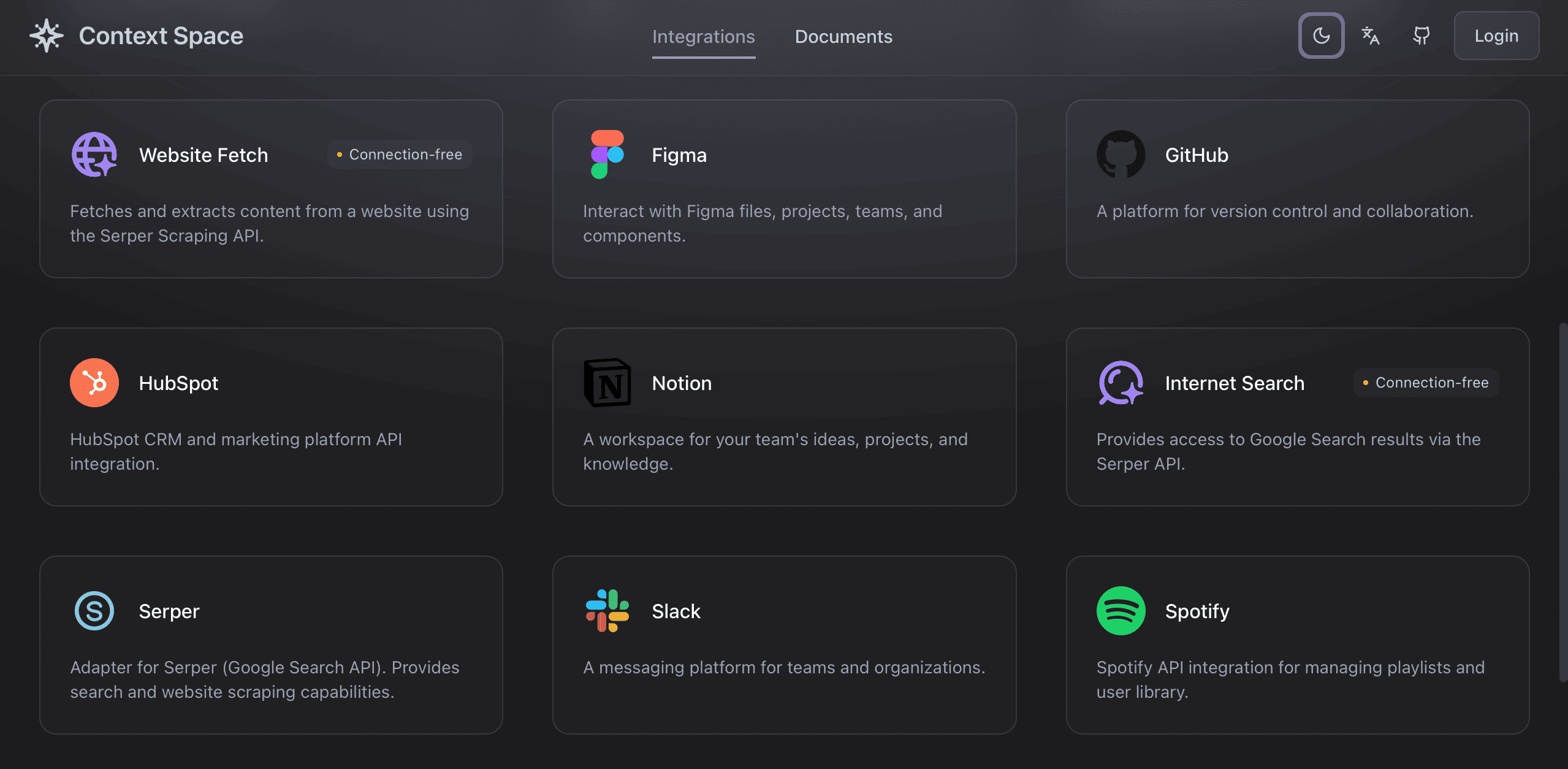
That’s why Context Space ships with over 14+ service integrations out of the box, with clean APIs, secure authentication, and production-ready pipelines.
The Four Pillars of Context Engineering
Context Space is built around the four core stages of context lifecycle:
1. Write Context
- Persistent memory
- Knowledge graphs, scratchpads
- Long-term storage across sessions
2. Select Context
- Semantic retrieval (RAG)
- Relevance scoring
- Metadata and user history filtering
3. Compress Context
- Token optimization
- Summarization and pruning
- Dynamic prioritization
4. Isolate Context
- Multi-agent separation
- Tenant-aware memory boundaries
- Secure sandboxing for safe experimentation
What We've Built So Far
Building context-aware agents isn't just a prompt problem — it's a software architecture problem. That’s why Context Space includes:
✅ 14+ Integrated Services
- GitHub, Slack, Airtable, Zoom, HubSpot, Notion, Figma, Spotify, Stripe, and more
- Secure OAuth 2.0 Flows
- JWT-based auth + HashiCorp Vault for credential storage
✅ MCP-Ready Architecture
- REST APIs and future MCP protocol endpoints
- Agent-compatible abstractions for context I/O
✅ Production Infrastructure
- Docker + Kubernetes deployment
- PostgreSQL, Redis, Vault
- Monitoring with Prometheus, Grafana, Jaeger
Built for AI developers
If you’ve ever:
- Tried to build multi-turn memory from scratch
- Hand-coded Slack or Notion context pipelines
- Managed model prompts with YAML files
- Struggled with hallucinations or brittle agents
Then you already know the pain.
Context Space abstracts this complexity into a modular, extensible system. You focus on agent behavior and we handle context orchestration.
What's Next: Our Roadmap
Phase 1: Core Context Engine (Next 6 months)
- ✅ 14+ Integrations
- 🔄 Native MCP support
- 🔄 Persistent context memory
- 🔄 Intelligent data aggregation
Phase 2: Intelligent Context Management (6–12 months)
- 🔄 Semantic retrieval
- 🔄 Context scoring & compression
- 🔄 Real-time context updates
Phase 3: Agent Context Intelligence (12+ months)
- 🔄 Predictive context loading
- 🔄 Relationship-aware synthesis
- 🔄 Context analytics & visualization
Why Start With Context Space Today?
- Immediate Value: Production-ready, plug-and-play integrations
- Security First: JWT auth + Vault + scoped access
- Observability: Metrics, logs, and tracing out of the box
- Developer-Friendly: Clean API with docs and examples
You don’t need to reinvent context infrastructure yourself. We’ve done the hard part for you. Join the movement to build better memory and better AI.
Context Space is licensed under AGPL v3 with planned transition to Apache 2.0. Contact us for commercial licensing options.
Subscribe to my newsletter
Read articles from Context Space directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by