The Internals of Bidirectional Pagination in Relay: A Deep Dive
 Ikjot Singh
Ikjot Singh
Relay is a GraphQL client built by Meta, designed for large-scale, high-performance apps. Unlike more flexible alternatives like Apollo, Relay enforces stricter rules for how you write queries and manage your local store — which means fewer hidden bugs, but a steeper learning curve.
One of Relay’s biggest selling points is its battle-tested, “black-box” implementation of bidirectional pagination. If you’ve ever used it, you’ve probably wondered: What actually happens behind the scenes?
How does Relay merge pages when you scroll up and down at the same time?
Bidirectional pagination is powerful — but it can feel like magic. Let’s break it down.
A Quick Primer on Bidirectional Pagination
Before we get into the bi in bidirectional, let’s start with the basics. When you’re dealing with huge lists — like your Twitter/X feed or a WhatsApp chat — it’s not practical to load everything at once. Pagination lets your app fetch just a chunk of data first, then grab more as you scroll.
Bidirectional pagination is simply a smarter version: you can scroll both ways — fetching older or newer data around a point of interest.
Take WhatsApp: imagine you search for an old message from two months ago. You tap that message — now you might want to scroll up to see what came before, or down to see what came after. Bidirectional pagination makes this smooth and efficient.
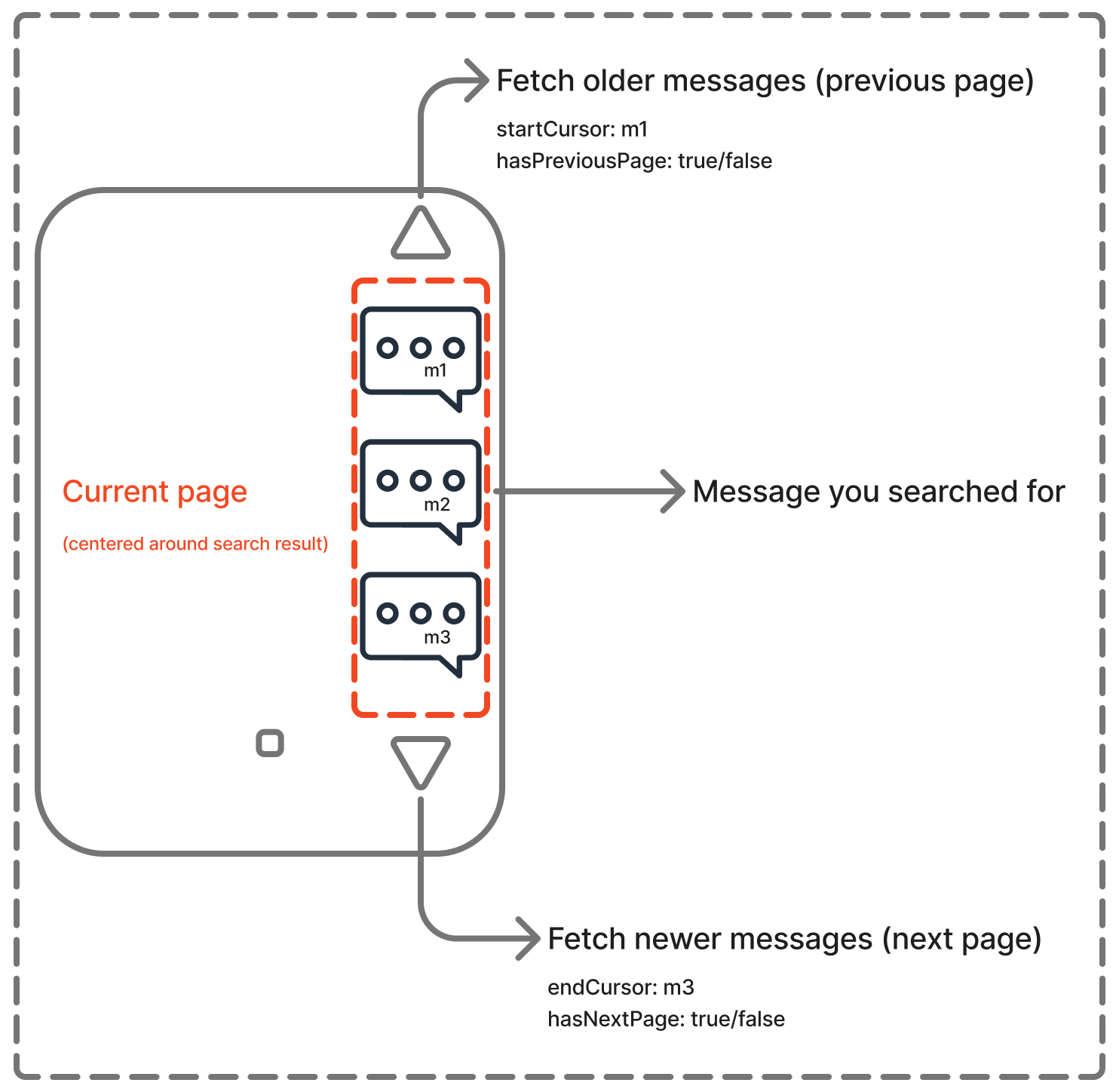
Think of it like two doors: you can open more of the list from the top or the bottom, but it all connects in the same hallway.
Merging these pages correctly — without duplicates, gaps, or weird jumps — is tricky. But Relay handles this for you with its connections system. Let’s see how.
Connections, Edges, and Cursors: The Building Blocks
Relay wants you to think of your data as a graph. A list of related items — like a user’s friends — is just another branch in that graph.
Let’s start simple. Suppose you want to fetch a user and their friends:
query {
user(id: "123") {
name
friends(first: 10) {
id
name
}
}
}
This asks for the first 10 friends of user 123. Straightforward. But how does your app know there are more? How do you fetch them — and where do you merge them?
That’s where connections come in. Relay (and GraphQL best practice) breaks lists into a clear structure:
- Edges: Each edge holds a single item (
node) plus a cursor. - pageInfo: Special metadata that says if there’s more data before or after this chunk, and gives you the cursors to get it.
So your real query looks more like this:
query {
user(id: "123") {
name
friends(first: 10) @connection(key: "UserFriends_friends") {
edges {
node {
id
name
}
cursor
}
pageInfo {
hasNextPage
hasPreviousPage
startCursor
endCursor
}
}
}
}
How does this actually work?
- The
@connectiondirective tells Relay: “Track this list. Merge new pages cleanly when I fetch more.” - Edges hold each friend’s info plus a cursor — like a bookmark for where you are in the list.
- pageInfo says what’s next or previous — and provides the cursors to continue.
When you want to load more friends, you don’t just call first: 10 again.
You use a cursor:
To scroll forward:
friends(first: 10, after: "")
→ Relay merges these new edges at the end.To scroll backward:
friends(last: 10, before: "")
→ Relay merges these new edges at the start.
This is bidirectional pagination in action — Relay’s internals ensure the new edges fit perfectly with the old ones, without overlaps or missing data.
But do you write before and after by hand?
Nope! That’s where Relay’s smart client helpers come in.
In practice, you don’t write this whole query directly in your component.
Relay encourages you to break it into fragments — each fragment describes exactly what a single component needs.
To paginate, you wrap the list in a pagination fragment and use Relay’s usePaginationFragment hook.
When your component runs, Relay gives you helpers like loadNext and loadPrevious. Under the hood, these automatically:
- Pick up the right cursor (
endCursororstartCursor) frompageInfo - Plug it into
afterorbeforefor you - Fire the next request for more edges
- Merge the new edges into the right place
No manual cursors. No manual merging. You just call loadNext or loadPrevious — Relay does the rest.
Up next: Let’s peek under the hood at how Relay’s store and connection handlers keep your list smooth and consistent, even when you scroll in two directions at once.
Behind the Scenes: How Relay Actually Merges Pages
So far, we’ve seen how your GraphQL query is structured — and how usePaginationFragment handles fetching new pages in both directions.
But how does Relay actually keep this list in sync inside its local store?
How does it know where to insert new edges? And how does it make sure your UI updates correctly, with no duplicates or flickers?
Let’s peek into the internals.
Under the Hood: Relay’s Store Architecture
Before we zoom in on how connections merge pages, it helps to understand the key pieces of Relay’s architecture.
Relay isn’t just a GraphQL client — it’s also a local data store, a change tracker, and a consistency manager all in one.
At the heart of it are a few core pieces:
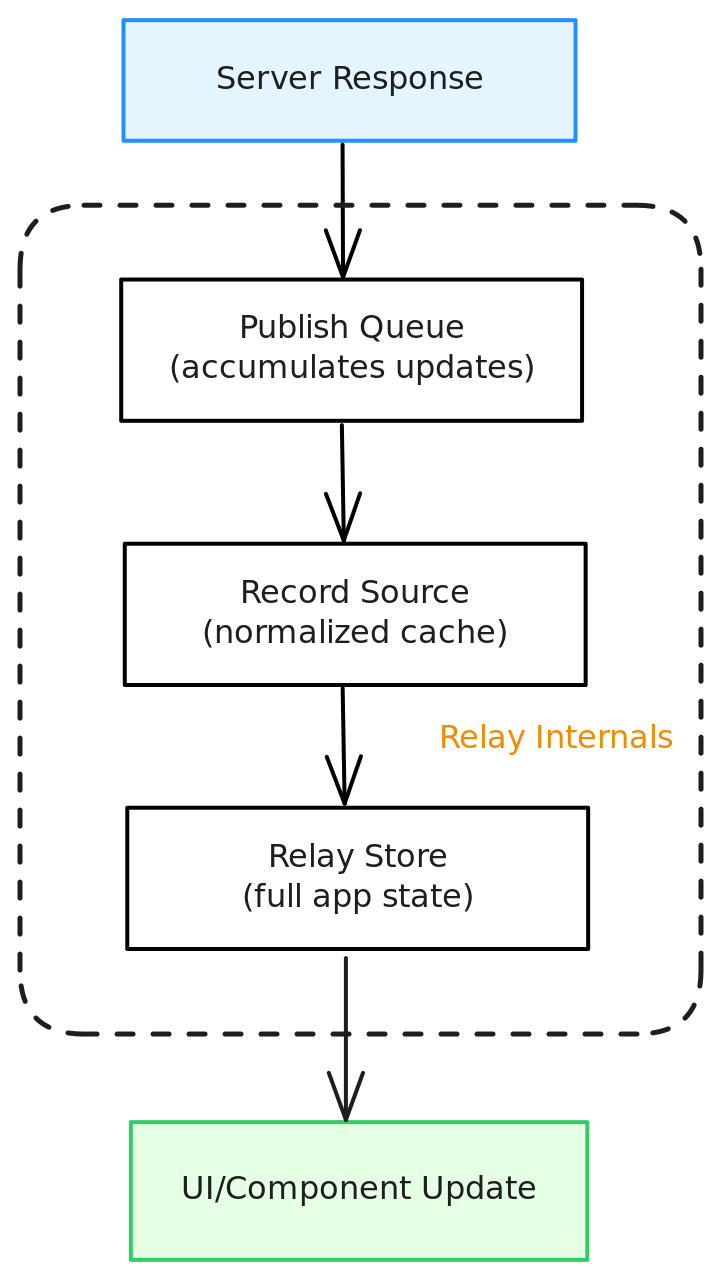
Relay Store
The Relay Store is the single source of truth for your app’s active GraphQL data.
It holds normalized records for all queries, fragments, and subscriptions that your components are currently using.
When no part of your app references certain records anymore, Relay’s garbage collector can safely clean them up — keeping your Store lean and memory-efficient (This can be customized based on your requirements).
Every query, mutation, or subscription you run updates the Store, and Relay makes sure your components always see the freshest version of the data they depend on.
RecordSource
The RecordSource is the low-level map of all your data.
It’s basically a giant key-value store that keeps all your Relay data:
- Keys: Unique IDs for your records (like
User:123) - Values: The actual fields and nested references for that record
Think of it like a normalized cache: no duplicates, no wasted data => Memory Efficient!
Record Proxies
When you write a mutation or pagination updater, you don’t directly mutate the Store.
Instead, Relay gives you proxies — safe wrappers like RecordProxy and RelayRecordSourceProxy.
These proxies let you describe changes:
- Add or remove edges
- Update a field on a node
- Insert new nodes into a connection
Relay then commits those changes in a controlled way via the PublishQueue. This guarantees consistency and avoids race conditions.
Publish Queue
The PublishQueue is Relay’s message queue.
When a network response comes back — or you run an optimistic update — Relay doesn’t update changes directly into the Store.
Instead, the changes go through the PublishQueue:
- It figures out what changed
- It updates the RecordSource
- It notifies any UI components watching those records
This is how Relay guarantees that your UI stays in sync without you wiring manual cache updates.
To summarize, Relay keeps all your data in a normalized graph called the RecordSource, managed by the Store. When you run a pagination update, Relay uses a PublishQueue and safe Proxy objects to merge the new page into the right place — without breaking anything else.
Together, these parts mean that when you load the next page or the previous page, the new edges flow through:
- Network → PublishQueue → RecordSource → Store → Components
Your list updates automatically, your cache stays normalized, and duplicate edges get handled automatically.
Now that you know how Relay’s store works, let’s see how the Connection Handler fits in — and how it merges new pages into your connection in both directions, without conflicts or gaps.
The Connection Handler
At the heart of this is Relay’s Connection Handler.
When Relay sees the @connection directive, it knows this field is special. It stores that list in a normalized way inside its local store. The Connection Handler keeps track of:
- The current edges
- The pageInfo (startCursor, endCursor, hasNextPage, hasPreviousPage)
- The connection key you provided (like
"UserFriends_friends")
Whenever you call loadNext or loadPrevious, Relay:
- Reads the right cursor (
endCursororstartCursor) frompageInfo - Builds a new query with the
afterorbeforeargument - Sends the request and gets new edges + new
pageInfo - Merges the new edges into the connection:
- If you paged forward, it appends to the end.
- If you paged backward, it prepends to the start.
This merge happens in Relay’s normalized store, which means other components reusing the same connection see the updated list automatically — no manual cache updates needed.
How Does It Avoid Duplicates?
Relay’s store is keyed by IDs. Each node under edges has a unique ID (id). If the server accidentally sends overlapping items (like your page 1 ends at user 10 and your page 2 starts at user 10 again), Relay’s merge logic de-duplicates it using these IDs.
This is why using stable IDs on your server is so important — it ensures Relay can merge pages without showing the same item twice.
Why This Matters
You don’t have to wire any of this yourself.
You don’t have to manually splice arrays or juggle “current page” states.
Relay’s Connection Handler + usePaginationFragment means your list:
- Loads in both directions
- De-duplicates edges
- Merges pages smoothly
- Reacts instantly in your UI
This is the magic that makes bidirectional pagination “just work.”
Inside ConnectionHandler.update(): How Relay Actually Merges Pages
Once you've fetched paginated data using @connection, Relay delegates rendering to a handler. This handler uses an update() function that determines how to merge new edges into the client-side store while maintaining pagination metadata like cursors and hasNextPage.
Let’s break it down:
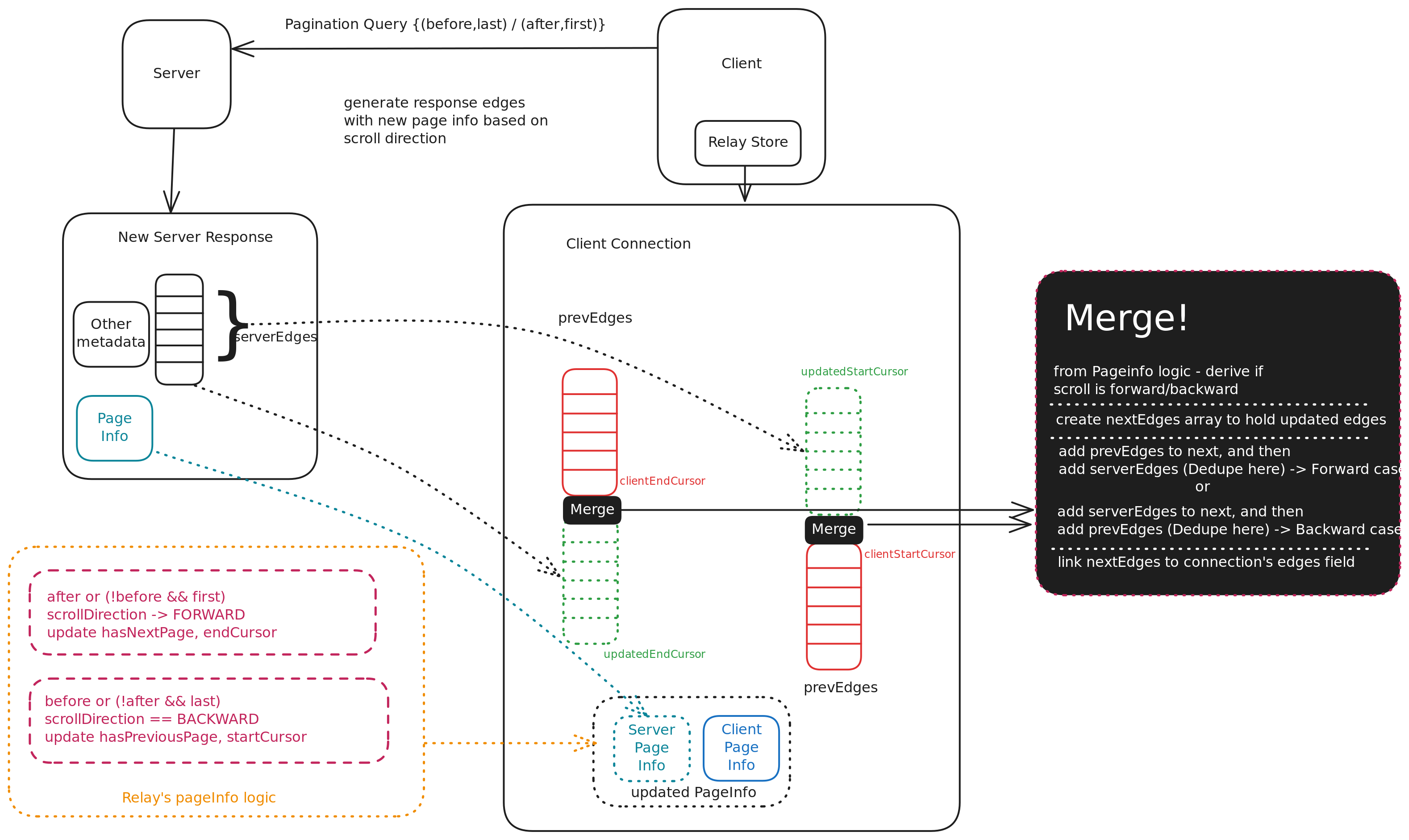
Step 1: Identify the Source
Relay provides payload, which tells you:
- Which record you're updating (
dataID) - The connection field on the server (
fieldKey) - The client-side handle (
handleKey)
The updater uses this info to grab the record from the store and fetch the server-side connection field.
Step 2: Determine Client-Side Connection
- If there's no existing client connection, we create one using
generateClientID(), copy fields from the server, and assign a freshpageInfo. - If it already exists, we reuse it, optionally re-linking it if the
handleKeyisn’t set yet.
Step 3: Merge Edges Intelligently
Based on after or before args, Relay decides:
- Are we paginating forward or backward?
- Is it a refetch or incremental fetch?
Relay deduplicates nodes (by node.id) and merges new and previous edges accordingly.
Step 4: Sync PageInfo
Relay then updates pageInfo depending on the type of pagination:
- Replace it entirely (in case of full refetch)
- Or selectively update:
hasNextPageendCursorhasPreviousPagestartCursor
This is crucial for enabling infinite scrolls or paged lists to keep fetching smoothly.
Note:
- During forward pagination, only
hasNextPageandendCursorare updated. - During backward pagination, only
hasPreviousPageandstartCursorare updated. - For initial page loads (when neither
afternorbeforeis provided in the query), the entirepageInfofrom the server is directly copied into the client-side connection.
Why This Matters
This updater is the secret sauce behind how Relay seamlessly handles pagination without you having to micromanage lists, cursors, or duplicates.
By walking through this lifecycle and mapping server responses to normalized client records, Relay guarantees your UI stays in sync with your backend — no matter how complex your pagination gets.
Next: Let’s wrap this up with some gotchas, best practices, and a simple starter boilerplate you can adapt for your own app!
Pitfalls and Best Practices
Relay’s pagination feels magical once it clicks — but there are a few pitfalls to watch for, especially when building advanced pagination handlers or wiring it all up from scratch.
Common Pitfalls
You must use the
@connectionhandler
Relay only applies pagination logic and handlers when@connection(key: "...")is present on your fragment field. Without it, edges and pageInfo won’t be stored or updated correctly. Relay won't even handle/call the updater as we saw above if we don't add this directive.Missing
pageInfoin schema = silent bugs
Ensure your GraphQL schema includesstartCursor,endCursor,hasNextPage, andhasPreviousPagein thepageInfofield. Relay expects these to exist to properly manage pagination. If you don't add these fields - in case of first page fetches/your connection may not be updated to the store as you'd expect.node.idis used for deduping
If your edges don’t contain uniquenode.ids, Relay’s merge logic may misbehave or allow duplicates. Always ensurenode.idis globally unique.Refetch ≠ Pagination
Callingrefetchreplaces the whole connection, whileloadNext/loadPreviousappends/prepends edges. Use the right one depending on your UX needs. For pagination, you should useloadNext/loadPrevious.Cursors are auto-injected by Relay
You don’t manually passafterorbeforeto the server. When usingusePaginationFragment, Relay pulls the right cursor from thepageInfoand injects it into the next query.
Best Practices
Use stable connection keys
Avoid interpolating dynamic values into@connection(key: "..."). Prefer static keys and usefiltersto differentiate if needed.Always normalize edges and node IDs
Even in backend responses, ensure youredges[].node.idis present and unique. This plays well with Relay’s store and deduplication.Debug with
__idand DevTools
You can inspect how connections and edges are structured in the Relay store using the__idfield or Relay DevTools. Very useful when things don’t behave as expected. You could also add breakpoints in the relevant Relay files in your DevTool sources (connectionHandler.js,RelayModernStore.js, etc.) to look at your records - and see what is the current status after a query/mutation.
Wrapping Up
Relay’s pagination system is deceptively powerful — once you understand how the connection model, cursors, and store updates interact, it feels almost invisible.
By using @connection and relying on the ConnectionHandler’s update cycle, you gain:
- Automatic edge merging and deduplication
- Cursor-aware infinite scrolls
- Minimal manual state management
Understanding this lifecycle not only helps in debugging but also empowers you to confidently build scalable, performant lists in any app.
Embrace the Relay — let it handle the complexity, so you can focus on product.
References and Further Reading
Here are some official docs, articles, and community resources that provide deeper insights into Relay's pagination system and store architecture:
Official Documentation
Relay Pagination (Relay Docs)
CoversusePaginationFragment, connections, and loading more data.Relay Advanced Pagination Usage
Relay API docs for bidirectional pagination/ paginating over multiple connections.Relay Store APIs
Explore APIs available to update/read store in Relay@connection Directive
Quick tutorial on how connections/pagination/cursors etc. work.GraphQL Cursor Connections Specification
The foundational spec that Relay's pagination is based on. Very useful to understand how Meta expects you to use Relay for pagination.
Debugging & Tools
- Relay DevTools Chrome Extension
Inspect your Relay store, queries, and connections in real time.
Subscribe to my newsletter
Read articles from Ikjot Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by