Reinforcement Learning Explained: The Future Beyond LLMs
 Aulia saudagar Affaan Safi
Aulia saudagar Affaan SafiIntroduction
🧠 LLMs are the stars of AI right now.
From GPT to Claude, language models are answering questions, writing essays, and summarizing research. But behind the scenes, another branch of AI is quietly shaping the future—Reinforcement Learning (RL).
If LLMs are experts in knowledge, RL agents are experts in action. They don't just understand the world—they interact with it, adapt to it, and learn from their actions. Whether it's a robot learning to walk, an AI mastering chess, or ChatGPT improving at following human preferences through Reinforcement Learning from Human Feedback (RLHF)—RL is the key ingredient behind intelligent behavior.
🎯 If you’ve ever trained a puppy with treats or learned to ride a bike by trial and error—you already know how RL works.
In this post, we’ll break down RL with simple metaphors, visuals, and examples, and show how it fits beautifully alongside LLM
- The Core Idea of R.L: -
Reinforcement Learning (RL) is a machine learning paradigm where an agent learns to make decisions by interacting with an environment to maximize cumulative rewards. The core components of RL define how the agent interacts, learns, and optimizes its behavior.
Key Components
Agent: The decision-maker or learner that performs actions in the environment to achieve a goal. For example, a robot navigating a maze acts as the agent.
Environment: The external system or world in which the agent operates. It provides feedback in the form of rewards or penalties based on the agent's actions.
State: The current situation or condition of the agent as perceived from the environment. For instance, in a game, the state could represent the current position of the player.
Action: The possible moves or decisions the agent can take in a given state. Actions influence the transition to new states.
Reward: The feedback signal from the environment that evaluates the agent's action. Positive rewards encourage desirable behavior, while penalties discourage undesirable actions.
Policy: A strategy or mapping that determines the agent's next action based on its current state. Policies can be deterministic (fixed action for a state) or stochastic (probabilistic actions).
Value Function: This estimates the long-term cumulative reward expected from a state. It helps the agent evaluate the desirability of states beyond immediate rewards.
Model of the Environment: An optional component that predicts future states and rewards based on the agent's actions. It aids in planning and decision-making.
Example:
for episode in range(100):
state = env.reset()
while not done:
action = agent.select_action(state)
next_state, reward, done = env.step(action)
agent.learn(state, action, reward, next_state)
state = next_state
In this loop, the agent gradually gets better at choosing actions that lead to higher rewards
1️⃣ Exploration vs. Exploitation
Imagine a kid trying out all the slides in a playground. Some are more fun than others.
Exploration = Try different slides to see which is best.
Exploitation = Keep going on the slide you already know is fun.
🔄 Tradeoff: You need both. Try enough new things and stick with what works.
2️⃣ Q-Learning (Learning Value of Actions)
🧠 “Q” stands for quality—how good is an action in a given state?
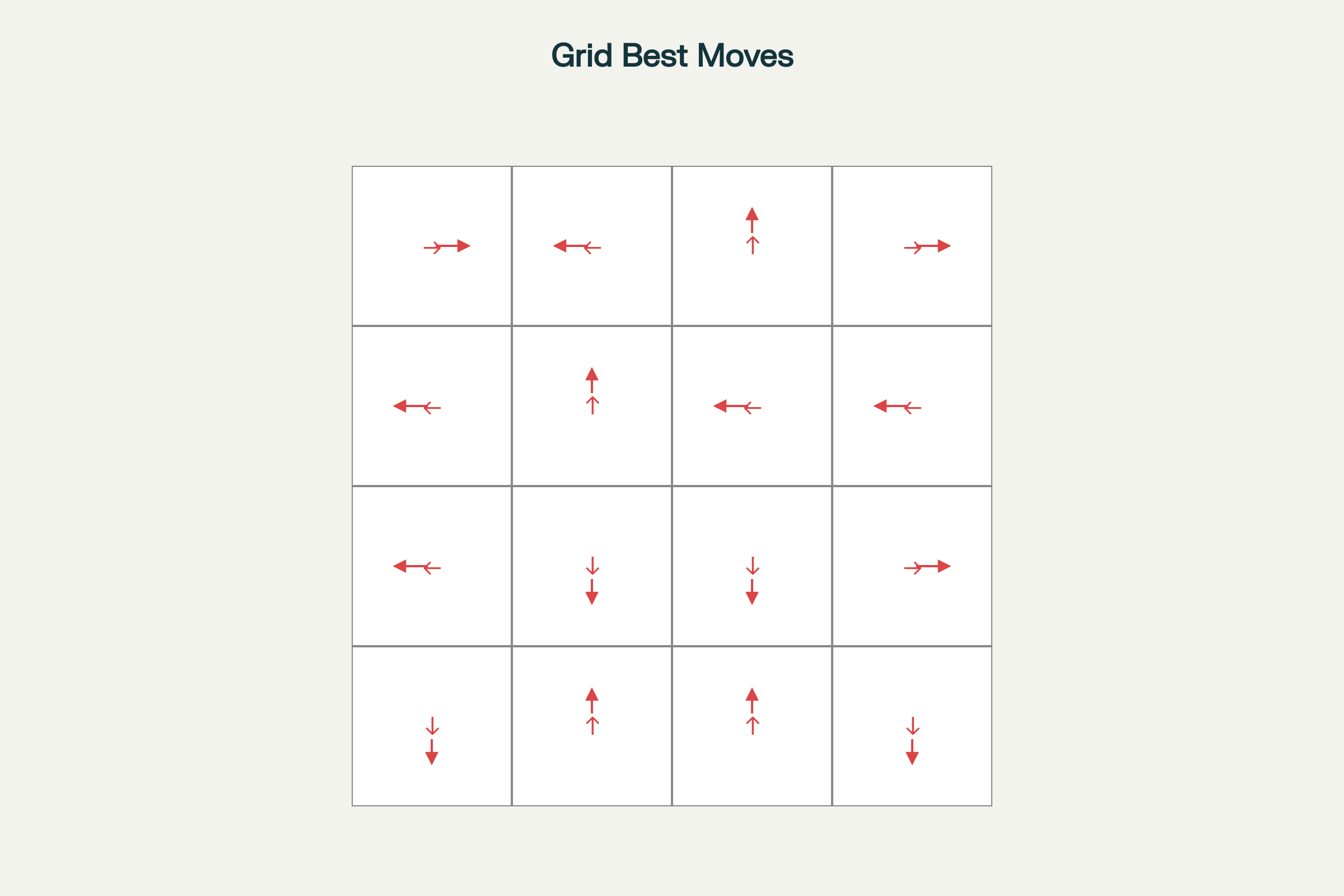
Grid world with arrows showing the best action based on Q-learning values for each cell
The arrows point in the direction of the highest-value action for each state (up, right, down, or left).
This pattern emerges after the agent has updated its Q-table using the update rule:
Q[state][action]=Q[state][action]+learning_rate×(reward+discount×max(Q[next_state])−Q[state][action])Q[state][action]=Q[state][action]+learning_rate×(reward+discount×max(Q[next_state])−Q[state][action])
Over time, these best-move arrows reveal the optimal policy found by the agent.
3️⃣ Policy Gradients (Learning the Strategy Directly)
Instead of assigning values to actions, policy gradients directly tweak the probability of choosing actions.
🎯 Analogy: Adjusting your basketball shot by analyzing how likely it is to score and tweaking your throw accordingly.
loss = -log(probability of action) * reward
Used when actions are continuous or stochastic (like adjusting steering in a self-driving car).
RL vs. Supervised & Unsupervised Learning:
| Type of Learning | Learns From | Output | Example |
| Supervised | Labeled data | Prediction | Classifying cats vs dogs |
| Unsupervised | Unlabeled data | Clusters/Patterns | Grouping news articles |
| Reinforcement | Interaction & Feedback | Policy (behavior) | Playing chess, driving car |
Key Difference:
RL learns what to do next, not just patterns in existing data. It’s dynamic and sequential, not static.
How RL Complements LLMs
✨ RL + LLMs = Smarter AI
Reinforcement Learning from Human Feedback (RLHF)
Used to fine-tune ChatGPT.
Humans rate LLM responses → RL optimizes for helpfulness, safety, and clarity.
Robotics + Transformers
Use LLMs to interpret instructions (“Pick up the red ball”)
Use RL to figure out how to move the arm to do it.
Game Agents
AlphaStar, OpenAI Five use RL to learn game strategies.
Transformers help in modeling complex state transitions and history.
🔗 RL helps LLMs improve through feedback. LLMs help RL by understanding the world.
- 🚀 Ready to Try RL Yourself?
Getting started is easier than you think.
🛠️ Tools to Explore:
OpenAI Gym: Simulated environments to train RL agents.
Stable-Baselines3: Plug-and-play RL algorithms in Python.
Google Colab: No local setup needed—run RL experiments in the cloud.
📘 Suggested Resources:
Subscribe to my newsletter
Read articles from Aulia saudagar Affaan Safi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by