Blocking vs Non-blocking vs Asynchronous I/O
 Sachin Tolay
Sachin TolayWhen a program performs I/O → like reading from a file or socket → two key questions arise:
Does the program stop and wait for the data, or continue running? (Blocking vs Non-blocking IO)
Does the program keep checking for the result, or get notified when it’s done? (Synchronous vs Asynchronous IO)
These are orthogonal concepts, meaning they can be mixed in different combinations. Each combination comes with trade-offs in performance, complexity, and responsiveness. In this article, we'll break down these models to understand how I/O really works under the hood.
Blocking vs Non-blocking I/O Intuition
Question to ask → After placing the coffee order, do you stand there waiting until it’s ready, or do you walk away and do other things in the meantime?
Blocking: You stand at the coffee counter and wait until your coffee is ready before leaving.
Non-blocking: You place your order and then walk away; if the coffee isn’t ready yet, you don’t wait → you might come back later to check.
Synchronous vs Asynchronous I/O Intuition
Question to ask → After placing the coffee order, do you keep checking if it’s ready, or do they notify you when it’s done?
Synchronous: You keep walking back to the counter every few minutes to ask, “Is my coffee ready yet?”
Asynchronous: You leave and go about your day → when your coffee is ready, they text you so you know to come back.
Note - It’s important to understand that asynchronous and non-blocking are related but different concepts:
Non-blocking I/O is about waiting vs not waiting → whether the program waits (blocks) for the operation to complete or the call returns immediately if data isn’t ready.
Asynchronous I/O is about who drives the control flow → whether the program itself keeps checking (synchronous) or the system notifies the program when the operation completes (asynchronous).
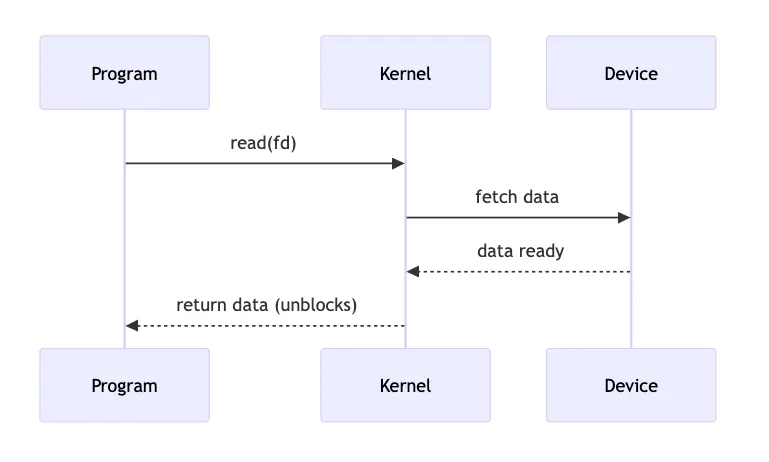
Blocking I/O Implementation - Using read()
The call waits until completion before returning, as shown in the diagram below.
// Blocking read
int n = read(fd, buffer, size); // Blocks until data is ready
Non-blocking I/O Synchronous Implementation 1 – Using read()
Your program calls read() again and again in a loop. If there’s no data, read() returns -1 with EAGAIN. This wastes CPU cycles because you're periodically checking by issuing read() system calls. But between checks, your program can do other things (non-blocking). Your program drives the control flow → it decides when to check for the data availability (synchronous).
fcntl(fd, F_SETFL, O_NONBLOCK); // Set fd to non-blocking
while (1) {
int n = read(fd, buffer, sizeof(buffer));
if (n > 0) {
// Got data
handle_data(buffer, n);
break;
} else if (n == -1 && (errno == EAGAIN || errno == EWOULDBLOCK)) {
// No data, do something else
do_other_work();
} else {
// Some other error
break;
}
}
Non-blocking I/O Synchronous Implementation 2 – Using select()/poll()
select() is used to multiplex a set of file descriptors → allowing your program to wait efficiently until any one of them is ready for I/O. Unlike repeatedly calling non-blocking read(), which issues a system call each time and wastes CPU cycles when no data is available, select() makes a single blocking system call that sleeps (means no cpu occupied) until at least one descriptor is ready. After select() returns, checking which descriptors are ready using FD_ISSET is a fast user-space operation that doesn’t incur extra system calls, making the whole process much more efficient.
while (1) {
fd_set fds;
FD_ZERO(&fds);
FD_SET(fd1, &fds);
FD_SET(fd2, &fds);
int max_fd = (fd1 > fd2) ? fd1 : fd2;
// Block until one of the FDs is ready to read
if (select(max_fd + 1, &fds, NULL, NULL, NULL) > 0) {
if (FD_ISSET(fd1, &fds)) {
// fd1 has data
read(fd1, buffer1, sizeof(buffer1));
}
if (FD_ISSET(fd2, &fds)) {
// fd2 has data
read(fd2, buffer2, sizeof(buffer2));
}
}
// You can also perform other logic here
}
Summary So Far

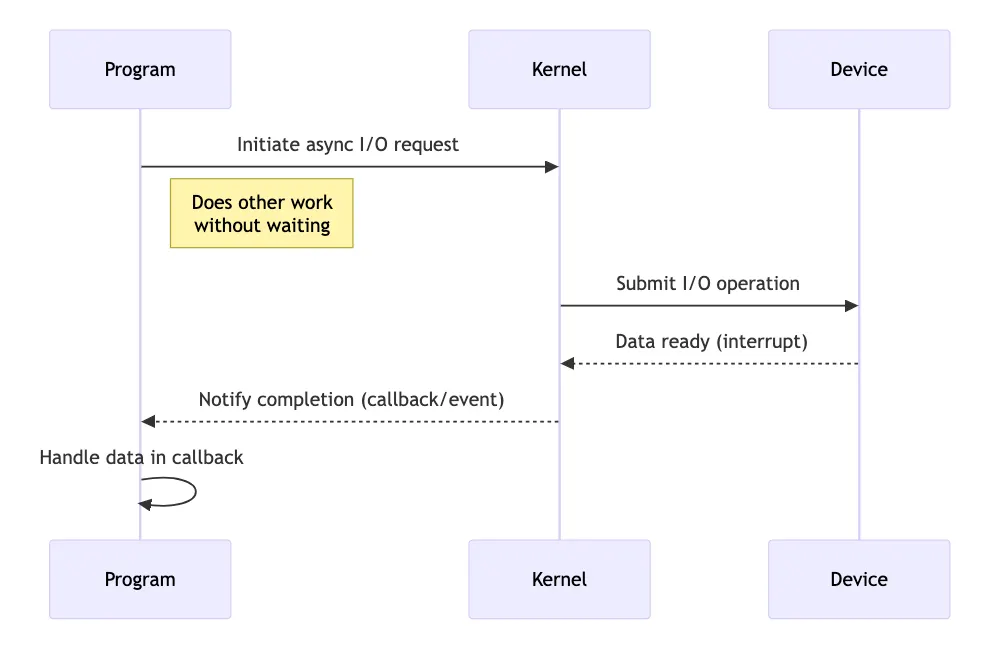
Non-blocking Asynchronous I/O Implementation — Using OS-Provided Async APIs (e.g., io_uring, Windows IOCP, Linux AIO)
In asynchronous I/O, the program initiates the I/O operation and does not check or wait for the result. Instead, the OS notifies the program (via callbacks, signals, or event queues) when the operation completes, handing control back to the program only when data is ready. This allows maximum concurrency and responsiveness, as your program never blocks or polls.
// Initiate async read operation
async_read(fd, buffer, size, callback_function);
// Meanwhile, do other work here
// callback_function is called by OS when data is ready
void callback_function(int result, char* buffer) {
if (result > 0) {
handle_data(buffer, result);
}
}
Final Summary

Subscribe to my newsletter
Read articles from Sachin Tolay directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sachin Tolay
Sachin Tolay
I am here to share everything I know about computer systems: from the internals of CPUs, memory, and storage engines to distributed systems, OS design, blockchain, AI etc. Deep dives, hands-on experiments, and clarity-first explanations.