Adaptive Compute vs. Auto Tune: A Practical Guide to Optimizing Snowflake Warehouses
 Dana Van Aken
Dana Van Aken
Managing Snowflake warehouses efficiently is a constant balancing act. Set them too large, and you're burning money on idle compute. Too small, and your queries slow to a crawl, frustrating users and missing SLAs. For many organizations, this manual tuning process is time-consuming while still leaving significant cost savings on the table.
Two solutions promise to solve this challenge in very different ways: Snowflake's new Adaptive Compute eliminates warehouse management complexity entirely, while Altimate AI's Auto Tune brings intelligent automation to standard warehouses with granular cost controls. This guide breaks down how each works, their tradeoffs, and which to choose based on your specific needs.
What is Adaptive Compute?
Today, managing Snowflake warehouses requires juggling multiple decisions: choosing the right size (X-Small through 6X-Large), configuring cluster policies, setting auto-suspend timers, and more. Get these wrong, and you're likely to be overpaying for idle compute or suffering from poor query performance.
Adaptive Compute changes this equation entirely. Instead of fixed-size warehouses, Adaptive Warehouses act as pointers to a shared, elastic compute pool that Snowflake manages behind the scenes. When you submit a query to an Adaptive Warehouse, Snowflake automatically:
Analyzes the query plan and resource requirements
Allocates the right amount of compute from the shared pool
Routes the query to available resources
Scales compute up or down based on actual needs
Think of it like switching from buying dedicated servers to using serverless functions – you stop worrying about infrastructure and focus on your workloads.

Figure 1: With Adaptive Warehouses, customers still interact with named warehouses, but under the hood, each warehouse is simply a pointer to a shared compute pool within the account. Queries are automatically routed to appropriately sized compute clusters based on their resource needs and availability.
From Many Settings to Just Two
Snowflake’s standard warehouses require configuring multiple parameters:
Warehouse size
Minimum and maximum cluster count
Scaling policy (Standard or Economy)
Auto-suspend timing
Auto-resume behavior
Query Acceleration
Adaptive Compute replaces all of these with just two settings:
Warehouse Credit Limit: The maximum credits the warehouse can consume per hour. This acts as your primary control lever, determining how many concurrent queries can run based on their compute requirements. When the warehouse reaches its credit limit, additional queries are queued until resources become available.
Target Statement Size (temporary): An optional hint about your expected query sizes. Currently, Adaptive Compute only supports scaling down for smaller queries, and this setting defines the maximum target size. Note that Snowflake intends to deprecate this setting once Adaptive Compute’s autoscaling capabilities mature[1], so don’t build processes around it.

Figure 2: Adaptive Compute reduces configuration complexity by replacing multiple tuning settings with just two controls: a Warehouse Credit Limit and an optional Target Statement Size.
If you convert a standard warehouse to Adaptive, Snowflake sets the initial Warehouse Credit Limit based on the formula: Warehouse Credit Limit = Current Warehouse Size Credits × Max Cluster Count.
It also sets the Target Statement Size equal to the original warehouse size.
For example, if you convert a Large warehouse (8 credits/hour) with max_clusters=4 to Adaptive, you get:
Warehouse Credit Limit: 32 credits/hour (8 credits × 4 clusters)
Target Statement Size: Large
Your Adaptive warehouse can then concurrently run queries totaling up to 32 credits per hour; for example, four Large queries, sixteen Small queries, or any combination fitting within the credit limit.
Where Adaptive Compute Delivers
Simplified Infrastructure Management
Adaptive Compute removes much of the manual setup required to manage Snowflake warehouses, freeing up data teams to concentrate on driving business outcomes and delivering innovation. This hands-off model is especially beneficial for platform teams managing large fleets of warehouses, and less technical users who don’t want to think about warehouse tuning.
Smarter Resource Allocation
Because Snowflake's optimizer has access to detailed query plan metadata (e.g., estimated row counts, join strategies, data volumes), it can predict resource needs more accurately than external tools. Assigning just enough CPU and memory per query also reduces the likelihood of over-provisioning.
Example scenario: Two very different queries are submitted to the same Adaptive Warehouse simultaneously:
| Query | Description | Predicted Compute Needs |
| A | Complex 5-way join with 100M rows | Gets Large-sized compute |
| B | Simple filter on 1000 rows | Gets X-Small-sized compute |
As shown in the table, Adaptive Compute predicts greater compute needs for the Query A (the heavier query) than Query B (the simpler query).
Seamless Conversion from Standard Warehouses
Converting to Adaptive Compute is simple and requires no downtime:
ALTER WAREHOUSE my_warehouse SET TYPE = 'ADAPTIVE';
Running queries complete on the old compute while new queries immediately use adaptive resources. There’s no need to update connection strings, modify scripts, or coordinate downtime windows.
Solving Warehouse Sprawl
A common issue is warehouse sprawl, where companies create separate warehouses for different teams, workload types, or usage patterns. For example, a marketing team might operate five different warehouses:
MARKETING_REPORTS_L(idle 22 hours/day)MARKETING_ETL_XL(runs 2 hours nightly)MARKETING_DASHBOARD_L(idle 20 hours/day)MARKETING_ADHOC_M(sporadic usage)MARKETING_TEST_XS(barely used)
The Problem:
Managing many separate warehouses leads to unnecessary costs due to idle compute time and minimum billing increments. Even quick 5-second queries incur charges for a full minute of compute. Across hundreds of warehouses, this adds up to significant wasted spend each month.
The Adaptive Solution:
With Adaptive Compute, the marketing team can convert each of their five warehouses to Adaptive, and still maintain the same warehouse names for accounting purposes. The shared compute pool ensures resources are available when needed without incurring idle time charges across five warehouses.
Critical Unknowns: What's Still Unclear
While Adaptive Compute offers clear operational benefits, it’s still in private preview and several important details remain unclear. And these details matter, especially for organizations under tight cost or performance SLAs.
Limited Cost Control Mechanisms
Adaptive Compute optimizes for performance and simplicity, not cost reduction. If Target Statement Size is deprecated as planned[1], you'll have only one lever: the Warehouse Credit Limit. Without any settings to guide compute size per query, cost-saving strategies like pushing low-priority workloads to smaller compute are no longer possible.
Consider this scenario: Your team runs a daily report that takes 2 minutes on Small compute (2 credits/hour = 0.067 credits) or 1.5 minutes on Medium compute (4 credits/hour = 0.10 credits).
With standard warehouses, your team can choose Small to save 33% on credits, but Adaptive Compute might decide on Medium due to the speed improvement, increasing your spend regardless of your priorities.
What you lose:
Ability to force non-critical workloads onto smaller compute to save money (e.g., running non-critical reports on X-Small warehouses)
Option to set aggressive auto-suspend for development warehouses (e.g., setting 1-minute auto-suspend for ad-hoc warehouses)
Control over running specific workloads on larger warehouses when deadlines require it
Cache Behavior Uncertainty
Snowflake’s local disk cache can significantly boost query performance, with warm-cache queries often running 5–10x faster than cold ones. Standard warehouses with longer auto-suspend settings are more likely to retain this cache between queries. But with Adaptive's shared compute model, cache behavior becomes unpredictable, potentially impacting both performance and costs.
Why this matters:
Dashboard queries that typically benefit from warm cache might see inconsistent performance
ETL pipelines that read the same base tables repeatedly could lose optimization opportunities
Cost implications if queries that previously hit cache now require full table scans
Monitoring and Debugging Challenges
With standard warehouses, you can directly observe and control which warehouse a query runs on. With Adaptive Compute, the routing decisions happen behind the scenes, and it’s unclear what additional metadata Snowflake will surface around how those routing decisions are made, such as:
What size compute ran each query and how routing logic behaved
Whether the router over‑ or under‑sized compute for specific queries
Whether queries are being queued due to credit limits or resource availability
Impact on Spend
Snowflake's launch materials for Adaptive Compute emphasize ease of use and performance, with no mention of cost savings[2, 3, 4]. This positioning suggests Adaptive Compute isn't designed to reduce spend, which is a critical consideration for organizations with FinOps accountability or tight budget constraints.
How Altimate AI's Auto Tune Delivers Control and Automation
For organizations that want automation without sacrificing cost control, Altimate AI's Warehouse Auto Tune offers a powerful alternative. It brings intelligent optimization to your existing standard warehouses to optimize size, idle time, and cluster configuration while providing even finer-grained control over speed versus savings.

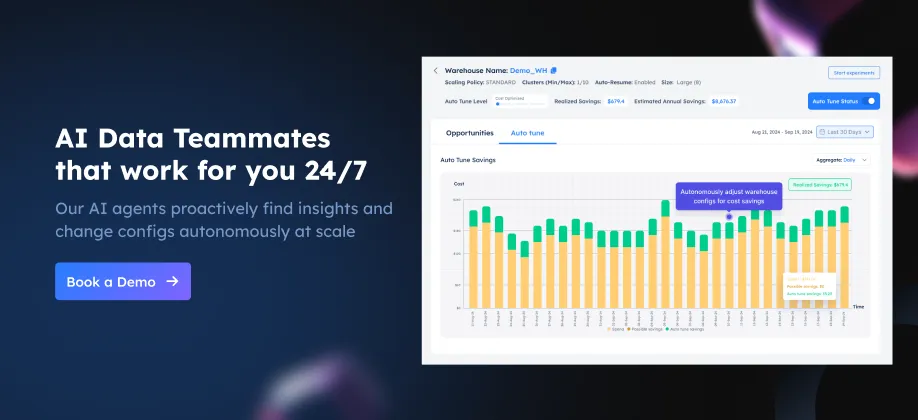
Figure 3: Daily cost breakdown showing Auto Tune savings over time. Each bar displays actual spend (yellow) and realized savings (green) from warehouse suspension, scaling, and sizing optimizations. On July 23, 2025, Auto Tune saved between $34.85 and $45.38, with most savings from Warehouse Suspension and Scaling. Total realized savings during the selected period exceeded $1.1K.
Proactive Suspension and Cluster Scaling
Auto Tune minimizes idle time by scaling back clusters and suspending warehouses before Snowflake's native auto-suspend triggers. It continuously monitors activity and proactively reduces compute allocation during quiet periods.
Predictive Workload-Based Resizing
Auto Tune doesn't just react to current load – it predicts upcoming demand based on your historical workload patterns to determine when warehouses can be safely downsized without impacting performance.
How it works in practice:
Let's say you have a Large warehouse that processes heavy ETL jobs from 2-6 AM but runs mostly small queries the rest of the day. Auto Tune identifies this workload pattern and automatically:
Maintains Large size during the 2-6 AM ETL window
Downsizes to Medium during low-demand periods
Returns to Large before the next ETL window
Granular Performance Safeguards
Auto Tune provides multiple mechanisms to protect critical workloads while optimizing costs:
1. Custom Schedule Blocks Custom schedule blocks define specific time windows where warehouses must maintain a certain size. Examples:
Weekdays 9-10 AM: Keep
EXECUTIVE_DASHBOARD_WH_XLat default size X-Large for C-suite daily reviews to ensure performanceSunday 2-5 AM: Keep
ARCHIVE_ETL_WHdownsized to Small while reprocessing past months of data to reduce costs
2. Real-Time Backoff Configuration
Set performance thresholds that automatically reverse downsizing decisions if query latency or queue times exceed acceptable levels. When triggered, the system reverts to default size and pauses auto-resizing for one hour.
Example Backoff Configurations for Different Workload Types:
| Workload Type | Latency Threshold | Queue Threshold | Rationale |
| Customer-facing dashboards | 120% | 125% | Minimal tolerance for delays |
| Internal analytics | 150% | 150% | Balanced cost/performance |
| Batch ETL jobs | 180% | 170% | Cost savings prioritized |
Transparency and Control Over Decisions
Auto Tune provides full visibility into every optimization decision:
Daily/weekly/monthly spend trends with savings clearly separated by agent
Detailed logs explaining why each resizing decision was made
Calendar view of all scheduled and completed optimization windows

Figure 4: Auto Tune history log showing recent warehouse actions taken. The agents resized warehouses dynamically based on query patterns, including downsizing from Large to Medium size to reduce cost without impacting performance.
Warehouse Eligibility and Smart Targeting
Auto Tune automatically evaluates each warehouse to determine if it's a good candidate for resizing optimization. Eligible warehouses typically have:
Periods of low utilization with mainly small queries
Predictable daily or weekly patterns
Meaningful compute spend to optimize
This ensures resizing agents only focus on warehouses where they can deliver real value and help cut costs.
Making the Right Choice: Adaptive vs. Auto Tune
Here are a few pointers for choosing the right solution.
Choose Adaptive Compute When:
Simplicity is paramount: You want to eliminate warehouse management entirely
Workloads are unpredictable: Highly variable query patterns make sizing difficult
Performance matters most: You're willing to pay more for consistent speed
You're consolidating many underutilized warehouses: The reduction in idle time offsets other costs
Choose Auto Tune When:
Cost control is critical: You have specific spending targets to hit
Workloads follow patterns: Your queries have predictable daily/weekly cycles
You need granular control: Different workloads require different cost/performance tradeoffs
You want transparency: Detailed visibility into optimization decisions and savings
Hybrid Approach
Many organizations will benefit from using both solutions strategically. For example:
Convert your
DATA_SCIENCE_SANDBOXwarehouse to Adaptive Compute since data scientists run unpredictable queries at random timesKeep your
PRODUCTION_ETLwarehouse on standard with Auto Tune, reducing spend through predictable downsizing during known quiet periodsUse Adaptive for all development/test warehouses to eliminate idle charges
Apply Auto Tune to customer-facing warehouses where you need cost control with performance guarantees
Final Thoughts
Snowflake's Adaptive Compute and Altimate AI's Auto Tune represent two philosophies for warehouse optimization: total simplicity versus intelligent control. Adaptive Compute eliminates management overhead but sacrifices cost optimization levers. Auto Tune maintains the flexibility of standard warehouses while adding automation that typically reduces costs by 10-20%.
Start by analyzing your warehouse utilization patterns and cost targets. If predictable savings matter more than operational simplicity, Auto Tune is likely your best choice. If you're drowning in warehouse management complexity and can accept higher costs for simplicity, Adaptive Compute offers compelling benefits. For most organizations, a hybrid approach will deliver the best of both worlds.
If your team already has tools in place for analyzing warehouse usage patterns, monitoring cost targets, and automating warehouse optimization, you're all set. If not, we can help you with the analysis, optimization, and choosing between Adaptive and standard warehouses based on your needs. Reach out to us for a no-cost POC.
References
What's New: Faster Insights with Snowflake Standard Warehouse - Gen2 and Adaptive Compute. Snowflake Summit 2025 Session Catalog. June 3, 2025.
Snowflake Unveils Next Wave of Compute Innovations For Faster, More Efficient Warehouses and AI-Driven Data Governance. Snowflake press release, June 3, 2025.
Introducing Even Easier-to-Use Snowflake Adaptive Compute with Better Price/Performance. Snowflake Blog, June 3, 2025.
How Snowflake’s Adaptive Warehouse Is Revolutionizing Data Operations at Pfizer. Snowflake Builders Blog on Medium; Matt Massey, June 3, 2025.
Deliver more performance and cost savings with Altimate AI's cutting-edge AI teammates. These intelligent teammates come pre-loaded with the insights discussed in this article, enabling you to implement our recommendations across warehouses, tables, and millions of queries effortlessly. Ready to see it in action? Request a recorded demo by sending us a chat message) and discover how AI teammates can transform your data teams.
Subscribe to my newsletter
Read articles from Dana Van Aken directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Dana Van Aken
Dana Van Aken
I hold a Ph.D. in Computer Science from Carnegie Mellon University, where I was a member of the Database Group. My research interests lie at the intersection of database management systems and machine learning, with a focus on autonomous databases and ML for systems. In 2025, I joined Altimate AI as the Head of Research, a startup redefining data operations with a cutting-edge solution for preventing data problems before they occur, from the moment data is generated to its use in analytics and machine learning.