vLLM ? The Simple Guide for Non-Devs and Curious Minds
 Raghul M
Raghul M
Large language models (LLMs) like ChatGPT, LLaMA, and Mistral are incredibly powerful, but they're also resource-hungry. They need lots of memory and processing power to respond to a single prompt, let alone handle multiple users. So how do you run a big LLM efficiently especially if you want to host it yourself ?
Thats where vLLM plays an vital role an open-source engine designed to serve large language models efficiently, quickly, and at scale.
This blog is your plain-layman term guide to understanding what vLLM is, how it works, and why it's a game-changer for running LLMs.
What Is vLLM (And Why Should You Care)?
Imagine you want to build your own chatbot, just like ChatGPT, but hosted on your own machine or cloud. You need it to:
Handle long conversations
Support multiple users at once
Be fast and responsive
vLLM ("Virtualized LLM") is a backend engine that makes this possible. It works under the hood to serve models like LLaMA , Qwen and Mistral while keeping GPU memory usage efficient and response times low.
Let’s break down the main ideas behind vLLM in simple terms:
1. Tokens
LLMs don’t understand words directly. They split your input into smaller units called tokens. For example, "chatbot" might become "chat" + "bot".
2. Attention
When the model generates the next word, it looks back at previous tokens and decides which ones matter most. This is called attention.
3. KV (Key-Value) Cache
As the model processes input, it saves information about each token from past querys into a memory bank. This is the KV cache, which lets the model remember the conversation.
4. PagedAttention (The Magic)
Normally, the KV cache grows as the conversation gets longer. That eats up GPU memory fast. PagedAttention solves this by:
Storing memory in chunks (called pages)
Swapping pages in and out of GPU as needed
It’s like working at a small desk: you keep only the important notes on your desk and file away the rest, pulling them out only when you need them.
5. vLLM Engine
This is the smart part of the system. It:
Loads the model
Tokenizes the input
Manages the KV cache using PagedAttention
Streams the output
All while keeping GPU usage low and performance high.
6. OpenAI-Compatible API
vLLM exposes an API that looks exactly like OpenAI's API Endpoints .
Refer this : https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html
Why vLLM Matters
Here’s why developers and organizations are excited about vLLM:
Fast - Generates responses quickly, even for long chats.
Scalable - Can handle multiple users at once.
Memory-efficient - Thanks to PagedAttention.
Easy to integrate - Compatible with OpenAI-style APIs.
If you want to build apps like ChatGPT, or host your own LLMs securely, vLLM is the engine you want.
A Simple Chatbot Flow with vLLM
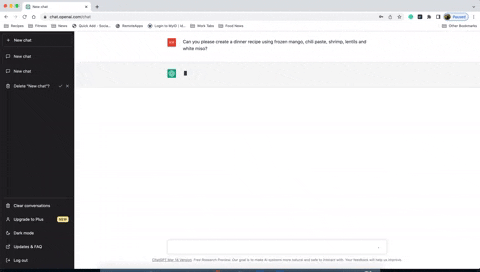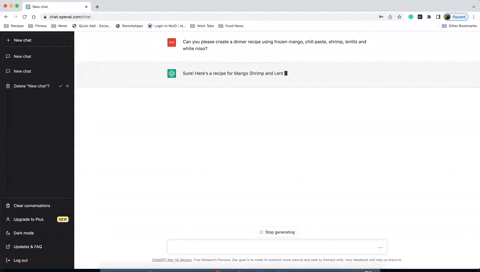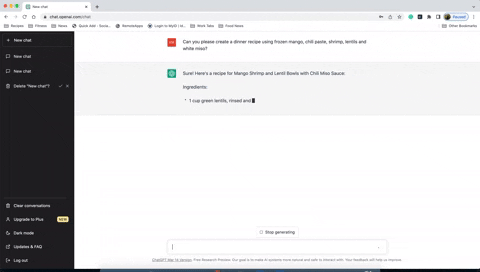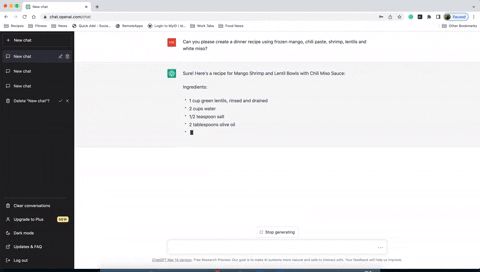
User asks: "Tell me a joke."
Input gets tokenized.
Model checks previous tokens (if any) using attention.
vLLM loads needed memory pages.
Response is generated and streamed back.
And it does this fast, even if you’re chatting with multiple users.
Conclusion

vLLM = fast, memory-efficient LLM serving engine with an OpenAI-like API.
You now understand:
What attention, KV cache, and PagedAttention mean
Why vLLM is better than regular model serving
How it fits into chatbot pipelines
If you're building with LLMs and want speed, scale, and control, vLLM is 100% worth checking out.
Connect with me on Linkedin: Raghul M
Subscribe to my newsletter
Read articles from Raghul M directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Raghul M
Raghul M
I'm the founder of CareerPod, a Software Quality Engineer at Red Hat, Python Developer, Cloud & DevOps Enthusiast, AI/ML Advocate, and Tech Enthusiast. I enjoy building projects, sharing valuable tips for new programmers, and connecting with the tech community. Check out my blog at Tech Journal.