What Makes Apache Iceberg Different: Hidden Power of Table Formats
 Sriram Krishnan
Sriram KrishnanApache Iceberg is more than just a table format — it’s a metadata engine that powers scalable, versioned, and high-performance analytics on data lakes. Unlike older table formats like Hive, which rely on directory structures and rigid schemas, Iceberg introduces a layered architecture designed for cloud-native environments. It supports atomic operations, time travel, schema evolution, and efficient file pruning — all while enabling compatibility with modern compute engines like Spark, Trino, Flink, and Dremio.
In this post, we’ll unpack the internals of an Iceberg table and explore the architectural innovations that make it truly different — including catalogs, metadata layers, manifest structures, and indexing via Puffin files.
Iceberg Architecture: The Basics
Apache Iceberg is designed for cloud-native, large-scale analytics. It brings database-like features to data lakes by structuring how table data and metadata are managed. Unlike older formats that rely heavily on file naming and directory structure (like Hive), Iceberg uses a clear metadata tree to support atomic commits, time travel, schema evolution, and efficient queries.
At a high level, Iceberg separates the physical data storage—in formats like Parquet, ORC, and Avro—from the logical table structure defined in its metadata. This clear separation allows for powerful query optimizations while ensuring seamless interoperability with engines such as Spark, Trino, Flink, and Dremio.
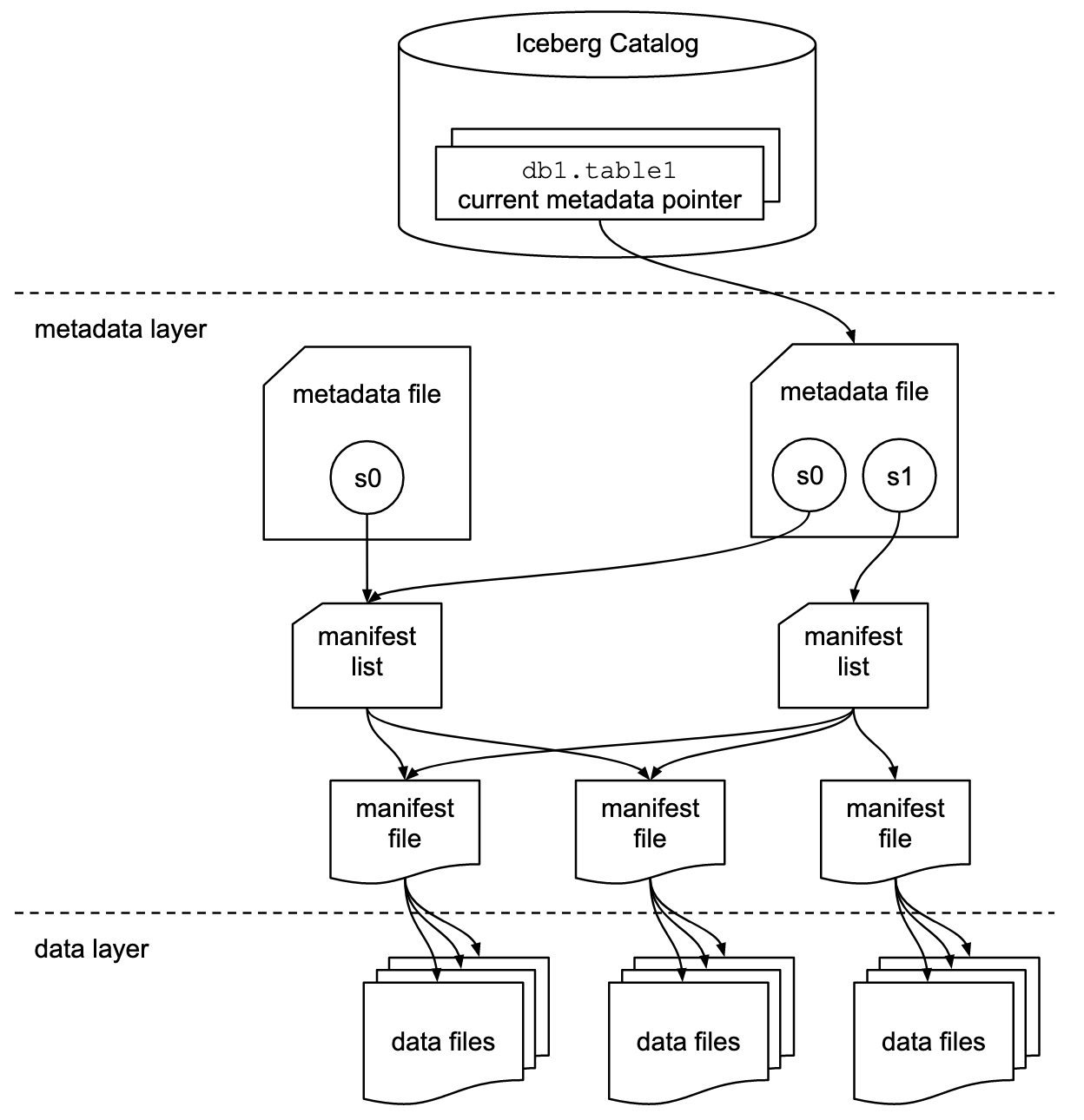
Iceberg Catalogs: The Entry Point
Before any Iceberg table is read or written, a catalog comes into play. An Iceberg catalog is responsible for tracking the location of tables and resolving them to their metadata files.
There are multiple types of catalogs supported:
Hive Catalog: Stores table metadata pointers in Hive Metastore
Nessie Catalog: Supports Git-like branching for data tables
REST Catalog: Decouples metadata management via HTTP APIs
Glue Catalog: Uses AWS Glue Data Catalog as the backend
Jdbc Catalog: Stores references in an RDBMS like PostgreSQL or MySQL
What the Catalog Does:
Maps table names to
metadata.jsonlocationsCoordinates metadata updates and transactions
Supports namespace and table-level operations (like
DROP,RENAME,LIST)
Why It Matters:
The catalog is what makes Iceberg feel database-like even though it’s file-based under the hood and enables ACID guarantees. It ensures that:
Multiple engines can read/write the same table
Metadata is versioned and discoverable
Changes are atomic and consistent
Iceberg's Metadata Hierarchy: An Overview
Iceberg organizes table data and metadata in a multi-layered structure:
This hierarchy enables Iceberg to efficiently track, version, and query large-scale datasets.
📁 metadata.json (table definition)
├── 🧾 manifest-list (points to manifest files)
│ └── 📃 manifest-file (lists actual data files)
│ └── 📁 parquet files (data)
└── 🧠 puffin files (optional indexes)
1. The Metadata File: The Control Tower
The metadata.json file is the single source of truth for the table. It stores:
Schema: Column definitions with IDs and types
Partition specs: E.g.,
created_ts_dayderived from timestampSnapshots: Each version of the table
Manifest list location: For each snapshot
Example:
"fields": [
{ "id": 1, "name": "order_id", "type": "long" },
{ "id": 2, "name": "customer_id", "type": "long" },
{ "id": 5, "name": "created_ts", "type": "timestamptz" }
]
It allows time-travel, rollback, and efficient change tracking across table versions.
2. Manifest Lists: The Index of Indexes
Each snapshot points to a manifest list file. It contains:
Paths to manifest files
Snapshot ID and sequence numbers
Row and file counts
Partition bounds
Example Entry:
"manifest_path": "s3://.../a5969634...-m0.avro",
"added_data_files_count": 2,
"added_rows_count": 2
This list helps Iceberg engines quickly determine what changed in a given snapshot.
3. Manifest Files: Describing Actual Data Files
A manifest file contains the metadata for a group of data files (like Parquet).
Each entry describes:
File path
Partition (e.g.,
created_ts_day = 2023-03-21)Record count, file size
Column-level stats: min, max, null count, etc.
Example:
"data_file": {
"file_path": "s3://.../orders/data/created_ts_day=2023-03-21/00000-11-...parquet",
"record_count": 1,
"file_size_in_bytes": 1574,
"column_sizes": { ... },
"value_counts": { ... },
"lower_bounds": { ... },
"upper_bounds": { ... }
}
These stats enable predicate pushdown and file pruning during queries.
4. Puffin Files: Sidecar Indexes for Rocket Speed
Puffin files are optional index sidecars that store advanced indexes like:
Bloom filters
Value histograms
Column-level zone maps
They accelerate queries by helping Iceberg avoid scanning irrelevant files — even before checking manifest files.
Sample Puffin (Conceptual):
{
"type": "puffin",
"metadata_type": "bloom_filter",
"column_id": 2,
"indexed_files": [
{
"file_path": ".../2023-03-21/00000-11-...parquet",
"may_contain_values": [12345, 98765]
}
]
}
Think of Puffin as the index card drawer at the library’s front desk — helping you skip whole shelves.
Query Flow: Iceberg in Action
Query:
SELECT * FROM orders WHERE customer_id = 98765;
Iceberg reads
metadata.json→ gets latest snapshotLoads manifest list → finds relevant manifest files
Reads manifest files → checks min/max stats
Optionally uses Puffin → skips files that definitely don’t match
Reads only relevant Parquet files
Final Thoughts
Iceberg isn't just a new file format — it's a metadata engine for your data lake. With manifest files, snapshot versioning, and sidecar indexing via Puffin, Iceberg empowers modern analytics platforms to handle large, evolving datasets with speed and precision. By separating metadata from data and building rich structures around it, Iceberg delivers the hidden power that makes the lakehouse fast, flexible, and future-proof.
Subscribe to my newsletter
Read articles from Sriram Krishnan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sriram Krishnan
Sriram Krishnan
Sharing lessons, tools & patterns to build scalable, modern data platforms —one post at a time.