Inferencing Rag
 saud javaid
saud javaidTable of contents
- The Context Problem in RAG
- The Art of the Right Query: Not Too Abstract, Not Too Literal
- Multi-Query Retrieval (MQR): Asking Better, Not Just Once
- Why This Works
- Multi-Query in LangChain — Real Pipeline
- Step Further: Smarter Merging with Reciprocal Rank Fusion (RRF)
- That’s Where RRF Comes In
- In a RAG Pipeline
- section 2) step further Why Query Decomposition?
- Intuition: A 3D Representation
- Implementation: Step-by-Step Breakdown from LangChain’s Notebook (Part 7)
- Recursive Answering Approach
- Answering Individually + Synthesizing
- Papers to Dive Deeper

The Context Problem in RAG
Ever built a Retrieval-Augmented Generation (RAG) system and thought,
“Why is the answer so shallow? I KNOW the context is in the docs…”
Welcome to the context bottleneck. Even with high-quality documents and embeddings, standard retrieval often grabs just a few chunks based on surface-level similarity. This leads to missed context, weak grounding, or worse — hallucinations.
Let’s say you ask:
pythonCopyEditquery = "How do LLM agents break down tasks?"
Your naive retriever might do:
pythonCopyEditretriever = vectorstore.as_retriever()
docs = retriever.get_relevant_documents(query)
And boom — you get 3 chunks that kinda match “LLM” or “tasks”, but totally miss the rich explanation on task decomposition strategies. Why?
Because standard vector similarity is distance-based and query-blind. It doesn’t understand what you’re really asking.
So how do we fix this?
That’s where multi-query, decomposition, ranking, routing, and HyDE come in. This post is all about those smarter strategies — turning a basic retriever into an intelligent information hunter.
The Art of the Right Query: Not Too Abstract, Not Too Literal
Most users don’t know exactly how to ask what they really mean — their input is often vague, ambiguous, or even overly verbose. If your retrieval system is built on shallow matching (like basic vector similarity), it’ll return equally vague or irrelevant answers.
Classic GIGO: Garbage in, garbage out.
That’s why query translation matters.
What is Query Translation?
It’s the process of transforming the user’s messy, unclear input into a version that:
better reflects what they’re actually looking for,
uses terms closer to how the knowledge is stored in your corpus,
and balances between being too abstract or too specific.
Abstract vs Less Abstract — A Simple Analogy
Let’s say you want your brother to bring you water.
Abstract query:
“Water.”
(What kind? How much? Tap or mineral? Hot or cold?)Less abstract (too detailed):
“Bring me slightly warm mineral water in a glass, not a mug, no tap water, put a plate under the glass so it doesn’t leave a mark on the table.”
Now in both cases, you’re thinking about the same need, but expressing it differently.
LLMs and retrievers face the same dilemma. If a query is:
Too abstract, it lacks precision for retrieval (you might match a thousand irrelevant “water” documents).
Too literal or verbose, it introduces noise — unnecessary details that might confuse the embedding or make similarity matching worse.
The best retrieval-oriented query lies somewhere in the middle — rich enough to contain intent, but focused enough to be retrievable.
see the image below to how a better understanding this is where all the techniques are applied to the query
dont worry about rag fusion multi query we will talk about them soon

In LLM Terms: Why This Matters
Large language models (LLMs) are great at language, but the retrieval system feeding them must give the right documents. Query translation helps bridge the gap between:
How users speak, and
How information is stored.
That’s why advanced RAG setups use techniques like:
Multi-query generation (generate multiple perspectives)
HyDE (generate hypothetical answers and embed them)
Query decomposition (break one vague query into sub-questions)
Semantic routing (send parts of a query to different retrievers)
All of this starts from the same principle:
User queries aren’t always useful as-is. You need to translate them into something the system can actually retrieve from.
Multi-Query Retrieval (MQR): Asking Better, Not Just Once
When you ask a question like:
“How do LLM agents decompose tasks?”
You’re hoping your retrieval system finds the right chunk of text buried somewhere in your document store.
But here's the problem:
Your documents may never say exactly that.
They might say:
“Agents can break a task into subtasks…”
“Decomposing multi-step goals is crucial…”
“Hierarchical planning enables LLMs to reason in steps…”
Your query and the document might mean the same thing — but if the wording doesn’t match, your retriever might just shrug and miss it completely.
This is the vocabulary mismatch problem in vector search.
Enter Multi-Query Retrieval (MQR) — instead of relying on one user query, we ask the LLM to generate several semantically diverse versions of it.
so we ask the llm to generate a number of related queires fed into the llm take out the chunks merge them fuse them and give a ouput
This increases the chances that at least one version hits the right documents.
Why This Works
LLMs are great at generating diverse rewrites that capture different ways of saying the same thing.
Your vector DB stays the same, but you expand the ways you search it.
the problem from a simple rag where we just index retrive the chunks is context we do use overlap property of loader mehtod but it is needle in the ocean to improve the context we use these methods
The results from all queries are merged, deduplicated, and fed into the final answer generation.
wihtout a diagram you cant understand

This is the fan out architecture where process are working in parallel and then converge to a single one so that we give a single and a better output just like in you tube when you upload a video the video encoding starts happeing your video is encoing for 1080 and 144p at parallel and then merge
for understanding the fan out architecture i will highly recommend to check out this repo where I implement the same system design in a youtube clone
Multi-Query in LangChain — Real Pipeline
Step 1: Prompt for Generating Multi-Queries
pythonCopyEditfrom langchain.prompts import ChatPromptTemplate
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines.
Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
This system prompt is clever. It asks the LLM to:
Understand the intent of the user question.
Generate five alternative versions from different angles.
Keep them distinct and retrievable.
Step 2: Chain the Prompt to LLM
pythonCopyEditfrom langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
generate_queries = (
prompt_perspectives
| ChatOpenAI(temperature=0)
| StrOutputParser()
| (lambda x: x.split("\n"))
)
This pipeline does four things:
Sends your question to the prompt template.
Runs it through the ChatOpenAI model.
Parses the text output to a string.
Splits it line-by-line to get a list of 5 questions.
Step 3: Semantic Search on All Queries
pythonCopyEditretrieval_chain = generate_queries | retriever.map() | get_unique_union
Here:
retriever.map()runs semantic retrieval for each generated query.get_unique_unionflattens and deduplicates all the documents across those queries.
Helper function:
pythonCopyEditfrom langchain.load import dumps, loads
def get_unique_union(documents: list[list]):
""" Unique union of retrieved docs """
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
unique_docs = list(set(flattened_docs))
return [loads(doc) for doc in unique_docs]
This step is crucial — otherwise, multiple queries might retrieve the same chunk multiple times. The dumps/loads trick converts documents to JSON for proper set-based deduplication.
Step 4: Final RAG Prompt
pythonCopyEditfrom langchain.prompts import ChatPromptTemplate
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
We now merge:
The user's original question, and
The merged retrieved documents, into one prompt.
Step 5: Final Chain
pythonCopyEditfrom operator import itemgetter
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
llm = ChatOpenAI(temperature=0)
final_rag_chain = (
{
"context": retrieval_chain,
"question": itemgetter("question")
}
| prompt
| llm
| StrOutputParser()
)
Now this chain:
Runs multi-query → retrieval → deduplication → prompt → answer generation,
All in a clean, composable, declarative LangChain pipeline.
You invoke it like this:
pythonCopyEditquestion = "What is task decomposition for LLM agents?"
final_rag_chain.invoke({"question": quesWhy Multi-Query Works
Multi-Query Retrieval gives your retriever multiple chances to understand the user's intent. It's like searching Google using five variations of your question and picking the best results from all of them.
One user query → many generated queries → many document results → deduplicated → better context → be
Step Further: Smarter Merging with Reciprocal Rank Fusion (RRF)
reciprocate rank fusion this is where we merge the documents from different queries but how do we merge let see a diagram

Okay, so we’ve generated multiple queries using multi-query retrieval.
Now what?

Each query returns a list of documents from the vector DB. These results may overlap, conflict, or vary in ranking.
Let’s say:
| Query | Top Results |
| Q1 | Yellow, Blue, Red |
| Q2 | Blue, Red, Green |
| Q3 | Blue, Yellow, Red |
Now… how do we merge these result lists in a meaningful way?
Do we just concat them all?
Do we pick the top 3 from each?
That’d be noisy, repetitive, and could miss what’s truly important across all queries.
That’s Where RRF Comes In
Reciprocal Rank Fusion (RRF) is a lightweight, powerful ranking method designed exactly for this situation.
RRF takes multiple ranked lists (from different queries), and assigns a score to each document based on how high it appears in those lists.
Formula:
For each document d, from each list Lᵢ where it appears at rank rᵢ, we compute:
CopyEditRRF_score(d) = Σ (1 / (k + rᵢ))
Where k is a small constant (usually 60), and rᵢ is the position of the doc in the list.
The higher a document appears across multiple queries, the higher its RRF score. That’s what we want — documents that are relevant in multiple perspectives.
Example
Imagine this:
Blue appears:
2nd in Q1
1st in Q2
1st in Q3
Yellow appears:
1st in Q1
2nd in Q3
Red appears:
3rd in Q1
2nd in Q2
3rd in Q3
Now let’s compute approximate RRF scores (assuming k = 60):
makefileCopyEditBlue: 1/(60+2) + 1/(60+1) + 1/(60+1) ≈ 0.016 + 0.016 + 0.016 = 0.048
Yellow: 1/(60+1) + 1/(60+2) ≈ 0.016 + 0.016 = 0.032
Red: 1/(60+3) + 1/(60+2) + 1/(60+3) ≈ 0.015 + 0.016 + 0.015 = 0.046
Final ranking:
markdownCopyEdit1. 🔵 Blue → 0.048
2. 🔴 Red → 0.046
3. 🟡 Yellow → 0.032
Even though Yellow ranked 1st in one query, Blue won overall by appearing at the top more consistently.
Why Use RRF?
Combines relevance across diverse queries
(from multi-query, decomposition, etc.)Resistant to noise
(a bad ranking in one query doesn’t kill the doc)Doesn’t require learning or tuning
(simple math, no training)Better recall, smarter fusion
(documents relevant across multiple query interpretations float to the top)
In a RAG Pipeline
Here’s how RRF fits in your pipeline:
sqlCopyEdit +-------------+
| User Query |
+-----+------+
|
v
+------------------------+
| Multi-Query Generator |
+--+-----+-----+--------+
| | |
v v v
[Query1] [Query2] [Query3]
| | |
v v v
[Docs1] [Docs2] [Docs3] <-- Vector DB
\ | /
\ | /
+-----------+
| RRF | <-- Merges & re-ranks
+-----------+
|
v
+-------------------+
| Final Context Set |
+--------+----------+
|
v
[Answer Generation]
You can inject your diagram right here — it visually backs up this explanation perfectly.
Multi-query expands your search.
RRF makes that expansion useful, by merging and ranking multiple result lists based on position.
RRF is simple, unsupervised, and powerful.
section 2) step further Why Query Decomposition?
Why Break a Query?
Let’s take a complex real-world query:
"What are the main components of an LLM-powered autonomous agent system?"
It’s packed. A single vector search will struggle to fully understand or retrieve every aspect buried in that question. That’s where query decomposition steps in.
Instead of throwing one big question into the system and hoping for a miracle, we break it down into smaller, focused sub-questions. This helps the retriever get more targeted, high-quality context.
Think of It Like This:
Imagine your original query is:
"Think: Machine Learning"
It sounds short, but it's actually conceptually deep. To understand or explain it better, we might break it into:
What is a machine?
What is learning?
What is machine learning?
Each of these gives us an axis to explore — and together, they give full coverage. It’s like placing 3 points in 3D space: each point captures a slice of the concept, but the full shape emerges when you look at them together.
We apply the same principle to complex LLM queries.
Two Decomposition Strategies
Once we have the sub-questions, there are two ways to use them:
1. Answer Recursively (Sequential)
Each sub-question is answered in order.
The answer to one can influence the next — useful when the questions build upon each other.
Like stacking blocks to build the full picture.
2. Answer Individually, Then Synthesize
We answer each sub-question separately.
Then we combine the results into one clean, synthesized response.
Like solving each puzzle piece, then assembling the whole.
Intuition: A 3D Representation
Imagine the user asks:
"Explain machine learning."
A single query could land you somewhere in the space of documents about machine learning. But to give a full answer, the system might need documents about:
consider it as machine as a point on a 3d plot same learning same machine learing as a point on 3d plot we want to combine all the three dots to have more context otherwise what is machine learning is the query it will directly go to that query and will be poor in context
"Machine"
"Learning"
The combination of both
Learning
/
/
/
Machine -----/---- Machine Learning (target)
Each axis represents a core sub-concept. The goal is to retrieve from these axis-aligned concepts, then combine the knowledge.
Implementation: Step-by-Step Breakdown from LangChain’s Notebook (Part 7)
Step 1: Create the Decomposition Prompt
from langchain.prompts import ChatPromptTemplate
# Sub-question generator prompt
template = """You are a helpful assistant that generates multiple sub-questions related to an input question.\n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answered in isolation.\n
Generate multiple search queries related to: {question}\nOutput (3 queries):"""
prompt_decomposition = ChatPromptTemplate.from_template(template)
Step 2: Run LLM + Split
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(temperature=0)
# Create chain
generate_queries_decomposition = (
prompt_decomposition
| llm
| StrOutputParser()
| (lambda x: x.split("\n"))
)
# User query
question = "What are the main components of an LLM-powered autonomous agent system?"
questions = generate_queries_decomposition.invoke({"question": question})
Output:
[
'1. What is LLM technology and how does it work in autonomous agent systems?',
'2. What are the specific components that make up an LLM-powered autonomous agent system?',
'3. How do the main components ... interact to enable autonomous functionality?'
]
Recursive Answering Approach
Now, we answer each sub-question one-by-one and feed the Q+A pairs back into the next round.
lets see the image and then we will implement the same architecture
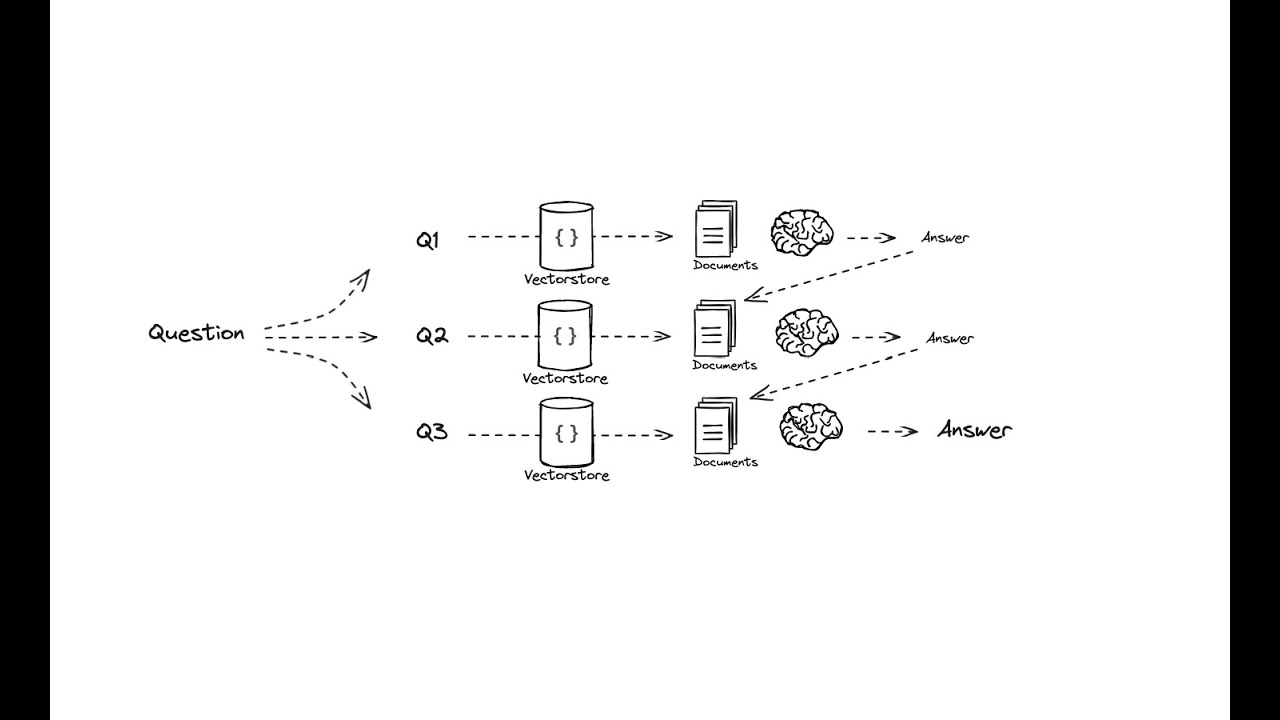
from operator import itemgetter
# Q+A formatting
q_a_pairs = ""
def format_qa_pair(question, answer):
return f"Question: {question}\nAnswer: {answer}\n"
# Loop through sub-questions
for q in questions:
rag_chain = (
{"context": itemgetter("question") | retriever,
"question": itemgetter("question"),
"q_a_pairs": itemgetter("q_a_pairs")}
| decomposition_prompt
| llm
| StrOutputParser()
)
answer = rag_chain.invoke({"question": q, "q_a_pairs": q_a_pairs})
q_a_pairs += "---\n" + format_qa_pair(q, answer)
Answering Individually + Synthesizing
If you want to each question separately and then combine them:
let see the iamge

from langchain import hub
from langchain_core.runnables import RunnableLambda
prompt_rag = hub.pull("rlm/rag-prompt")
# Wrapper function
def retrieve_and_rag(question, prompt_rag, sub_question_generator_chain):
sub_questions = sub_question_generator_chain.invoke({"question": question})
rag_results = []
for sub_q in sub_questions:
retrieved_docs = retriever.get_relevant_documents(sub_q)
answer = (prompt_rag | llm | StrOutputParser()).invoke({
"context": retrieved_docs,
"question": sub_q
})
rag_results.append(answer)
return rag_results, sub_questions
answers, questions = retrieve_and_rag(question, prompt_rag, generate_queries_decomposition)
Then format the QA pairs and synthesize:
def format_qa_pairs(questions, answers):
return "\n".join(
[f"Question {i+1}: {q}\nAnswer {i+1}: {a}" for i, (q, a) in enumerate(zip(questions, answers))]
)
context = format_qa_pairs(questions, answers)
final_prompt_template = """Here is a set of Q+A pairs:
{context}
Use these to synthesize an answer to the question: {question}
"""
final_rag_chain = (
ChatPromptTemplate.from_template(final_prompt_template)
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"context": context, "question": question})
Papers to Dive Deeper
These methods power deeper RAG logic and show how retrieval + reasoning can work together recursively.
hismethod is not multi-query. In multi-query, we generate parallel variants of the same question.
In query decomposition, we generate logical building blocks that help cover complex concepts completely.
Understanding HyDE Architecture: Hypothetical Document Embeddings
Sometimes, your RAG system doesn’t retrieve good context — not because your query is bad, but because the right documents just don’t exist in your vector DB. This is where HyDE (Hypothetical Document Embeddings) becomes a game-changer.
Instead of searching with the user query directly, we:
Generate a hypothetical answer using an LLM.
Embed that answer.
Use that embedding to search for real documents that are semantically similar to the hypothetical one.
How It Works (Step-by-Step)
Let’s say the user asks:
"How do LLMs learn reasoning chains?"
A HyDE pipeline will:
Pass this query to the LLM with a system prompt like:
You are a helpful assistant. Write a detailed answer to the following question: {question}The LLM generates a hypothetical answer, say:
"LLMs learn reasoning chains by... [detailed explanation]"
We embed this answer with our embedding model.
We do semantic search using this hypothetical answer's embedding.
The real documents retrieved (from vector DB) are more aligned with the answer we want.
Why It’s Better
Bridges abstraction gap between vague queries and detailed content
Often retrieves better-matching documents than using query embeddings alone
Especially powerful for abstract, open-ended, or multi-hop questions
HyDE Architecture Diagram
User Query
|
v
[Generate Hypothetical Answer with LLM]
|
v
[Embed Hypothetical Answer]
|
v
[Semantic Search in Vector DB]
|
v
[Retrieve Real Documents]
|
v
[Pass to RAG for Answer Generation]
Summary of What We Covered
In this blog, we explored multiple advanced techniques to make Retrieval-Augmented Generation (RAG) systems more intelligent and accurate:
Query Translation: Convert vague user queries into more structured ones for better retrieval.
Query Decomposition: Break complex questions into sub-questions and synthesize detailed answers.
Reciprocal Rank Fusion: Combine results from multiple queries using rank-based scoring.
HyDE Architecture: Use a hypothetical answer to guide better document retrieval.
These strategies allow you to go beyond basic RAG and build next-level intelligent assistants that retrieve with purpose.
🔗 Connect With Me
GitHub: github.com/saudjavaid2003
Subscribe to my newsletter
Read articles from saud javaid directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
saud javaid
saud javaid
A developer that dont likes sleeping have a very bore life not much into sports I spent my full day gazing at the laptop screen My skills mern stack next js and Gen ai and making scalable backned