It’s 2025: Your Python Toolkit Should Be More Than Just PyCharm
 Lamri Abdellah Ramdane
Lamri Abdellah RamdaneThe Python ecosystem is expanding rapidly, with new tools emerging constantly. Feeling overwhelmed? Don’t panic.
This article cuts through the noise. We’ll only cover the tools that are true game-changers in 2025, guaranteed to elevate your development experience.

ServBay: Say Goodbye to Tedious Python Environments
Let’s be honest: configuring Python environments is the number one reason beginners get discouraged. Managing conflicts between Python 2.x and Python 3.x can feel like a wrestling match. Even seasoned developers often get bogged down by different Python versions across various projects.
Enter ServBay. Think of it as the ultimate toolbox for developers.
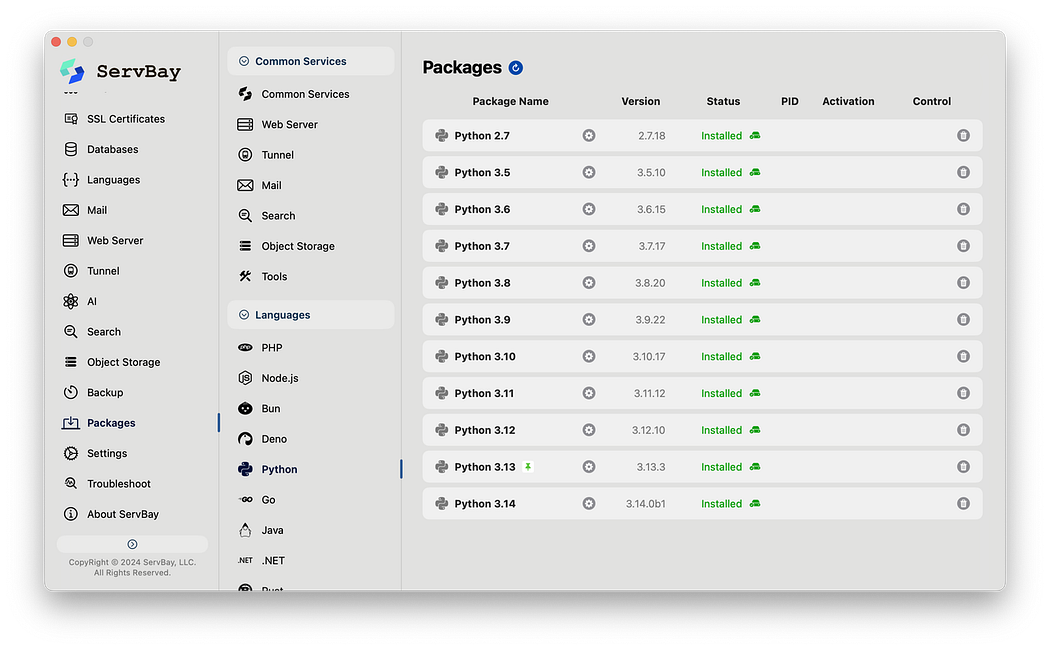
With ServBay, installing any Python version is just a few clicks away. Even better, you can have Python 3.8, 3.10, and 3.12 installed simultaneously on the same machine. They won’t interfere with each other, allowing you to switch between them effortlessly for different projects.
The most critical point: you won’t type a single command.
No more battling compilation errors with pyenv or getting tangled in miniconda's environment configurations. ServBay lets you focus your time on what really matters—writing code. When it comes to setting up a dev environment, anything that takes longer than five minutes is a job for ServBay. And for tasks under five minutes, ServBay still does it better and faster.
Plus, ServBay includes other essential development tools, but we’ll let you discover those for yourself.
Ruff: The Linter and Formatter So Fast, It’s in a League of Its Own
Tired of colleagues pointing out formatting issues in your code? Ruff is here to save the day. It’s written in Rust, and while it has many advantages, one word says it all: fast.

How fast? So fast that you can enable “format on save” in your editor. The moment you press Ctrl+S, your code is already beautifully organized.
For example, the code below has three small issues: a variable typo, an import that isn’t at the top of the file, and an unused module.
Python
data = datas[0]
import collections
A quick check with Ruff instantly and clearly lists all the problems:
Bash
$ ruff check .
ruff.py:1:8: F821 Undefined name `datas`
ruff.py:2:1: E402 Module level import not at top of file
ruff.py:2:8: F401 [*] `collections` imported but unused
Found 3 errors.
[*] 1 potentially fixable with the --fix option.
mypy: Find Bugs Before Your Code Even Runs
There’s a saying: “Dynamic languages are fun until it’s time to refactor.” It’s crude but true. mypy gives your code a "health check" before it ever executes.
For instance, trying to divide a string by 10 is obviously an error.
Python
def process(user: dict[str, str]) -> None:
# mypy will raise a red flag here!
user['name'] / 10
user: dict[str, str] = {'name': 'alpha'}
process(user)
Without running a thing, mypy tells you something is wrong:
Bash
$ mypy --strict mypy_intermediate.py
mypy_fixed.py:2: error: Unsupported operand types for / ("str" and "int")
Found 1 error in 1 file (checked 1 source file)
In large projects, this ability to catch errors early can be a lifesaver.
Pydantic: Stop Using Bare Dictionaries
Still passing dictionaries around? Who knows how many keys they have or what their data types are? Pydantic lets you define your data structures as clearly as you would a standard Python class.

It not only provides clear structure but also automatically validates your data.
Python
import uuid
import pydantic
class User(pydantic.BaseModel):
name: str
id: str | None = None @pydantic.validator('id')
def validate_id(cls, user_id: str) -> str | None:
if user_id is None: return None
try:
# Check if the ID is a valid UUID v4
uuid.UUID(user_id, version=4)
return user_id
except ValueError:
# If not, return None
return None# 'invalid' will be automatically converted to None
users = [ User(name='omega', id='invalid') ]
print(users[0])
See? id='invalid' was automatically validated and set to None. Your code's robustness is instantly improved.
name='omega' id=None
Typer: Building CLIs Was Meant to Be This Simple
Want to add a command-line interface to your script? Forget the boilerplate code of argparse. With Typer, you just write a normal Python function and add type hints to the parameters.

Python
import typer
app = typer.Typer()@app.command()
def main(name: str) -> None:
print(f"Hello {name}")if __name__ == "__main__":
app()
And just like that, a full-featured CLI with its own help documentation (--help) is born. Running it looks like this:
Bash
$ python main.py "World"
Hello World
Rich: Bring Your Terminal Output to Life
Tired of monotonous black-and-white terminal output? Rich can make your terminal vibrant and colorful.

Python
from rich import print
user = {'name': 'omega', 'id': 'invalid'}
# Rich beautifully prints data structures and supports emojis
print(f":wave: Rich Print\nuser: {user}")
The output looks much better than a standard print, doesn’t it?
👋 Rich Print
user: {'name': 'omega', 'id': 'invalid'}
Polars: The ‘Speedster’ for Tabular Data
If you’ve ever processed a slightly large dataset with Pandas, you know the agony of waiting. Polars is a new alternative that is significantly faster than Pandas in many scenarios.
Python
import polars as pl
df = pl.DataFrame({
'date': ['2025-01-01', '2025-01-02', '2025-01-03'],
'sales': [1000, 1200, 950],
'region': ['North', 'South', 'North']
})# Chained operations are clean, clear, and use lazy evaluation for higher performance
query = (
df.lazy()
.with_columns(pl.col("date").str.to_date())
.group_by("region")
.agg(
pl.col("sales").mean().alias("avg_sales"),
pl.col("sales").count().alias("n_days"),
)
)print(query.collect())
The result is crystal clear, and the computation is highly optimized.
shape: (2, 3)
┌────────┬───────────┬────────┐
│ region ┆ avg_sales ┆ n_days │
│ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ u32 │
╞════════╪═══════════╪════════╡
│ North ┆ 975.0 ┆ 2 │
│ South ┆ 1200.0 ┆ 1 │
└────────┴───────────┴────────┘
Pandera: A Quality Inspector for Your Data
Data analysis is 80% data cleaning. Pandera acts as a data quality inspector. You pre-define a data schema, and any non-compliant data is stopped at the door.
Python
import pandera as pa
from pandera.polars import DataFrameSchema, Column
import polars as pl
schema = DataFrameSchema({
"sales": Column(int, checks=[pa.Check.greater_than(0)]),
"region": Column(str, checks=[pa.Check.isin(["North", "South"])]),
})# This DataFrame contains a negative sales value and will fail validation
bad_data = pl.DataFrame({"sales": [-1000, 1200], "region": ["North", "South"]})try:
schema(bad_data)
except pa.errors.SchemaError as err:
print(err) # Pandera tells you exactly what's wrong
This ensures that only clean data enters your core logic, preventing a cascade of downstream problems.
DuckDB: The ‘Pocket Rocket’ for Analytical SQL Queries
Don’t let the name fool you. DuckDB is a super-convenient embedded database, like a SQLite built specifically for data analysis. It can query Parquet and CSV files directly at incredible speeds, using standard SQL syntax. You get the power and convenience of SQL in your Python scripts without needing a heavyweight database server. It’s a dream for rapid data exploration and prototyping.

Python
import duckdb
# (Assuming sales.csv and products.parquet exist)
con = duckdb.connect()
# Directly join two files in different formats using SQL
result = con.execute("""
SELECT s.date, p.name, s.amount
FROM 'sales.csv' s JOIN 'products.parquet' p ON s.product_id = p.product_id
""").df()print(result)
Loguru: Logging Can Be This Hassle-Free
Python’s built-in logging module can be a bit verbose to configure. Loguru simplifies everything.

from loguru import logger
# One line of configuration enables automatic log rotation and compression
logger.add("file.log", rotation="500 MB") logger.info("This is a standard info message.")
logger.warning("Warning! Something happened!")
The output automatically includes the timestamp, level, and other context, making it incredibly straightforward.
2025-01-05 10:30:00.123 | INFO | __main__:<module>:6 - This is a standard info message.
2025-01-05 10:30:00.124 | WARNING | __main__:<module>:7 - Warning! Something happened!
Marimo: The Next-Generation Python Notebook
Jupyter is great, but it has some long-standing issues: messy execution order can lead to a chaotic state, and version controlling .ipynb files is a nightmare. Marimo aims to solve these problems. Its files are pure .py scripts, making them Git-friendly. It's also reactive: change a variable, and every cell that depends on it updates automatically.

Summary
To level up your Python development in 2025, try this toolset:
Environment Management: Use ServBay for effortless, mouse-driven setup.
Code Quality: Ruff + mypy for speed and stability.
Data Definition: Pydantic to keep your data structures sane.
Tool Development: Typer for CLIs, Rich for beautiful output.
Data Processing: Polars for speed, Pandera for quality, and DuckDB for flexible queries.
Daily Helpers: Loguru for simplified logging, Marimo for a new notebook experience.
Integrate these tools into your workflow, and you’ll discover just how enjoyable writing Python can be!
Subscribe to my newsletter
Read articles from Lamri Abdellah Ramdane directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by